批量输入多个关键词的采集步骤及步骤教程步骤
优采云 发布时间: 2021-08-03 22:13采集scene
在孔子旧书网搜索页面:输入该书的关键词(包括ISBN)进行搜索,搜索后会得到书单,然后点击书单中的书链接进入详情页面,采集detail 页面数据。
ISBN 是一个国际编号,专门用于识别书籍和其他文件。如果您使用 ISBN 搜索,搜索结果都是关于特定书籍的。
采集Field
作者、书名、售价、定价、库存、外观和出版时间等字段。
点击查看高清大图,下图同理。
采集Result
采集 结果可以导出为Excel、CSV、HTML、数据库等格式。导出到 Excel 示例:
教程说明
本文制作时间:2020/9/28 优采云版本:V8.1.22
如因网页改版导致网址或步骤无效,无法采集到目标数据,请联系官方客服,我们会及时更正。
采集Steps
步骤一、打开网页
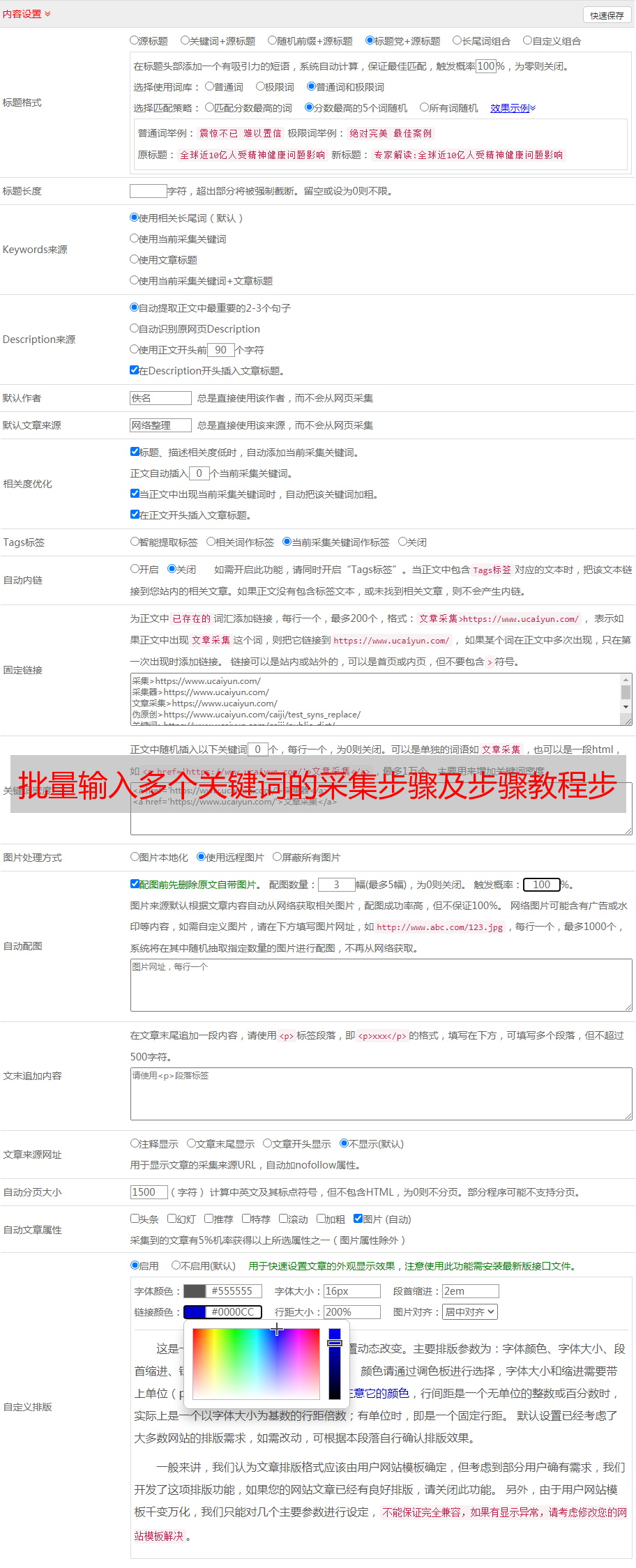
步骤二、批量输入多个关键词并搜索
步骤三、建立【loop-click元素】,进入每个产品的详情页面
步骤四、setting [提取数据],采集必填字段
步骤五、建立【翻页循环】,采集多页数据
步骤六、编辑字段
步骤七、设置滚动并等待执行
步骤八、Start采集
具体步骤如下:
步骤一、打开网页
在首页【输入框】输入目标网址,点击【开始采集】,优采云会自动打开网页。
特别说明:
一个。打开网页后,如果开始启动【自动识别】,请点击【不再自动识别】或【取消识别】将其关闭。因为本文不适合使用【自动识别】。
B. 【自动识别】适用于自动识别网页列表、滚动、翻页。识别成功后可以直接启动采集获取数据。详情请点击查看【自动识别】教程
步骤二、批量输入多个关键词并搜索
打开网页后,通过以下步骤批量输入多个关键词。
1、 输入 1 关键词 并搜索
选择搜索框,在操作提示框中点击【输入文字】,输入关键词并保存。
选择【搜索】按钮,在操作提示框中点击【点击此按钮】,出现关键词的搜索结果。
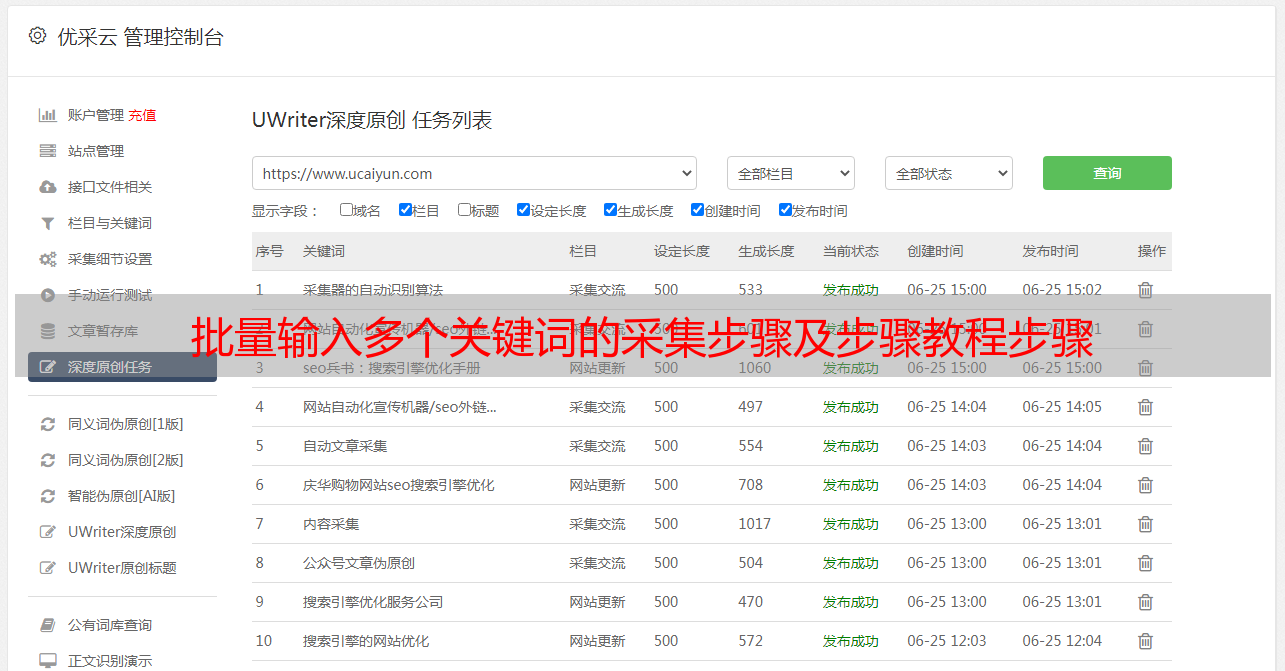
2、批量输入多个关键词
①在【打开网页1】的步骤后,添加一个【循环】。
②将【输入文本】和【点击元素】都拖入【循环】中。
③ 进入【周期】设置页面。选择循环方式为【文本列表】,点击按钮,输入我们准备好的关键词(可以同时输入多个关键词,每行一个)并保存。
④ 进入【输入文本】设置页面,删除原来的关键词,勾选【使用当前循环中的文本填充输入框】并保存。
特别说明:
一个。例子中输入的关键词为[data]、[weeder]、[采集],可以根据自己的需要替换。
B.一次最多输入 2W 个关键字。可以先准备一个收录多个关键字的文档,然后复制粘贴到优采云中。
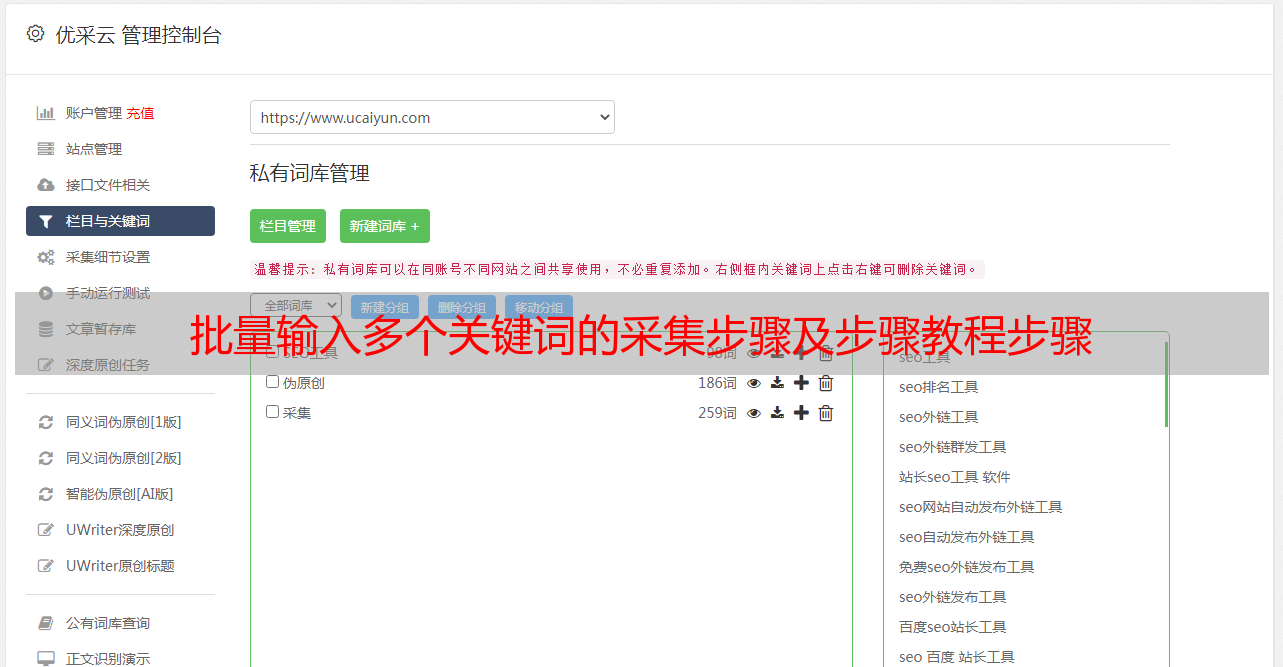
步骤三、建立【循环-点击元素-提取数据】,采集各个产品详情页信息
观察网页。在此网页上,您可以通过单击标题进入详细信息页面。以下是具体步骤。
①选择页面上的第一个链接
②在*敏*感*词*的操作提示框中,选择【全选】
③在*敏*感*词*的操作提示框中,选择【循环点击每个元素】
然后自动进入第一本书的详情页。
特别说明:
一个。经过以上3步,【循环-点击元素-提取数据】的创建就完成了吗?点击查看,从列表中进入详情页采集tutorial。
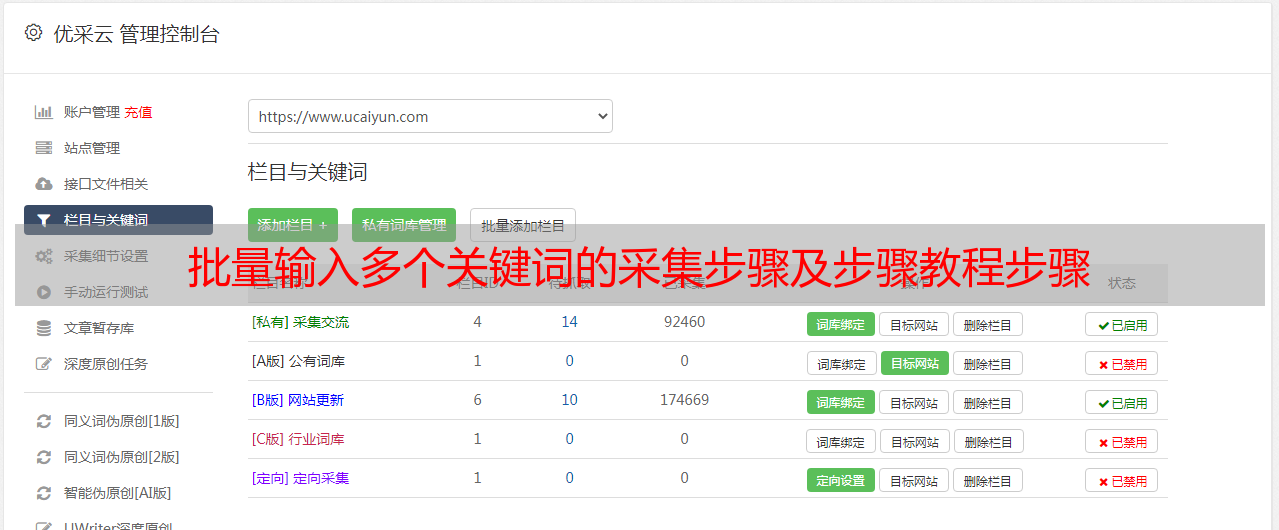
步骤四、setting [提取数据],采集必填字段
进入详情页后,采集我们需要的字段。
如果是文本字段:用鼠标选中需要的字段,在*敏*感*词*提示框中选择【采集元素的文本】。
示例中的采集都是文本类型的字段。
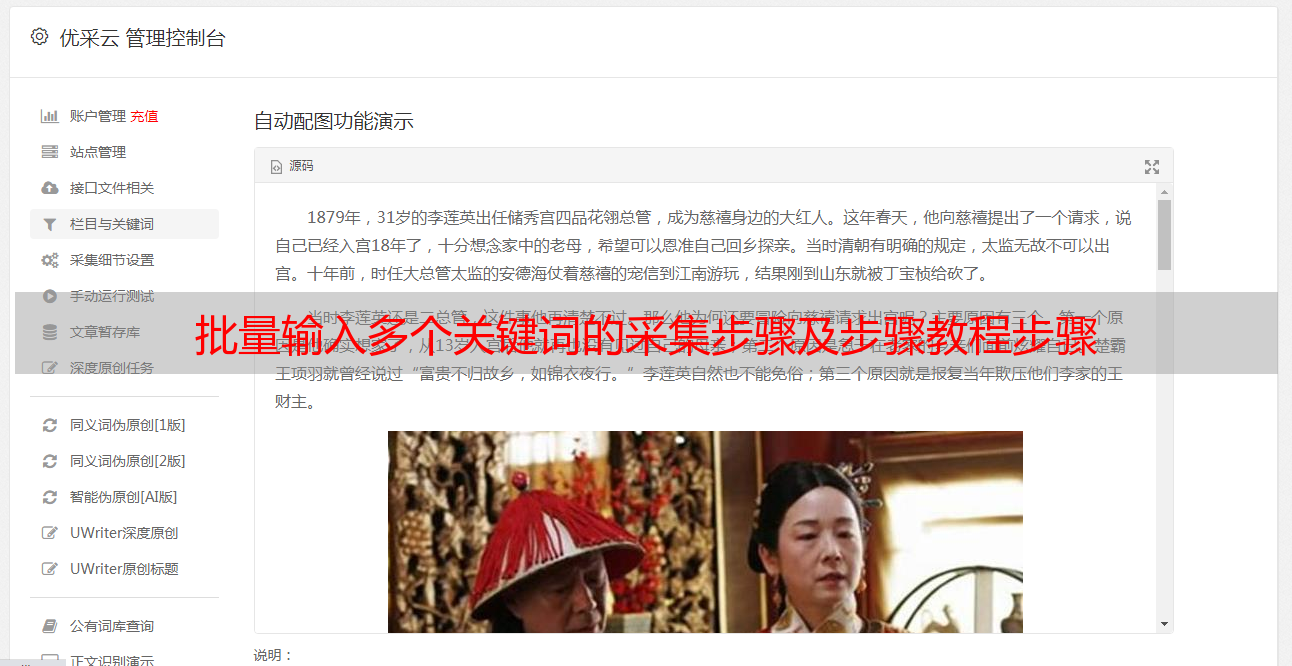
步骤五、建立【翻页循环】,采集多页数据
如果只有采集一页数据,可以跳过这一步。
如果需要翻页到采集多页数据:
①点击过程中的【循环列表】返回产品列表页面
②找到网站下的翻页按钮,选择【下一页】按钮,在*敏*感*词*的操作提示框中选择【循环点击下一页】
经过以上操作,【循环翻页】的创建就完成了。
特别说明:
一个。创建【循环翻页】后,优采云会自动点击翻页按钮进行翻页,从第一页、第二页……一直到最后一页。如果只需要采集特定的页面数据,可以在优采云中设置翻页的周期数。详情请点击查看翻页采集多页数据教程。
步骤六、编辑字段
1、修改字段名称,移动字段位置
进入【提取数据】设置页面,删除不需要的字段信息,编辑字段名称。
2、修改字段 XPath
为了准确采集每本书详情页的字段,我们需要手动修改每个字段的XPath。
进入【提取数据】设置页面,找到目标字段,修改其XPath。
示例中修改的是该字段的XPath和替代XPath:
质量 XPath://I[@class="quality-desc-new"]
替代 XPath://p[@class="quality clearfix"]//following::i[1][@class="quality-desc-common"]
特别说明:
一个。如何修改XPath?这需要一些 XPath 知识。点击查看XPath学习和示例教程
其实详情页中每个字段的XPath都需要修改。请选择您需要的字段并根据需要进行修改。
[作者] XPath://span[contains(text(),'author')]//following-sibling::span
替代XPath://span[contains(text(),'author')]|//li[contains(text(),'author')]/a
[Publishing] XPath: //span[contains(text(),'publisher')]//following-sibling::span
替代 XPath://li[contains(text(),'publisher')]/span
[Binding] XPath //span[contains(text(),'binding')]//following-sibling::span
备用 XPath //li[contains(text(),'binding')]/span
[发布时间] XPath: //span[contains(text(),'publication time')]//following-sibling::span
备用XPath://li[contains(text(),'发布时间')]/span
[format] XPath: //span[contains(text(),'format')]//following-sibling::span
替代 XPath://li[contains(text(),'format')]/span
[ISBN] XPath: //span[contains(text(),'ISBN')]//following-sibling::span
替代 XPath://li[contains(text(),'ISBN')]/span
[Edition] XPath: //span[contains(text(),'Edition')]//following-sibling::span
替代 XPath://li[contains(text(),'version')]/span
[Paper] XPath: //span[contains(text(),'paper')]//following-sibling::span
替代 XPath://li[contains(text(),'paper')]/span
[页数] XPath: //span[contains(text(),'page number')]//following-sibling::span
替代 XPath://li[contains(text(),'page number')]/span
特别说明:
一个。如何修改XPath?这需要一些 XPath 知识。点击查看XPath学习和示例教程
步骤八、设置滚动并等待执行
1、设置滚动
有些网页打开后,需要向下滚动才能加载更多数据,所以优采云中也要设置为滚动:
进入【点击元素】设置页面,勾选滚动方式为【向下滚动一屏】、【滚动次数】10次、【每间隔】1秒。
2、设置【执行前等待】
【Wait before execution】是指在执行这一步之前,等待一段时间(等待时间根据自己的需要自行设置)。作用是等待网页上的采集数据完全加载后才执行这一步。
进入【点击元素】设置页面,将【执行前等待】设置为3s。
步骤八、Start采集
1、 点击【采集】和【启动本地采集】。启动优采云后自动采集数据。
特别说明:
一个。 【本地采集】为采集使用自己的电脑,【云采集】使用优采云采集提供的云服务器,点击查看本地采集与云采集详细解释。
2、采集 完成后,选择合适的导出方式导出数据。支持导出到 Excel、CSV、HTML、数据库等。这里导出到 Excel。数据示例:

