零基础学网站采集,轻松掌握自动搜集与发布技巧
优采云 发布时间: 2024-03-19 14:43本文将详述一种关于收集与发布网站相关文章信息源代码的设计理念,让各位读者深入了解如何通过该方式实现自动搜集与发布文章的操作功能。
1.网站采集是什么?
网站采集系统以程序驱动方式,获取并存储互联网数据至本地或其它指定平台。其主要功能包括自动化搜索、抓取以及文本整合等环节。
2.为什么需要网站采集?
网站采集可以大大降低人力与时间成本。借助自动化手段进行大批量文章的获取,以便于后续的处理及分析。
3.如何实现网站采集?
为实施网站内容采撷,需构造一套方案模拟浏览器访问所需目标站点,进而获取所需数据。当前可用的技术框架包括Python、Java以及PHP等,均可进行网站资料采集工作。
4.源码结构:
运用网站采集技术时,可采用开源框架或库来提升开发效率。以下为源码样本结构简述:
- main.py
- spider.py
-`main.py`:程序入口,用于启动网站采集任务。
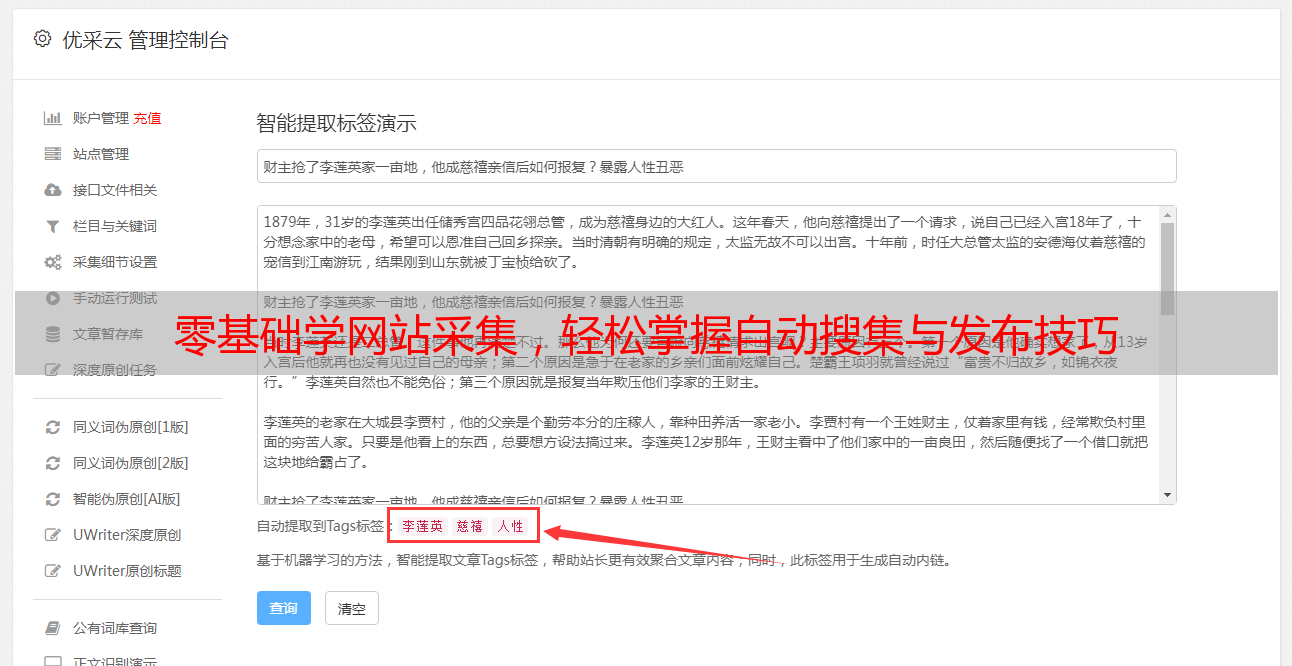
-借助于"config.py"文件,用户可设定你的采集任务中涵盖的目标网页以及采集相关规则等参数。
-`spider.py`:作为采集者的职能角色,旨在模拟真实用户浏览行为,从网站中挖掘提取特定需求的信息资料。
-`utils.py`:集各类实用功能于一身的类。
5.实现过程:
下面是一个简单的实现过程示例:
在`config.py`文件中设置目标网址以及相关采集规则
于`spider.py`文件内构建`Spider`类,实现网站数据抓取功能。此类需包涵如下四种方法:
`__init__()`:用于设定初始值,包括请求头部及代理等关键参数的设定。
`get_html()`:执行HTTP请求,获取页面源代码。
-`parse_html()`:利用其将网页源代码结构化,以获取所需数据。
-`save_data()`:将所取得信息存储至本地或指定目标地点。
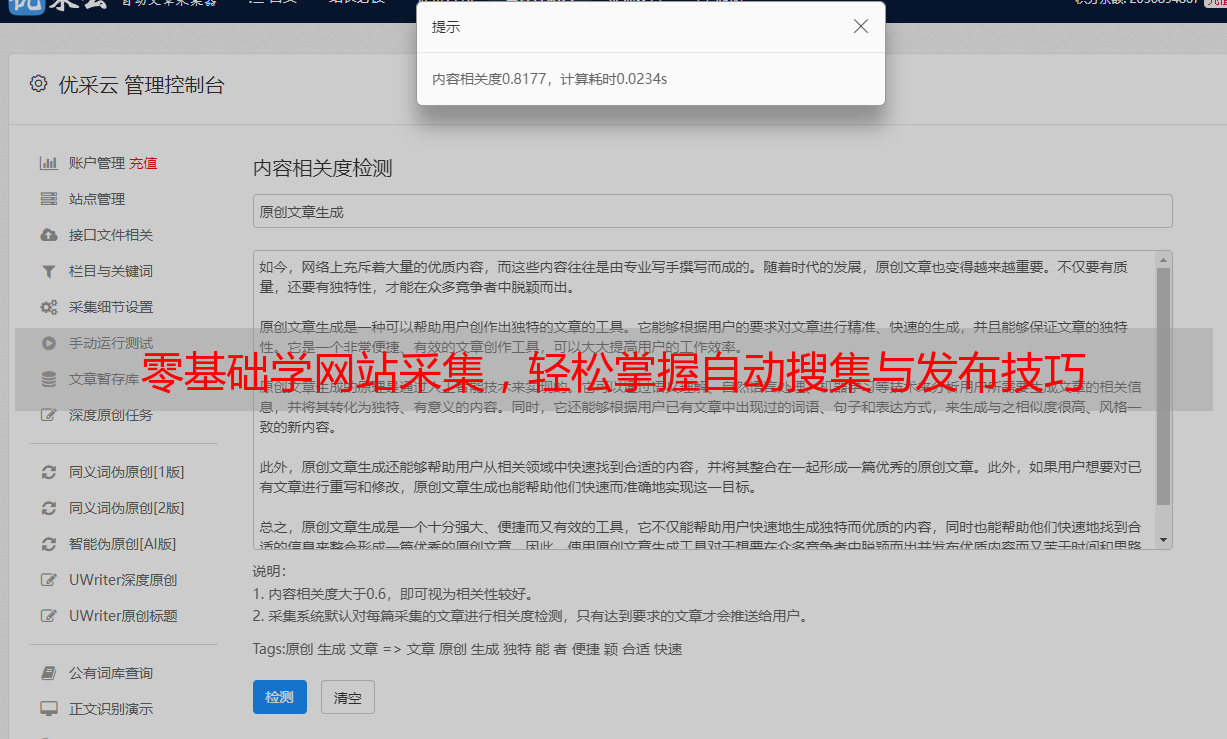
6.注意事项:
在进行网站采集时,需要注意以下几点:
-尊重网站的爬虫规则,并遵守相关法律法规。
-避免对目标网站造成过大的访问压力,以免影响其正常运行。
-定期更新采集规则和代码,以适应目标网站的变化。
7.其他应用:
除了文章搜集之外,网络爬虫技术亦可广泛运用于数据解析与舆论监控等领域。借助自动化抓取手段,我们得以迅速检索并收集海量数据,以便展开深度分析及深度探索。
8.总结:
本文讲解了利用源代码实现网站带采集文章功能的方式,以助您深入理解如何进行自动化采集与发布文章的操作。恰当地运用网站采编技术,不但能显著提升工作效率,节约宝贵时间,还可为深度数据分析提供强有力支撑。
9.参考资料:
-《Python网络爬虫权威指南》
-《Python网络爬虫全程指导》

