腾讯新闻为例:文章采集软件的格式并不是非常规则
优采云 发布时间: 2021-08-25 05:14腾讯新闻为例:文章采集软件的格式并不是非常规则
对于每天在互联网和移动互联网网页上更新的文章,有什么快速的方法可以准确提取并应用到您的工作中?
复制下载一篇文章确实很麻烦。为了节省时间,提高效率,建议您使用文章采集软件进行操作。 优采云采集器V9 是一个可以快速实现文章采集的工具。而且灵活性很强,不仅可以通过规则设置复杂的采集,还可以一步设置自动提取文本。
文章采集软件多采用源码分析截取文章的首尾字符来实现内容采集,优采云采集器在设置规则时就是基于这个原理,并且文本提取功能在优采云采集器配备了文本提取算法,可以自动识别文本。有了这个功能,操作起来更方便。如果文章的格式不是很规则,则采用前后截取的方法。
以下为大家简单演示:以腾讯新闻为例:
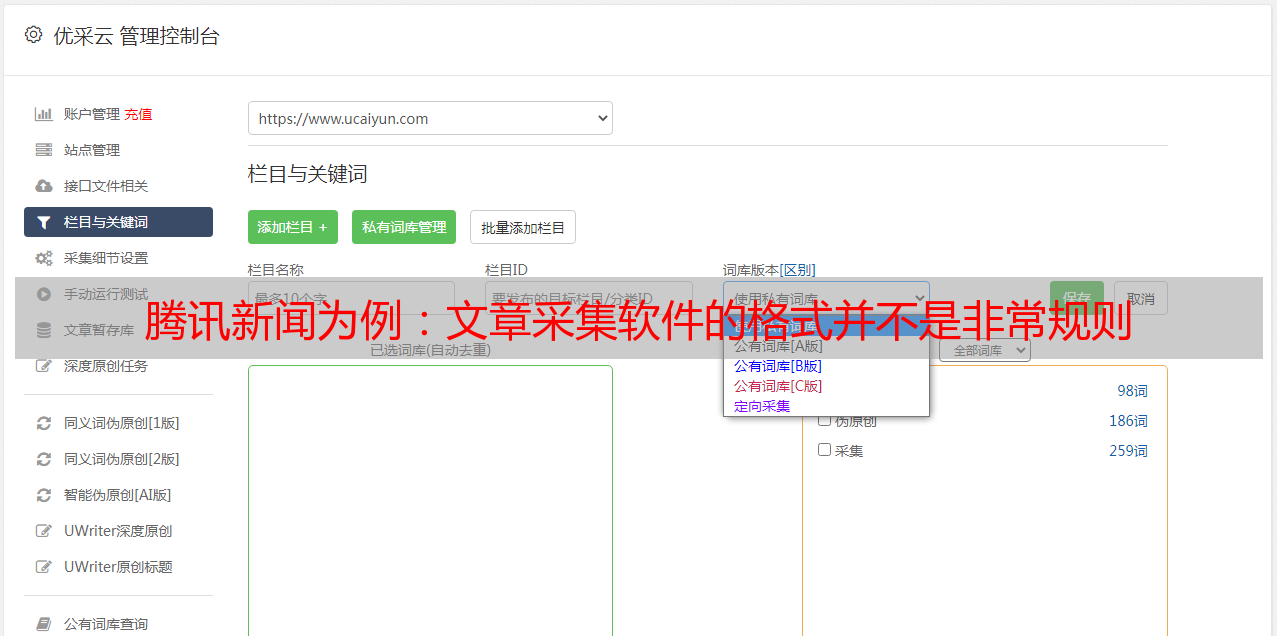
第一步:URL采集rule
1、添加起始网址:根据给定的网址打开腾讯新闻,发现新闻页面以列表页的形式显示,然后先将列表页的地址作为起始网址添加到优采云采集器中。
这里以添加6页为例。我们可以点击这6个标签的网址,将它们一一添加到采集器。但是如果我们要添加大量的URL,成百上千,那么一个一个添加就太麻烦了,所以我们可以试着找出URL之间的变化规律,批量添加。
我们分别打开第一页和第二页……观察它们的URL变化,可以发现除了第一页,后面的分页URL都以“_number”的递增方式变化,如如下:
然后我们首先将不合规的首页网址“”添加到起始网址列表中,如下所示:
添加第一个页面,然后通过向导-批量添加URL添加下面的列表页面,使用通用格式自动形成需要的URL,URL中的变量可以替换为地址参数,地址我们需要设置参数规则。上述规则从 2 开始,按 1 递增,共 5 项。填写后优采云采集器V9 会自动生成如下图所示的预览图。单击确定后,将添加起始 URL(这里是列表页面的 URL)。
2、获取内容页URL:通过观察新闻页,可以发现列表页的下一层是内容页,那么内容页的URL就是第一层的URL(列表页为0 -level URL),这里我们使用最简单的“自动获取地址链接”的方法,通过分析列表页面的源码,可以找出新闻内容页面地址所在的区域。起始字符是:“
",结束字符为:"
”。填完优采云采集器后会自动识别这个区域的地址链接,我们可以点击网址采集测试看看我们设置的采集规则是否给列表页和内容页面 URL 正确且完整。
第二步,content采集rules
1、Tag 编辑:标签列表可以进行添加、编辑、删除、复制等操作,我们先添加一个标题标签,选择文章的标题。我们将文章的标题设置为从默认页面的源码中获取,以前后截取的方式为例。
打开某新闻内容页面,分析页面源代码,在源代码中找到标题,我们搜索标题,会发现源代码中有多个标题,需要查找唯一基于代码常识的title“title”前后的字符串如下:
2、数据处理:“标题”中的标题有一个不需要的部分:“_新闻_QQ网”,那么我们将处理标题,添加一个数据替换过程,并更改“_新闻_QQ网” "替换为空,如下图所示。就这样,“月饼厂员工私卖月饼包装乱,拒不退货被发现后退还。”
我们再添加一个内容标签,去掉新闻内容采集,同样的方法找出内容页前后唯一的字符串。注意:内容前后的字符串不一定是我们要找的,可能是段落、图片等代码,所以对代码不太了解的用户最好多试几次确认。
设置完成后,点击测试看采集在内容中是否不符合要求,使用数据处理进行修改。这里我们排除了 html 标签:
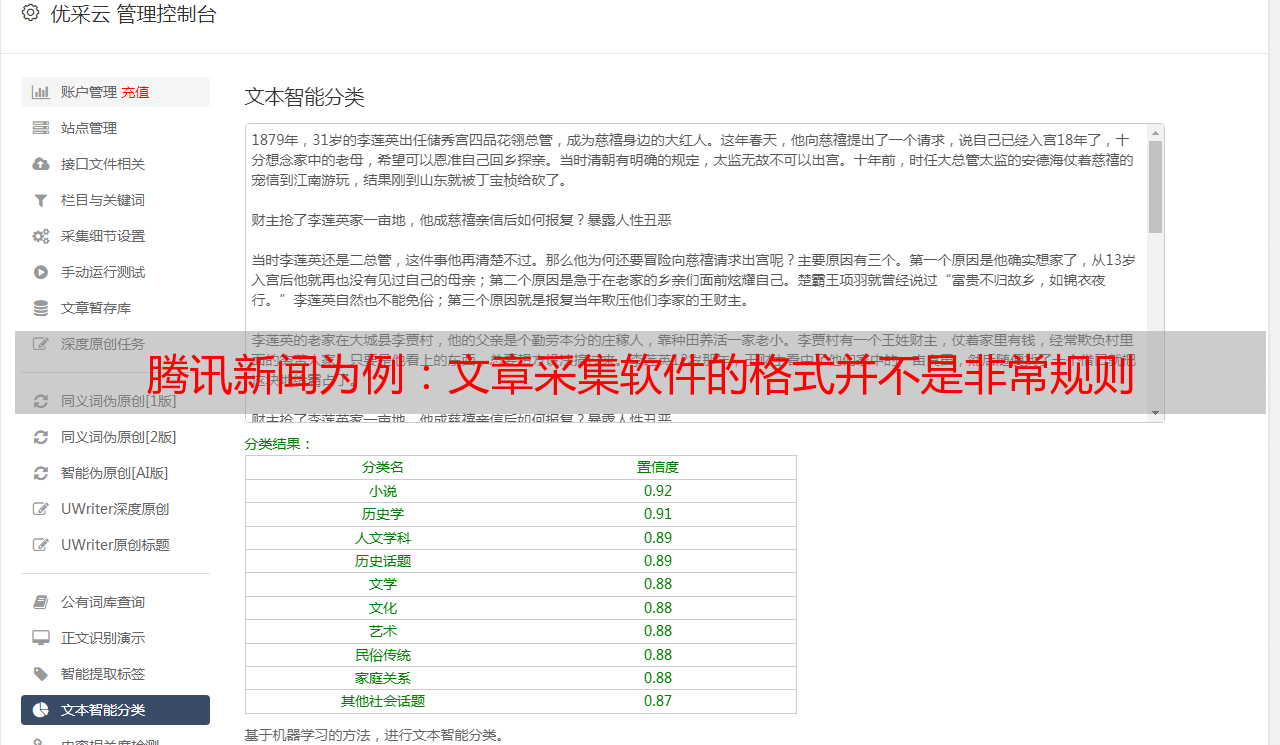
设置采集内容的规则后,我们选择一个页面进行测试,看看采集收到的内容是否符合要求,如果不符合,我们需要修改规则。 优采云采集器V9 的应用非常灵活。可以以多种方式或以多种形式设置规则。新手用几次很容易。下图显示我们有采集到达标题、内容,如有需要,您还可以采集时间、作者、相关阅读等
优采云采集器V9采集 大量文章还可以保持更快的速度,无论是采集文章更新自己的数据库还是下载学习研究资料,都用文章采集软件是提高效率的最佳选择。
联系我们

