SEO科技网更新日期:2021-4-19预处理
优采云 发布时间: 2021-07-26 01:52
SEO科技网更新日期:2021-4-19预处理
第十节:搜索引擎工作原理的预处理
来源:SEO技术网上传:SEO技术网更新日期:2021-4-19
第十节:搜索引擎工作原理的预处理
预处理
由于搜索引擎数据库中有很多网页,用户搜索后,索引计算量过大,短时间内很难返回搜索结果,所以必须对页面进行预处理。
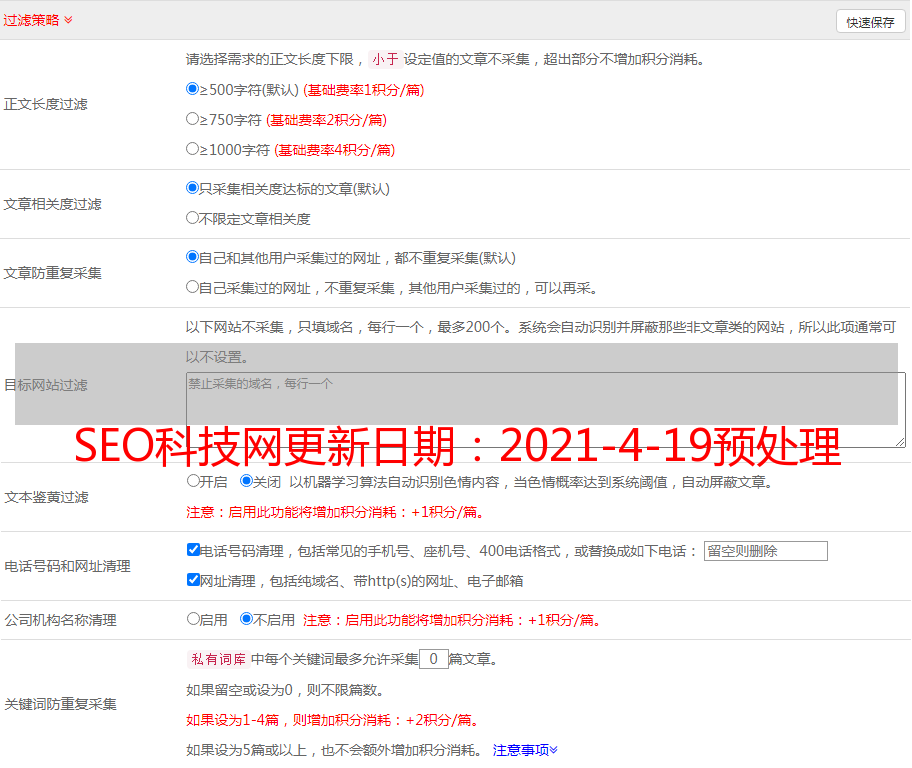
(1)提取文本
搜索引擎预处理首先要做的是去除HTML文件中的标签和程序,提取网页文本内容进行排名处理。
(2)中文分词
中文单词之间没有分隔符,一个句子中的所有单词和单词都连接在一起。因此,搜索引擎首先要区分哪些字符构成一个词,哪些字符本身就是一个词。
中文分词有两种方法,即基于词典匹配的分词和基于统计的分词。
(3)停止这个词
停用词是指在网页内容中频繁出现但对内容没有影响的词,因为它们对页面内容没有实质性影响。搜索引擎会在索引页面之前删除这些停用词。

(4)消除噪音
噪音是指对页面主题没有贡献的内容,如版权声明、导航栏、广告等,只能起到分散页面主题的作用。因此,搜索引擎需要识别并消除这些噪音,在排名时不要使用噪音内容。
(5)去重
搜索引擎不喜欢重复的内容,所以在索引之前,识别内容并删除重复的内容。这个过程可以称为“重复数据删除”。

(6)forward 索引
经过文本提取、分词、去噪、去重后,搜索引擎可以提取关键词,按照分词程序划分关键词,将页面转化为关键词的集合,其中每个关键词词频、格式、位置等权重信息都有记录。
(7)倒排索引
如果搜索引擎只能索引转发,排名程序需要扫描索引库中的所有文件,然后进行排名计算,这样计算量不能满足实时返回排名结果的要求,所以搜索引擎需要重构正向索引数据库作为引导索引,将文件到关键词的映射转换为关键词到文件的映射。
(8)link 关系计算
当前的搜索引擎收录在网页之间流动的信息。搜索引擎抓取页面内容后,必须弄清楚页面上有哪些页面,使用了哪些链接。
由于页面和链接数量众多,计算链接关系和权重需要很长时间。
(9)特殊文件处理
除了 HTML 文件,搜索引擎通常可以抓取和索引多种基于文本的文件类型,例如 PDF、Word、WPS、XLS、PPT、TXT 文件等。

