【干货】Flume的数据速率大于写入目的存储的速率
优采云 发布时间: 2021-08-06 23:46【干货】Flume的数据速率大于写入目的存储的速率
Flume 的优点:
Flume 可以与任何存储过程集成。数据速率大于数据写入目标存储的速率。 Flume会缓冲来减轻hdfs的压力(怎么理解:源数据来的快或慢,日志信息可能在用户活跃期,瞬间有5G的日志信息,几乎没有日志信息晚上,但是因为flume的缓冲能力,到达hdfs的速度比较稳定。)
Flume的运行机制:lume运行的最小单位,在一个JVM中独立运行。一个代理收录一个或多个源、通道、*敏*感*词*,每个代理收录三个组件。
souce:data采集组件,对接source data channel:传输通道组件,俗称pipe,data buffer,连接source和sink,连接source和sink sink:sink组件,用于向下一级代理传输数据或将数据传输到最终存储系统。
好的,理论知识介绍到这里,主要是看怎么使用。关于flume的安装搭建请看我的文章文章,我也写过flume是如何*敏*感*词*某个端口数据的。打印到控制台,这里我们更进一步,把本地文件采集放到HDFS上。
3.2.2 读取设置
首先需要给flume一个配置文件,告诉flume如何读取,放在哪里。进入flume/conf目录,创建collect_click.conf文件,写flume配置。指定三个组件的内容:
将以下代码写入:
# 定义这个agent中各个组件的名字, 这里的agent取名a1, 三个组件取名s1,k1,c1
a1.sources = s1 # 定义source
a1.sinks = k1 # 定义 sink
a1.channels = c1 # 定义 channel
# 描述和配置source channel sink之间的连接关系
a1.sources.s1.channels= c1
a1.sinks.k1.channel=c1
# 描述和配置source组件r1,注意不能往监控目录中丢重复同名文件呢, 从哪里取数据
a1.sources.s1.type = exec # 定义source类型为执行文件, 定义为目录用spooldir
a1.sources.s1.command = tail -F /home/icss/workspace/toutiao_project/logs/userClick.log # 本地log文件所在目录
a1.sources.s1.interceptors=i1 i2
a1.sources.s1.interceptors.i1.type=regex_filter
a1.sources.s1.interceptors.i1.regex=\{.*\} # json数据字符串的解析格式
a1.sources.s1.interceptors.i2.type=timestamp
# #描述和配置channel组件:c1
a1.channels.c1.type=memory
a1.channels.c1.capacity=30000 # 这里的数根据实际业务场景变,每天实时数据量大的时候,这里会相应的增大
a1.channels.c1.transactionCapacity=1000
# # 描述和配置sink组件k1 存储到哪?
a1.sinks.k1.type=hdfs # sink类型为hdfs
a1.sinks.k1.hdfs.path=hdfs://192.168.56.101:9000/user/hive/warehouse/profile.db/user_action/%Y-%m-%d # 这个就是指明存储的路径 后面是指定分区的时候,用时间来命名下一层目录
a1.sinks.k1.hdfs.useLocalTimeStamp = true # 是否使用本地时间戳
a1.sinks.k1.hdfs.fileType=DataStream # 生成的文件类型,默认是Sequencefile,可以用DataStream(就是普通文本)
a1.sinks.k1.hdfs.writeFormat=Text
a1.sinks.k1.hdfs.rollInterval=0 # 多久生成新文件,单位是多少秒
a1.sinks.k1.hdfs.rollSize=10240 # 多大生成新文件 也就是如果传过来的数据大小不足这个,就不会创建新文件
a1.sinks.k1.hdfs.rollCount=0 #多少个event生成新文件
a1.sinks.k1.hdfs.idleTimeout=60 # 文件占用时间,这个也挺重要的
# 文件占用时间这个,表示如果过了这个时间,就自动关闭文件,关闭flume占用
# 假设文件1, 写了1000个行为之后,flume依然一直占用着这个文件的话,我们是无法读取到这1000个行为的
# 所以为了满足实时的分析, 我们一般会设置这个文件占用时间,也就是如果flume占用了60分钟还没有任何操作的话,就关闭掉这个占用
直接按照这个,在flume目录下创建job文件夹,进入job文件,在里面创建一个collect_click.conf文件,写flume配置。
flume 的配置就完成了。现在配置 hive。
3.2.3 Hive 设置
接下来,设置 Hive。由于以上flume的设置,flume的采集其实就完成了。只要运行上面的配置文件,flume 就可以将本地用户行为日志上传到 HDFS profile.db 里面的 user_action 表中。接下来在Hive中创建数据库,然后在profile.db中创建user_action表与user_action表关联。
打开Hive并创建profile数据库,这意味着用户相关的数据profile存储在这个数据库中。
create database if not exists profile comment "use action" location '/user/hive/warehouse/profile.db/';
在配置文件数据库中创建 user_action 表并指定格式。这里要注意格式,和上一个不同:
create table user_action(
actionTime STRING comment "user actions time",
readTime STRING comment "user reading time",
channelId INT comment "article channel id",
param map comment "action parameter")
COMMENT "user primitive action"
PARTITIONED BY(dt STRING)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
LOCATION '/user/hive/warehouse/profile.db/user_action';
在Hive中输入这段代码,报第一个错误FAILED: ParseException line 5:10 mismatched input'comment' expecting
param map comment "action parameter")
再次创建表,收到第二个错误:FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask。无法验证 serde:org.apache.hive.hcatalog。 data.JsonSerDe,果然不是和别人在同一个环境下,就是不行。每一步都有陷阱。解决方法:需要添加支持序列化的hive-hcatalog-core-2.1.1.jar,执行如下命令即可解决。在安装目录中找到它。我的是
所以输入以下命令:
hive> add jar /opt/bigdata/hive/hive2.1/hcatalog/share/hcatalog/hive-hcatalog-core-2.1.1.jar;
这样,用户行为表就建立起来了。关于上述代码的一些细节:
ROW FORMAT SERDE'org.apache.hive.hcatalog.data.JsonSerDe':添加一个json格式匹配LOCATION'/user/hive/warehouse/profile.db/user_action':关联到这个位置的表PARTITIONED BY (dt STRING):这很重要。这是关于 Hive 中的分区。首先我们要知道Hive为什么要分区?
Hive 设置在这里。现在可以启动水槽采集命令了。
3.2.4 开始采集命令
cd /opt/bigdata/flume/flume1.9
bin/flume-ng agent --conf conf/ --conf-file job/collect_click.conf --name a1 -Dflume.root.logger=INFO,console
这样集合就完成了。来看看效果:
注意底部红框上方的 .tmp 文件。这时候就说明flume正在占用文件。这时候我们还不能使用hive查看这个文件中的数据。水槽被占用后,下面是生成的FlumeData文件。这时候我们就可以打开或者用hive查看了。打开看看:
原来这个日期指的是系统时间的日期。今天正好是3月9日,所以我把我自己制作到3月9日的所有用户点击行为都采集了起来。回到hive,我们试着看一下数据:
原来没有数据。这是因为Hive表的分区与flume采集的目录没有关联。如果没有关联,则无法查询数据。所以这里需要手动关联分区:
# 如果flume自动生成目录后,需要手动关联分区
alter table user_action add partition (dt='2021-03-09') location "/user/hive/warehouse/profile.db/user_action/2021-03-09/"
见证奇迹的时刻到了:

这样,用户的点击行为日志就存储在了Hive表中。接下来,我们将尝试将新的用户行为日志写入 userClick.log。为了识别,我这里直接用今天的时间
echo {\"actionTime\":\"2021-03-09 21:04:39\",\"readTime\":\"\",\"channelId\":18,\"param\":{\"action\": \"click\", \"userId\": \"2\", \"articleId\": \"14299\", \"algorithmCombine\": \"C2\"}} >> userClick.log
# 再写一条:
echo {\"actionTime\":\"2021-03-09 22:00:00\",\"readTime\":\"\",\"channelId\":18,\"param\":{\"action\": \"click\", \"userId\": \"2\", \"articleId\": \"14299\", \"algorithmCombine\": \"C2\"}} >> userClick.log
结果如下:
再看看hdfs:
看时间就知道已经上传到hdfs了。这时候从hive检查:
这样,上一步从本地用户行为日志通过flume,实时传输到HDFS,完成hive查询的过程。幸运的是,一切都很顺利。以下是注意事项:
这里创建Hive对应的日志采集表
①设置Hive数据库的过程,分区很重要
②手动关联分区的hadoop目录,查询flume采集日志配置
这里的重点是配置flume文件,告诉flume去哪里采集数据,哪里可以。有Hive的user_action表,hadoop有对应的目录,flume会自动生成目录,但是如果想通过spark SQL获取内容的话,还是要每天主动去关联。后面会提到,如果每天每次都手动关联,太累了。
好了,探索结束,现在可以删除他给的用户行为数据在Hive里建表了哈哈。
还有一件事需要组织,那就是自动化操作。和上一篇一样,我们的日志采集行为每天都在运行,所以我们需要一个工具来自动化管理。这就是所谓的Supervisor,它是一个流程管理工具。
4.应用supervisor管理flume并实时采集点击日志4.1supervisor进程管理
作为一种进程管理工具,Supervisor 可以轻松监控、启动、停止和重启一个或多个进程。当一个进程被Supervisor管理时,当一个进程被意外杀死时,supervisort会在检测到该进程死亡后自动重新拉起它。实现进程自动恢复功能非常方便,不再需要编写shell脚本来控制。
先安装,这里尝试直接用yum安装,提示找不到包:
解决方法,再次执行以下命令,注意切换到root:
# 安装Linux的epel的yum源的命令,某些yum源会提示无supervisor源码包,此时可以使用此命令
yum install epel-release
# 再安装
yum install -y supervisor
# 设置开机自启
systemctl enable supervisord
# 启动supervisord服务
systemctl start supervisord
# 重启
systemctl restart supervisord
# 查看supervisord服务状态
ps -ef|grep supervisord
名称说明:
启动supervisord服务时,又开始报错:
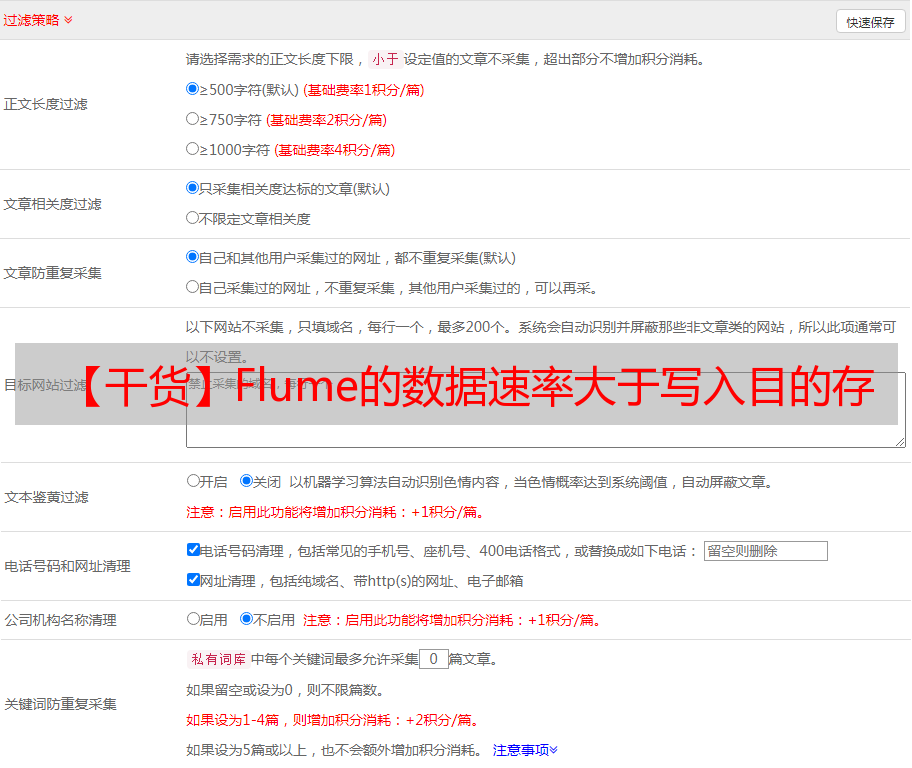
这时候按照提示输入如下命令查看,说: pkg_resources.DistributionNotFound: The'supervisor==3.4.0' distribution was not found and is the application required, the这样做的原因是supervisor在python3上支持不好,必须使用python2,这是python版本造成的。编辑/usr/bin/supervisord 文件并将第一行中的#!/usr/bin/python 更改为#!/usr/bin/python2。然后重新开始。
配置如下:
运行echo_supervisord_conf命令输出默认配置项。您可以将默认配置保存到文件中,如下所示。
echo_supervisord_conf > supervisord.conf
此时再报告
这是和上面一样的处理方法,找到这个文件,然后把第一行的python改成python2。这时候会在当前目录下生成一个supervisord.conf配置文件,打开,修改:
include 选项指定要收录的其他配置文件。这里是配置supervisor打开的配置文件。
好吧,我的不是这样。我打开上面的配置文件后,什么都没有,于是百度了一下。我的 /etc/ 中有一个 supervisord.conf 配置文件,我需要在那里更改它。好像不同的版本不一样。
只需更改此设置,只需 files=supervisor/*.conf。
然后我们在/etc目录下新建一个子目录supervisor(与配置文件中的选项相同),在/etc/supervisor/下新建一个头条管理推荐的配置文件reco.conf。可以在此处添加有关主管的任何信息。
添加配置模板如下(模板):
# 这里是举了两个supervisor自动管理进程的两个例子,只需要关注我注释的这3行,其他默认配置就OK
[program:recogrpc] # 管理进程的名字
command=/root/anaconda3/envs/reco_sys/bin/python /root/headlines_project/recommend_system/ABTest/routing.py
directory=/root/headlines_project/recommend_system/ABTest # 指定执行路径的一个命令
user=root
autorestart=true
redirect_stderr=true
stdout_logfile=/root/logs/reco.log # 管理过程中信息报错的打印路径
loglevel=info
stopsignal=KILL
stopasgroup=true
killasgroup=true
[program:kafka]
command=/bin/bash /root/headlines_project/scripts/startKafka.sh
directory=/root/headlines_project/scripts
user=root
autorestart=true
redirect_stderr=true
stdout_logfile=/root/logs/kafka.log
loglevel=info
stopsignal=KILL
stopasgroup=true
killasgroup=true
我们后面会根据这个模板来配置我们的flume自动日志采集流程,我们来说说配置完成之后的事情。
配置完成后,我们将启动supervisor。
supervisord -c /etc/supervisord.conf
#查看supervisor是否运行
ps aux | grep supervisord
我们也可以使用 supervisorctl 来管理 supervisor。
supervisorctl
> status # 查看程序状态
> start apscheduler # 启动 apscheduler 单一程序 这个名词就是我们上面模板中program后面的那个程序名词
> stop toutiao:* # 关闭 toutiao组 程序
> start toutiao:* # 启动 toutiao组 程序
> restart toutiao:* # 重启 toutiao组 程序
> update # 重启配置文件修改过的程序 一旦修改配置文件,就需要执行这个
在这里执行这个会报python版本的错误,所以先改这个东西。
vim /usr/bin/supervisorctl
# 将首行python改成python2
现在状态下什么都没有了,因为我还没有设置程序被管理。
工具介绍到此结束,下面就是我们这次的目标,启动监控flume采集日志程序。
4.2 启动监控flume采集日志程序
目的:开始监控flume采集日志
我在头条工程的scripts里面统一写了脚本,在里面创建了collect_click.sh脚本,输入:
#!/usr/bin/env bash
export JAVA_HOME=/opt/bigdata/java/jdk1.8
export HADOOP_HOME=/opt/bigdata/hadoop/hadoop2.8
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
/opt/bigdata/flume/flume1.9/bin/flume-ng agent --conf /opt/bigdata/flume/flume1.9/conf/ --conf-file /opt/bigdata/flume/flume1.9/job/collect_click.conf --name a1 -Dflume.root.logger=INFO,console
这里需要指定JAVA_HOME和HADOOP_HOME,因为supervisor和终端是分开的,否则找不到。而且这里必须换成绝对路径。
接下来就是配置superior,让它自动运行上面的脚本,类似于一个守护进程在那里运行。编辑上面创建的 reco.conf 文件,
cd /etc/supervisor
vim reco.conf
加入:
[program:collect-click]
command=/bin/bash /home/icss/workspace/toutiao_project/scripts/collect_click.sh
user=root
autorestart=true
redirect_stderr=true
stdout_logfile=/root/logs/collect.log
loglevel=info
stopsignal=KILL
stopasgroup=true
killasgroup=true
这时候去supervisor控制台更新。
这表明已经添加了一个程序。这是我们上面的采集点击。然后在状态下:
老师说默认是不会激活的,我是怎么激活的?留下他一个人。这时候打开日志查看,会发现flume在后台运行:cat /root/logs/collect.log
再次测试,即在之前的日志中添加一条用户数据,看看效果:
即Flume在后台自动采集用户行为数据,放到Hive中。好吧,探索之后,关闭这个程序。
stop collect-click
这里探讨了用户点击行为的自动采集过程。
参考:

