爬虫工程师揭秘:如何高效获取海量文章?
优采云 发布时间: 2024-03-25 10:22随着当今资讯过载现状,对许多人群而言,获取海量文章至关重要。爬虫软件,凭借其高效特性,以协助我们迅速攫取所需文章。本文身为资深爬虫工程师,特分享相关采编经验与窍门。
一、选择合适的目标网站
确定精准的目标站点,乃是有效获取原文文章的首要步骤。关键在于对网站的可信度及其内容品质进行严谨评估;同时,需确认站点开放爬取且未采用反爬措施;最后,关注网站架构及页面布置是否便于开展爬取工作。
二、分析网页结构
在编写爬虫程序前,需深入解析目标页面构造。充分理解网页元素布局与特性(如标题、文本、创作者等等),便于制定精准确切且高效的采集策略。
三、编写爬虫代码
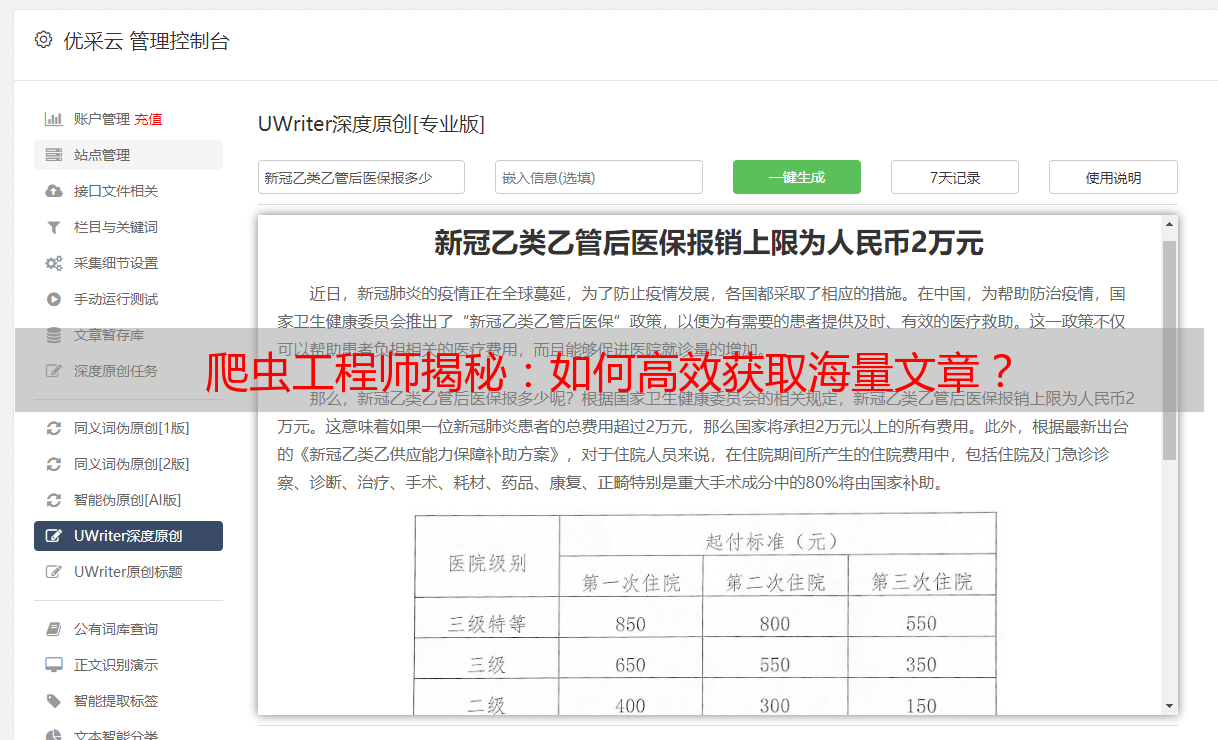
基于深度分析得出网页结构特征,我们有选择性地运用面向Web的编程语言(例如Python、Java等)制定对应的爬虫规则。编码过程中,应重视请求报文头部调整、页面内容解析及异常预防处理技术的精进。
四、使用合适的爬虫框架
在处理复杂的网站时,优质的爬虫框架能极大提升我们的工作效率及稳定性。譬如,Scrapy就是其中一款卓越的Python 爬虫架构,该平台功能齐全且赋予开发者大量实用的工具及便捷功能,有效地缩短了整个开发流程。
五、处理反爬机制
为满足部分网站防爬取需求,必须熟练掌握防爬措施的应对之策。如调整访问频次,运用代理IP等策略以绕过反爬机制为要旨。
六、数据清洗和存储
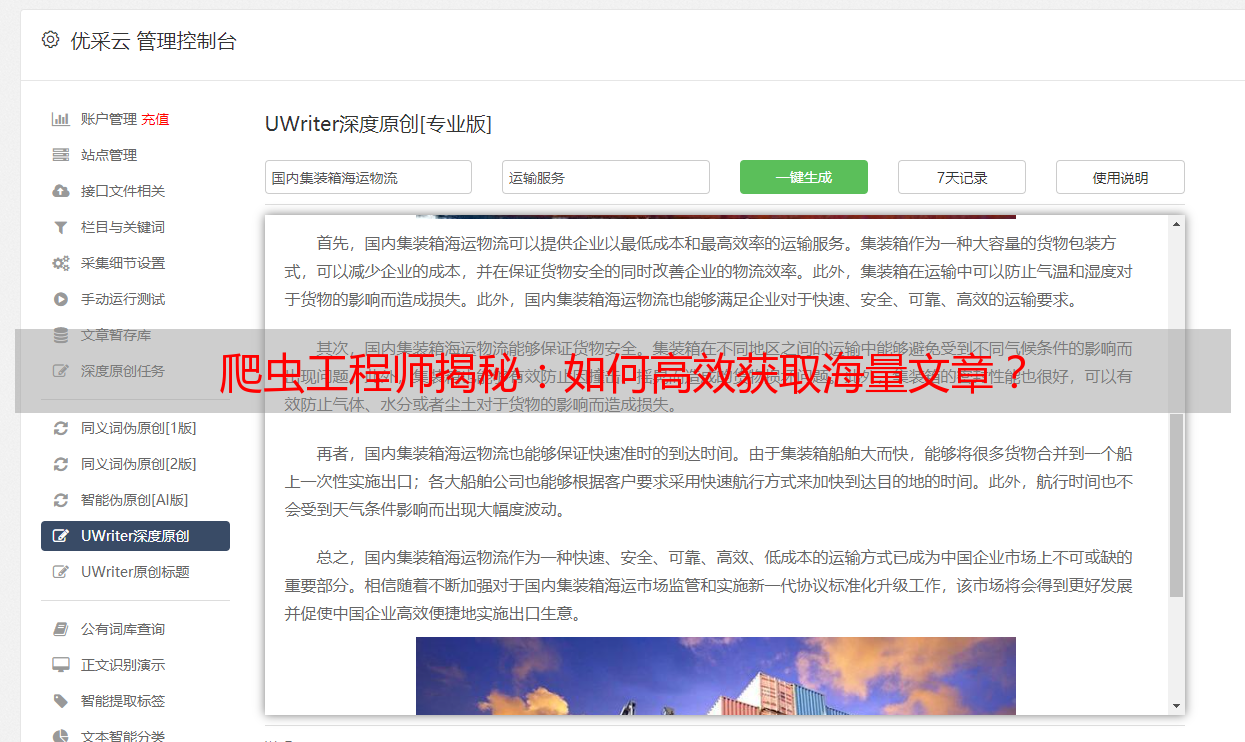
数据掘取完毕,须经过甄选和调整环节,具体包括剔除HTML标识符、消除冗余杂项及提取至关重要的资讯。待清理数据可同步存入数据库或输出至如CSV和Excel等兼容性较高的类型文件以供深入剖析与运用。
七、定期维护和更新
鉴于网页架构与防爬技术时刻变迁,故需持续修复与定制爬虫编码。适时调整以应对新版网页结构,妥善处置潜在异常现象。
八、遵守法律法规和道德准则
文章采集中务必遵守法律法规与道德规范。严禁侵权,尊重网站规定及版权信息。
有了以上八大实战经验的分享,我相信各位人士定能更为熟练运用爬虫软件进行文章采集工作。期望这些实践体验对您们有所启发和助益,同时谨记在操作过程中遵守相关法规,确保文章内容的合法性与规范性。

