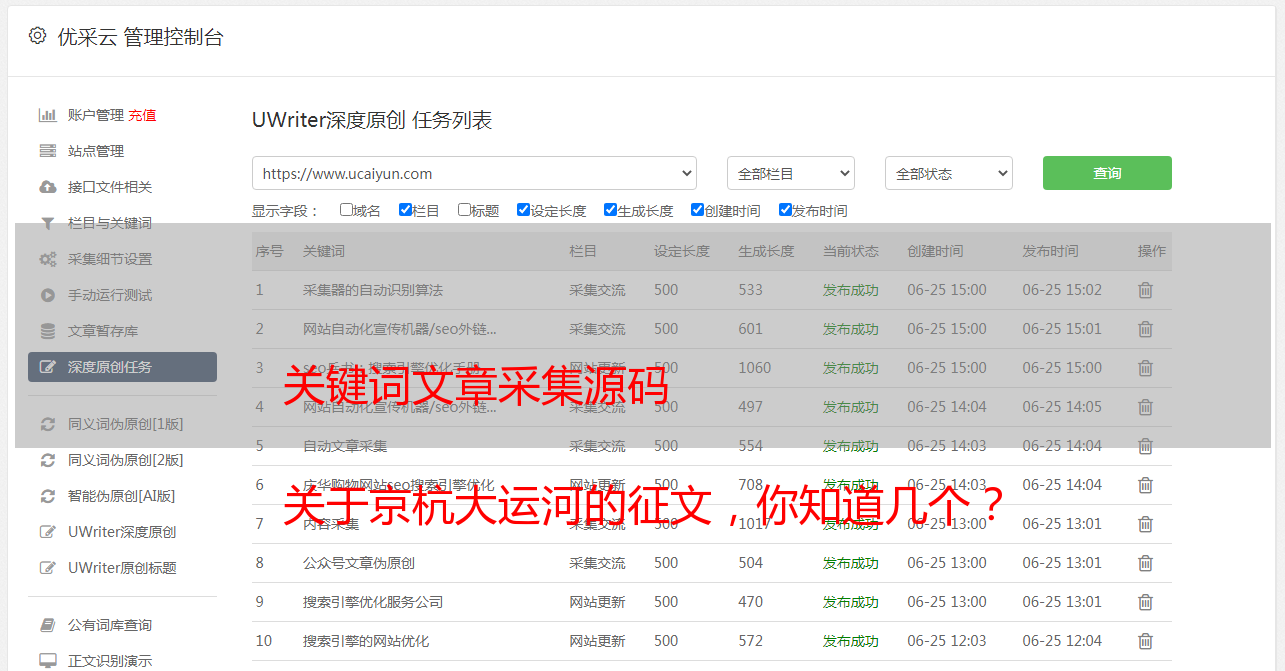
关键词文章采集源码 关于京杭大运河的征文,你知道几个?
优采云 发布时间: 2021-07-03 20:42关于京杭大运河的征文,你知道几个?
1.背景介绍
(1)注册了网站后,发现站台个人页面上有一篇关于京杭大运河的文章。另外,九寨沟地震前,机器人写了一篇简讯第一次。所以我在想,既然机器可以写简讯,那么它也可以用来写一篇关于京杭大运河的文章吗?有一个大致的想法,那么我们开始吧。
(2)open 杜娘,搜索:北京运河经航,看源码结构。
使用Requests和Re(百度的搜索链接比BeautifulSoup更方便)提取链接地址。
问题来了,提取的链接如下:
http://www.baidu.com/link?url=xrStztha3DcV7ycuutlYKna-IOpP4qUJ7x0F48oUfxvb9moDNuanGFVpA_r9q8y4k6bm6HxotwnLM6oRoVabtgMrKnk3b6ZH2VJNixURhLW
用Requests做get请求没有得到目标页面的响应,是不是很毛?
因为link?url=?下面的密文需要用JS解密,而这个JS,Requests很无奈。是的,JS渲染必须使用PhantomJS。
(2)使用PhantomJS+Selinium访问链接上的加密链接(对前端JS很熟悉的bobbin,也可以逆向解析JS函数,通过传参获取真实URL . 这是传统的手工作坊 . 使用driver.page_source() 获取真实地址对应的网页源代码。
(3)这次我不是想从真实的网页中提取某个网页标签。另外百度搜索结果不同网站about京杭大佳能的文章格式都不一样,没办法摘录。哈哈,这次旅行的目的是为了得到不同的网站关于大运河新闻的文字或图片。
(4)对文本数据进行词频分析。保留作业:采集到达的图片使用上节描述的照片墙。
2.分析结果(事先不知道京杭大运河的鬼魂是什么)
PS:如果你学会了这招,再加上一点历史知识,再加上沿途美食美景的照片墙,一个极具吸引力的人机交互手稿就出来了。想写essay的地方都可以这样玩,自媒体也可以这样玩。
3.源代码
(1)Grab 百度初始化搜索页面源文件
# coding = utf-8
import requests
import re
headers = {
'Host': 'ss1.bdstatic.com',
'content-type': 'application/json',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36',
'Referer': 'https://www.baidu.com/s?wd=%E5%8C%97%E4%BA%AC%20%E8%BF%90%E6%B2%B3%20%E4%BA%AC%E6%9D%AD&pn=0&oq=%E5%8C%97%E4%BA%AC%20%E8%BF%90%E6%B2%B3%20%E4%BA%AC%E6%9D%AD',
'Connection': 'keep-alive'
}
base_url = 'https://www.baidu.com/'
s = requests.session()
s.get(base_url)
find_urls = []
for i in range(20):
print(i)
url = 'https://www.baidu.com/s?wd=%E5%8C%97%E4%BA%AC%20%E8%BF%90%E6%B2%B3%20%E4%BA%AC%E6%9D%AD&pn=' + str(
i * 10) # 关键词(北京 运河 京杭)
print(url)
content = s.get(url, headers=headers).text
find_urls.append(content)
find_urls = list(set(find_urls))
f = open('url.txt', 'a+',encoding='utf-8')
f.writelines(find_urls)
f.close()
(2)使用正则提取搜索页面的初始网址(也可以使用BS4)
# coding = utf-8
import re
f = open('url.txt',encoding='utf-8').read()
f2 = open('urlin.txt', 'a+',encoding='utf-8')
find_urls = re.findall('href="http://www.baidu.com/link(.+?)"', f )
find_urls = list(set(find_urls))
find_u = []
for url_i in find_urls:
in_url = 'http://www.baidu.com/link' + url_i + '\n'
f2.write(in_url)
f2.close()
(3)重装PhantomJS获取网页文字
# encoding: utf-8
# 导入可能用到的库
import requests, json, re, random, csv, time, os, sys, datetime
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
dcap = DesiredCapabilities.PHANTOMJS
dcap[ "phantomjs.page.settings.userAgent"] = "Mozilla / 4.0(Windows NT 10.0; Win64;x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome/51.0.2704.79 Safari/ 537.36Edge/14.14393"
# 请求头不一样,适应的窗口不一样!
driver = webdriver.PhantomJS(desired_capabilities=dcap)
driver.set_page_load_timeout(10)
driver.set_script_timeout(10)#这两种设置都进行才有效
find_urls = open('urlin.txt',encoding='utf-8').readlines()
# print(len(find_urls)) # 634个URL # 关键词(北京 运河 京杭)
i = 0
f = open('jh_text.txt', 'a+',encoding='utf-8')
for inurl in find_urls:
print(i,inurl)
i+=1
try:
driver.get(inurl)
content = driver.page_source
# print(content)
soup = BeautifulSoup(content, "lxml")
f.write(soup.get_text())
time.sleep(1)
except:
driver.execute_script('爬虫跳坑里,等会继续')
(4)从百度搜索结果(13.7M)的50页文本中去除停用词,然后进行词频分析(pandas就够了)。
新手可以查看历史目录:
yeayee:Python 数据分析和可视化示例目录