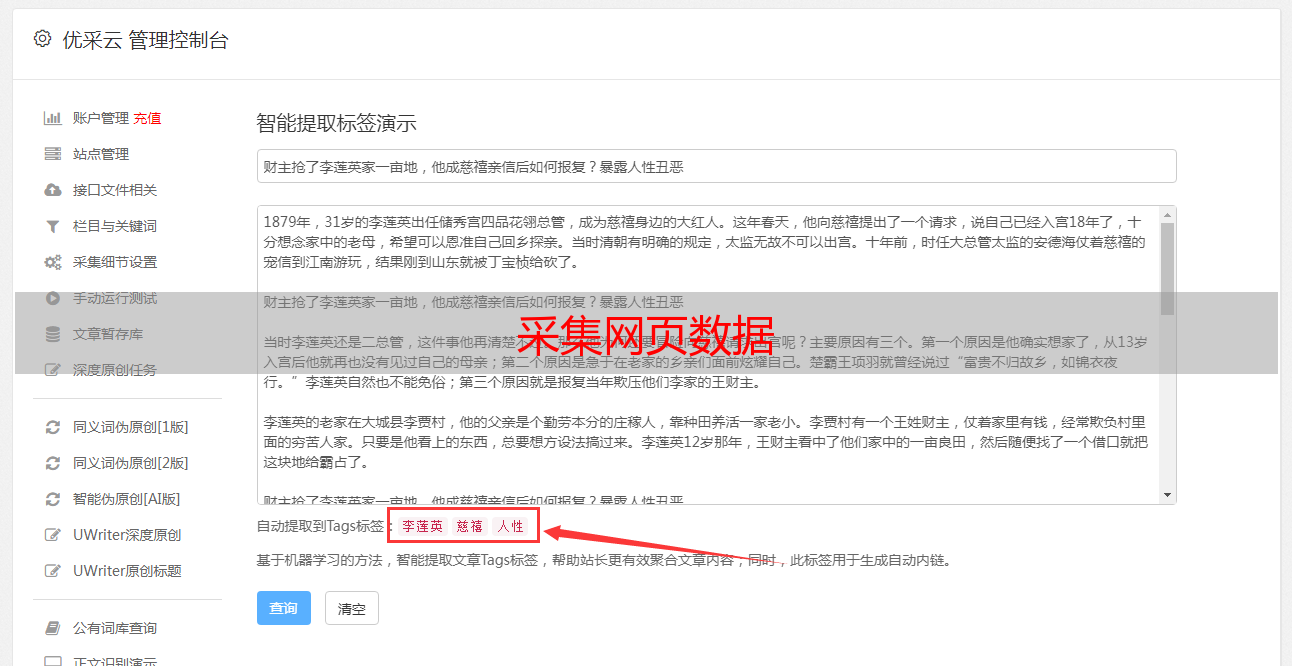
采集网页数据
优采云 发布时间: 2020-08-15 16:07注:集搜客GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”统一改为“任务”,在爬虫浏览器里先命名任务再创建规则,然后登陆集搜客官网会员中心的“任务管理”里,就可以查看任务的采集执行情况、管理线索网址以及做调度设置了。
一、操作步骤(观看视频)
下面用易迅网站作为案例,给你们演示怎么使用直观标明的功能采集网页数据,操作步骤如下:
二、案例规则+操作步骤
第一步:打开网页
1.1,打开GS爬虫浏览器,输入网址并Enter,加载出网页后再点击“定义规则”按钮,看到一个浮窗显示下来,称为工作台,在前面定义规则;
1.2,在工作台北输入主题名,再点击“查重”,提示“该名可以使用”或“该名已被占用,可编辑:是”,就可以使用这个主题名,否则请重命名。
Tips:为了能确切定位网页信息,点击“定义规则”会把整个网页定格住,不能跳转网页链接,点击“普通浏览”,才会恢复到普通的网页浏览模式。
第二步:标注须要采集的信息
2.1,标注是针对网页的文本信息来操作的,双击目标信息都会选中它,在弹出小窗中输入标签名,打勾确认或Enter。首次标明还要输入整理箱名称,即存数据的表名。这也是标签与网页信息构建映射关系的过程。
2.2,重复上一步操作来标明地址、电话信息。

第三步:存规则,抓数据
3.1,点击“测试”,检查信息完整性。不完整的话,对整理箱的标签右击删除后,再重新标明即可。
3.2,点击“存规则”。
3.3,点击“爬数据”,弹出DS打数机开始采集数据,测试采集规则是否有效。除了通过“爬数据”按钮来启动采集任务之外,还有其他运行方法,详见《DS打数机采集数据》。
第四步:查看数据
4.1,采集成功的数据会以xml文件的方式保存在DataScraperWorks文件夹中,详情见文章《查看数据结果》
提示:这篇教程只采集了第一个商品的数据,要采集这个页面上所有的商品信息,直接进行上篇文章《采集列表数据》中的第三步,做样例复制。
上篇文章:《集搜客网路爬虫的核心名词》 下篇文章:《采集列表数据》
若有疑问可以或

