网页分析使用Chrome浏览器信息的结构框架(一)(图)
优采云 发布时间: 2021-08-09 06:24网页分析使用Chrome浏览器信息的结构框架(一)(图)
文章directory
千城吾友网站
小远想了解一下全国爬虫开发工程师的招聘需求,做一个横向对比分析。*敏*感*词*招聘网站(如千城无忧)有成百上千的职位需求。显然,网上的招聘信息太多了。
所以,
爬上爬虫,
去吧!
目标,“无忧”爬虫帖子信息(网址:)
第一步:找出你需要什么
Step2:进行网页分析
用Chrome浏览器打开网页,发现第一页到第十三页的URL(统一资源定位符,即网络地址)分别对应“”到“”。由于网页布局是一样的,所以只需要完成一个页面,写一个循环就可以完成对所有信息的抓取。
查看网页源代码
右键->检查
或者直接Ctrl+Shift+C,选中要检查的内容,可以在源码中快速定位到要检查的内容的位置,个人推荐这个方法,
为了以防万一,你需要看看这个网页在服务器上获取数据的方式是GET还是POST。一般来说,不涉及登录信息或其他验证步骤的网页都是通过GET获取的,但这里为更详细的解释和展示。 (GET、POST等HTML相关知识请自行百度)
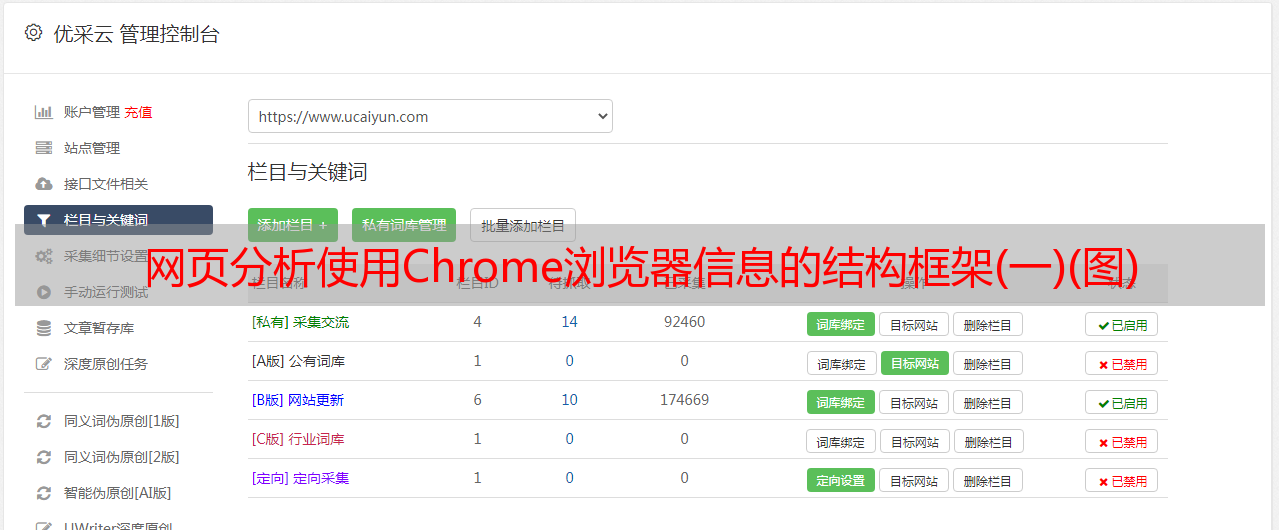
由于我们需要的内容是由一个小单元组成的(在这个例子中,一个职位有自己的属性信息,比如“职位名称”、“公司”、“工资”等)之后,你需要整理出网页所需信息的结构框架
大概如下两张图所示:

Step3:使用XPath Helper插件写出所需信息的大概Xpath路径
关于这个插件,博主在之前的文章中提到过,这里不再赘述
博主这里找到的Xpath路径是
//div[@class="detlist gbox"]/div
具体来说,这部分取下来后需要做什么,需要在程序中完成,以后会更新文章。
下一课已更新
总结
分析网络三部曲:
1、找到需要获取的网页内容,查看获取方式(GET、POST)
2、查看源码,了解其web框架
3、 通过插件快速确定所需内容的Xpath路径。
如果觉得博主文笔不错,请点赞,评论,关注。你的来访是博主更新的来源文章不排水!

