好与坏,关键在于大大的噢!使用者噢~~
优采云 发布时间: 2021-08-18 19:11好与坏,关键在于大大的噢!使用者噢~~
我是一个好人,一个伟大的恩人。
好与坏的关键在于用户!
Scrapy是一个常用的数据采集工具;
Selenium 是一个浏览器自动化测试工具;
结合Scrapy的数据处理机制和Selenium,模拟真实浏览器获取数据(如:自动登录、自动翻页等)。 采集可以做得更好。
关于 Scrapy
Scrapy 是开发者在互联网上常用的数据采集 工具之一。我们已经习惯了通过 API 获取数据,但是一些网站出于“性能或安全”的原因仍然使用某些技术。该方法特意避开API传输数据(如静态页面、一次性令牌等)。因此,为了能够采集得到这些数据,我们可以分析站点和标签结构,然后通过使用Scrapy采集数据。
简单介绍一下Scrapy框架的作用,具体怎么帮我们采集数据?先来看看Scrapy的结构:
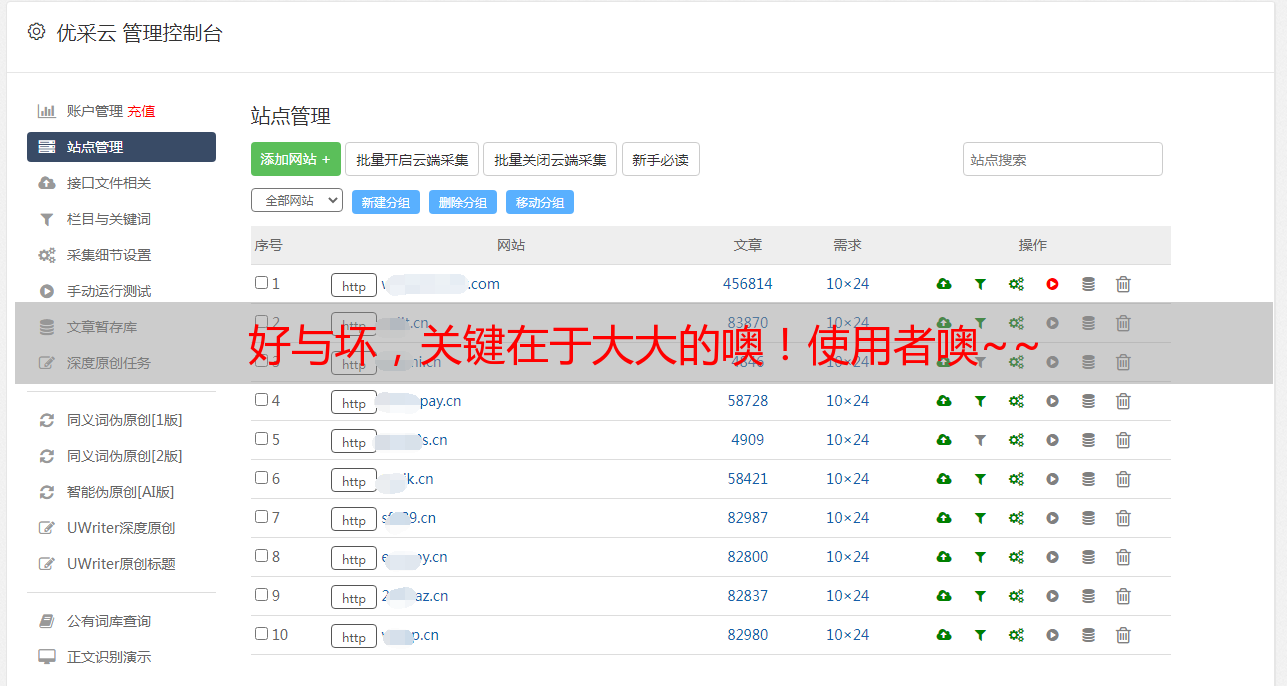
Scrapy 的数据流由 Scrapy Engine 控制,流程如下:
引擎初始化并获取来自 Spider 的请求。将请求放入调度程序。调度器将 Requests 一一发送给 Scrapy Engine 进行消费。 Scrapy Engine 通过下载器中间件将请求发送给下载器。下载器将Request获取的页面作为响应结果返回给Scrapy Engine。 Scrapy Engine 接收来自 Downloader 的 Response 并将其发送到 Spider Middleware 进行处理。 Spider 处理响应并将项目返回给 Scrapy 引擎。 Scrapy Engine将处理后的item发送到Item Pipeline,同时将处理后的信号发送给调度器(Scheduler)请求下一个采集请求。
重复以上步骤处理采集请求,直到调度器中没有新的请求。
Scrapy 安装教程:
Scrapy 项目创建
今天以清博大数据为例,完成自动登录、自动搜索、数据采集。
在文件根目录执行:
scrapy startproject qingbo
然后进入目录qingbo/并执行:
scrapy genspider crawl gsdata.cn
获取以下目录:
qingbo/
scrapy.cfg # deploy configuration file
qingbo/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items definition file
middlewares.py # 浏览器的启动和访问方式在这操作
pipelines.py # 处理好后的数据在这做最后处理
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py
crawl.py # 访问的连接和爬取后的数据在这里处理
其实在Scrapy中如何结合Selenium的关键在middlewares.py
具体的封装方法请参考:
关于硒
Selenium 是一种开源自动化测试框架,可通过不同的浏览器和平台验证 Web 应用程序。目前支持Python、Java、PHP等多种语言调用
Selenium 测试直接在浏览器中运行,就像真实用户一样,因此您可以利用这一点更好地执行数据采集。
Python Selenium 安装教程:
硒案例
未登录可直接访问青博大数据腾讯视频
如果没有任何反应,会跳转到登录页面进行登录。Selenium的环境安装上面已经讲到了,这里直接上代码:
网站打开
options = Options()
options.headless = False
driver = webdriver.Firefox(options=options)
driver.get('https://u.gsdata.cn/member/login')
driver.implicitly_wait(10) # 页面打开需要加载时间,所以建议加个静默等待

登录操作
可以找到两个选项卡,分别是:二维码登录和清博账号登录。
页面已经打开,如何进入清博账号登录标签?
这里我们需要了解Xpath(XML Path Language),它是一种用于确定XML文档某部分位置的语言。
简单来说,我们可以使用Xpath定位到“清博账户登录”的Tab
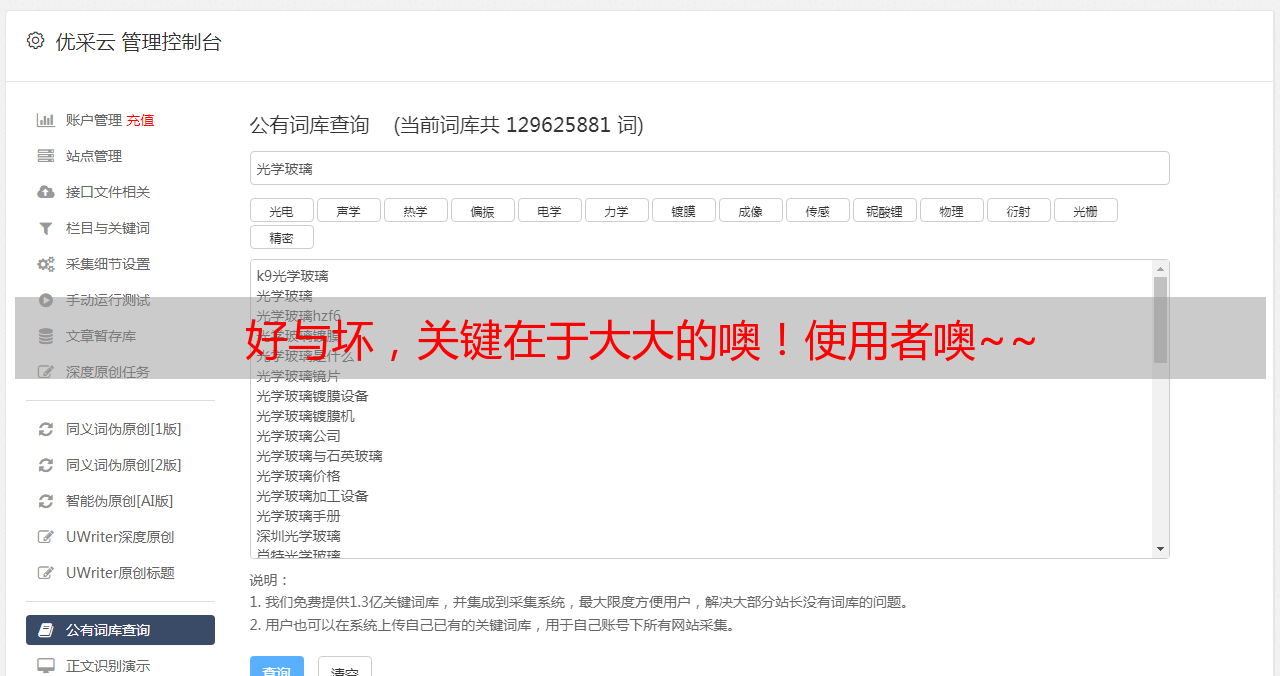
driver.find_element_by_xpath(".//div[@class='loginModal-content']/div/a[2]").click()
然后导航到帐户密码框并填写信息:
driver.find_element_by_xpath(".//input[@name='username']").send_keys("username")
driver.find_element_by_xpath(".//input[@name='password']").send_keys("password")
最后点击登录按钮:
登录成功! ~
查询操作
driver.get('http://www.gsdata.cn/')
driver.find_element_by_xpath(".//input[@id='search_input']").send_keys("腾讯视频")
driver.find_element_by_xpath(".//button[@class='btn no btn-default fl search_wx']").click()
driver.implicitly_wait(5)
经过搜索,得到如下结果:
使用Xpath定位腾讯视频的a标签,然后点击进入腾讯视频的数据内容页面:
driver.find_element_by_xpath(
".//ul[@class='imgword-list']/li[1]/div[@class='img-word']/div[@class='word']/h1/a").click()
driver.implicitly_wait(5)
内容页面
当你来到这里时,你感到惊讶吗?现在可以通过Xpath定位获取需要处理的内容,这里不再赘述。
关闭操作
driver.close()
获取数据后,如果没有其他操作,可以关闭浏览器。
总结
本章介绍了 Scrapy 和 Selenium 的基本概念和一般用法。总的来说,它可以帮助我们在解决一些问题时提供新的解决方案和思路。
参考

