前两章如何对内容数据的采集的四种常规方式
优采云 发布时间: 2021-08-06 23:13前两章如何对内容数据的采集的四种常规方式
大家好,我是教程的主人。通过前两章的学习,你应该已经掌握了如何获取内容页面的URL。本章从采集和文章内容的处理开始。本节主要介绍如何采集内容数据,使用以下四种方法:
1.前后截取2.正则取
3.可视化提取
4.tag 组合
这四种方式是采集获取数据的四种常规方式,下面我会一一讲解。
1、前后截取
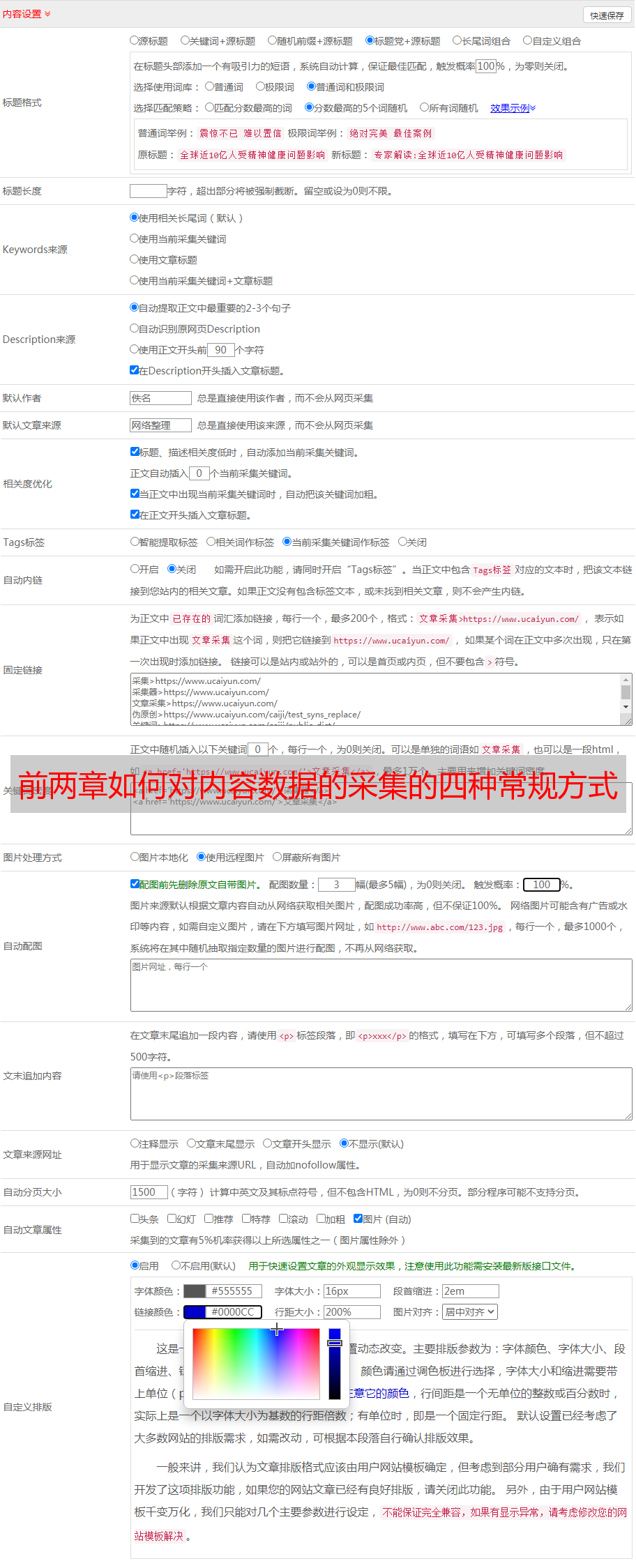
我们打开软件,继续上一节,点击采集content规则,显示如下:
点击标题,弹出如下界面:
可以看到我们选择了通过采集获取数据。这是标题。标题是文章的标题。我们要先在文章中找到这个标题,打开内容看看。看:
我们打开源码,找出这个标题的位置。我们已经在文章以下地方发布了标题文字,如下:
我们尽量选择带有标签的标签。这种类型的标签基本上用作标题标签。我们不会更改标题采集 的标题和结尾。我们默认测试一下:

我们会发现他后面有_光光网这样的后缀。如果我们不想这样,我们可以在标题中添加文本替换:
点击添加,选择内容替换如下操作:
这样就成功了,测试图如下:
我们的标题是成功的。
如何使用内容的前后截取,其实和标题一样,先找到内容位置,然后再找到合适的前后截取位置。选择的前后截取位置的字符在文章中应该是唯一的,如下:
先复制文章中的第一段,在源码中找到文章的开头:
我们会发现
这个代码段一般用作文章的开头,并且测试在源代码中是唯一的,所以可以作为文章的第一个拦截位置,同理找到结束拦截位置:
这里我们可以在这两个位置之间进行选择。如果我们要带编辑器,我们会选择后者。如果我们不想带,我们就选择前者。这里我选择了前者。
最后如下:
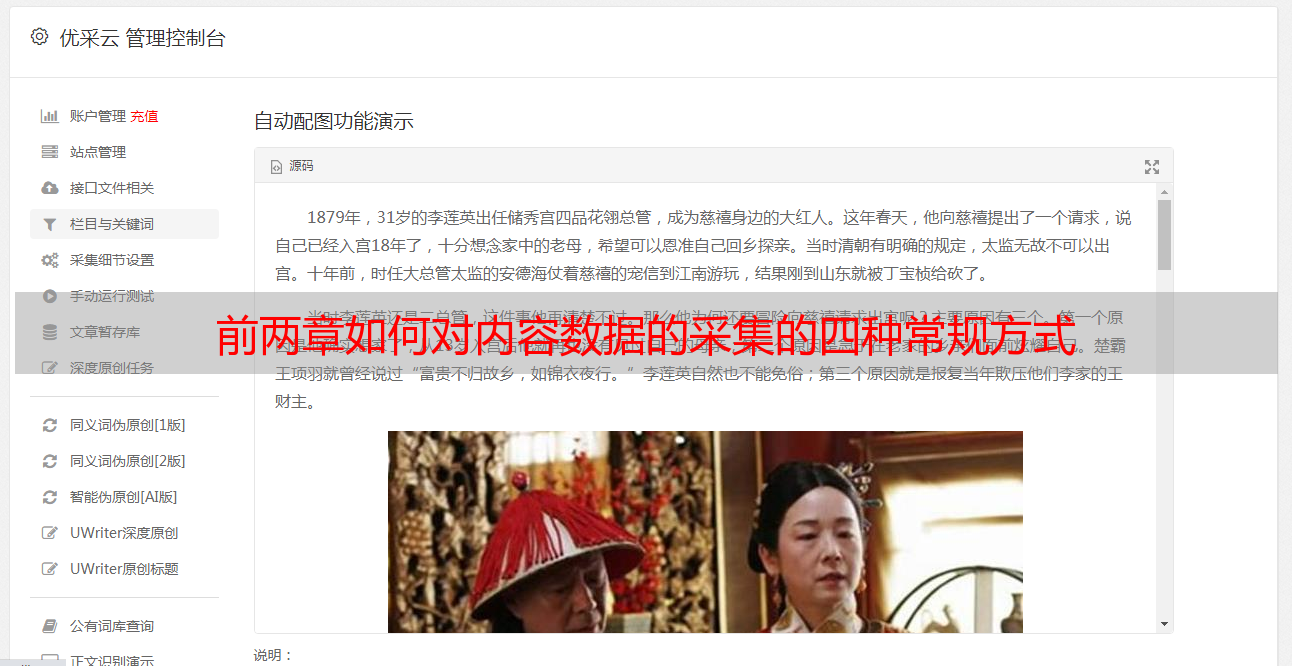
这样我们就把内容采集好。对于作者,我们可以采集文中,也可以自己定义作者。文中第一个采集,我们可以用这段:
我们可以用同样的方法来做时间和来源,这里就不演示了。您也可以自己添加相应的标签以匹配您的站点标签。这里的列是上一节中使用的组合标签的结果。
您的赞赏是我坚持原创的动力
共0人欣赏

