资深PHP工程师教你如何高效获取全网文章
优采云 发布时间: 2024-03-19 15:47一、概括
身为资深PHP工程师,笔者有过如何获取全网文章的独特经验。通过深入探索并不断实践,笔者建立了一套极为实用且高效的策略,现将其与大家共享。
二、准备工作
为有效执行采集行为,首先需准备稳固的服务器、可信代理IP池及相关技术工具(如Guzzle和SimpleHtmlDom)。这些设备及软件将保证我们的采集过程高效且准确无误。
三、选择目标网站
在搜集全网络文章信息前,首先要遴选一至几个我们关注且具备优质且频繁更新的目标网站作为参考。我们可利用搜索引擎、论坛等方式来找出适合的目标站点。
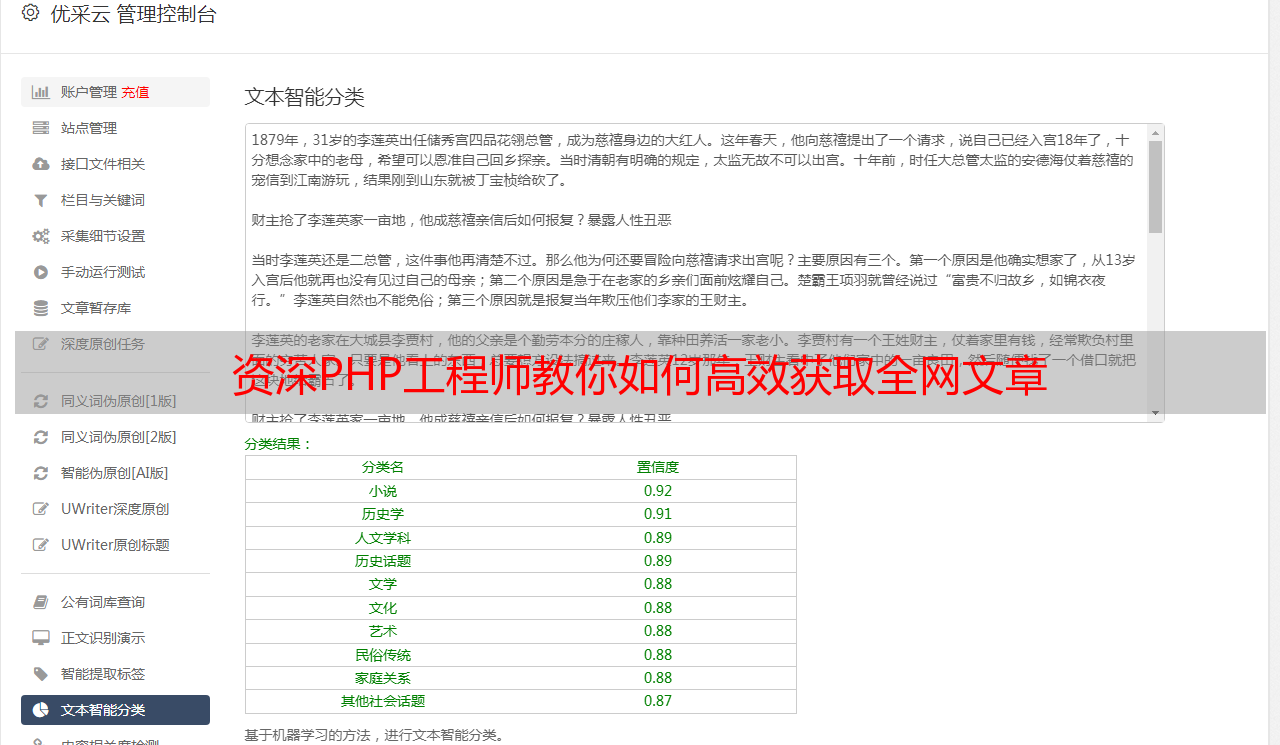
四、分析目标网站结构
在正式开始采集数据前,需对标的网站体系架构进行深度解析。采取观察页面源码及运用开发者工具类途径,可掌握该网站文章列表页与文章详情页的URL规则,及其相应元素所需的CSS选取器或者XPath表述式。
五、编写采集代码
针对目标网站的布局及规则,可撰写采集脚本。首要步骤为利用代理IP池规避防爬虫检测。接着,运用Guzzle库发出HTTP请求,辅以SimpleHtmlDom库解析HTML页面。通过循环浏览文章列表与文章详情页的URL,逐一提取各项文章要素,如标题、作者以及内容等等。
六、数据存储与处理
当文章数据被成功捕获后,有必要将其有效保存至数据库或其他保存媒介。此外,为了提高数据质量及应用价值,也能执行诸如数据去重、关键字提炼等技术手段。
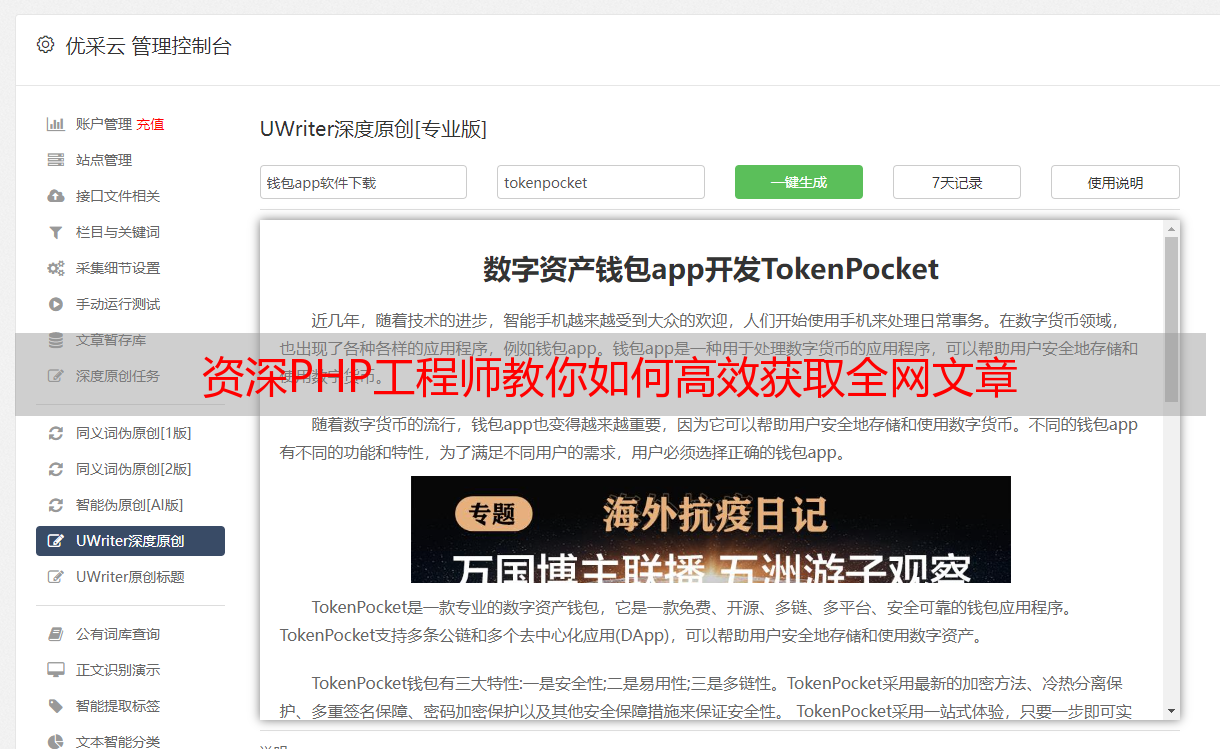
七、定期更新与维护
鉴于网络文章的时效性,数据采集要求定期进行更新和维护。针对目标网站任何形式的变更,皆需对采集代码做出相应调整,以适应当前的构造及规律。
八、注意事项与道德约束
在开展全面网络文稿捕获工作过程中,务必恪守相关法律法规及道德准则,确保不侵害任何人士之权益乃至个人隐私;此外,在获取相关数据资源时,亦需遵守适度原则,以免对目标站点造成过重负荷。
身为 PHP 开发人员,我在此分享有关采集全网文章的实践心得。期望这些经验能对广大技术同仁有所启发和裨益。愿我们共携手,探寻广阔无垠的网络世界,发掘丰富而宝贵的知识与信息资源。

