爬虫采集之路:从入门到精通
优采云 发布时间: 2024-03-21 05:38一、初识爬虫
在现今这数字时代,信息获取日益便利。作为一名资讯爱好者,我对高效采集海量文章的方法产生浓厚兴趣,因此踏上了爬虫采集之路。
二、探索入门
学以致用,深入研究爬虫基础成为必要步骤。对HTML结构、HTTP协议及正则表达式这些技术有了深刻理解后,我进行了初步的编程实践。编写爬虫程序使我熟练掌握了网页解析与信息抽取技巧。
三、寻找目标
确立采编策略后,我随即展开网站搜索。经过深入对比分析,我精心挑选出若干专注于特定领域的网站进行测试实践。这些平台内容丰硕、展示架构清晰明朗,完全符合我所设定的需求标准。
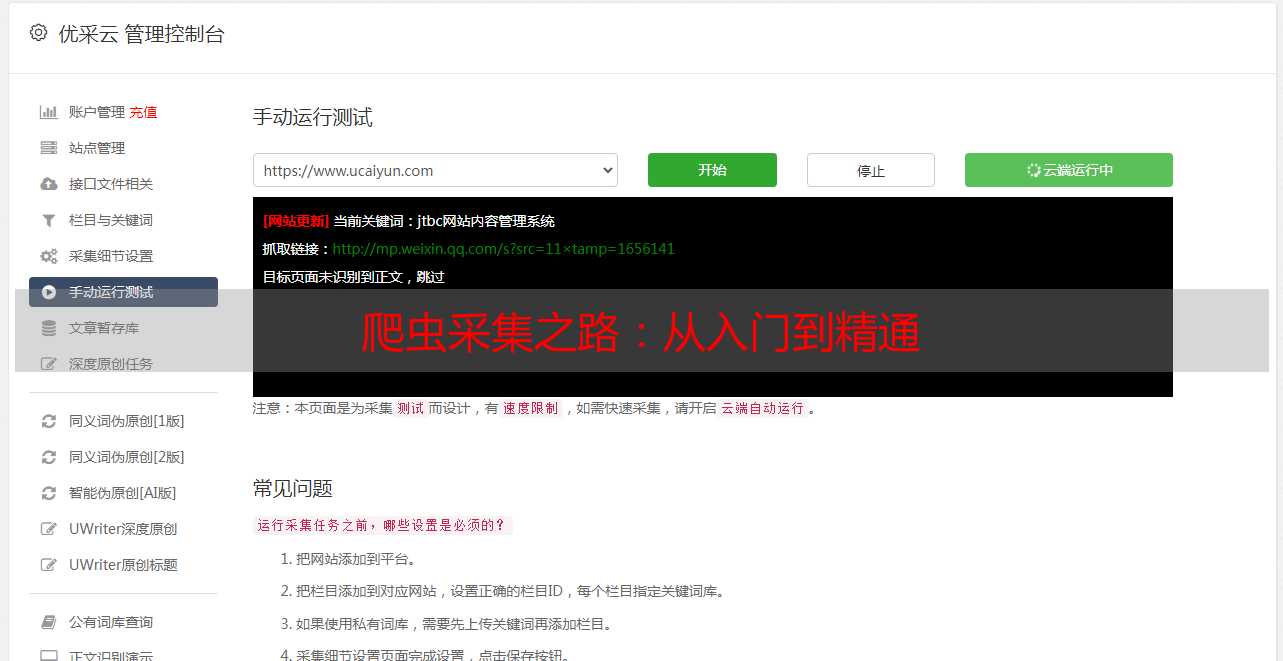
四、定制爬虫
基于目标网站特性,我对我的爬虫程序作了精心定制。通过剖析网页布局以及URL规则,我量身打造出适配的自动文章采集代码。此过程中,为预防封禁现象,我亦添加了有效的防护机制,以确保爬虫运行的稳定性。
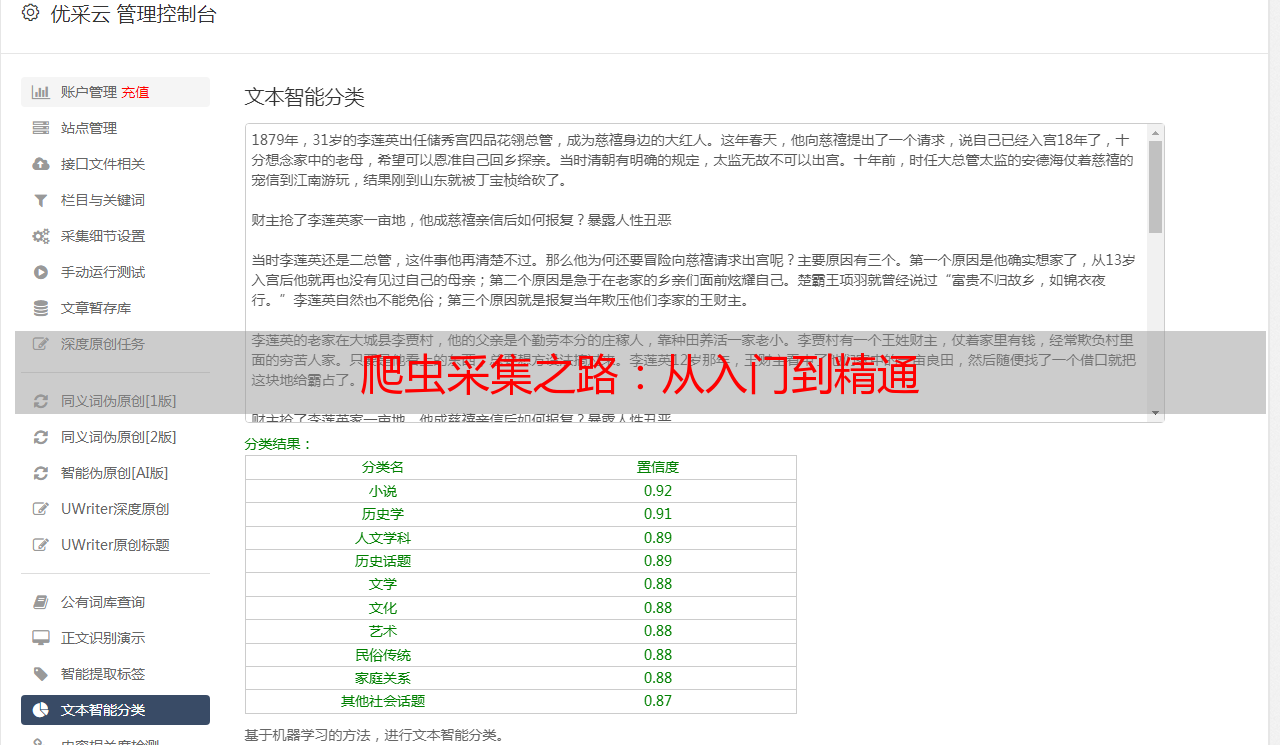
五、精准解析
运用高效精准的解析工具,能迅速抽取文章中的核心信息如标题、作者、发表日期等。借助于XPath、CSS选择器或正则表达式技术,能大幅度提高整理与分析海量文本的效率。
六、数据存储
为保证数据的妥善保存及处理评估便利,数据库被选作首选储存介质。此外,定期任务设定以减少数据冗余,并确保数据的时效性,对已收集数据进行修整更替。
七、挑战与优化
在实践过程中,我遭遇了诸多挑战与难题。例如,某些网站设立了反爬虫措施,使我的爬虫工作受阻。然而,经过持续的学习与优化,我得以逐步寻求解决之道,对爬虫代码进行改良,以提高其稳定性和效率。
八、成果展示
历经长久艰辛,我的采集系统已初步成型。成功收集大量文章数据后,我进行了细致归纳整理及深入数据剖析。此等数据不仅满足自我所需,更为他人呈献了宝贵的资讯资源。
通过深度实践,深刻感悟到爬虫技术之迷人与挑战。此过程令我对网络运作机制理解更为深入,同时增强了数据处理与分析能力。这种采集方式使我对信息掌握有了全新认识,也进一步加深了我对这一独特数字时代的喜爱。

