网站自动化采集:实战经验大揭秘
优采云 发布时间: 2024-03-16 07:57本站的自动化采集功能独树一帜且功能卓越,为我们在信息海洋中指引航程。作为资深网页抓取工程师,我在此与众人探讨并共享积累的实践经验和深入洞见。希望这些宝贵经验将对那些探索或使用该技术的人士有所启迪。
一、选择合适的目标网站
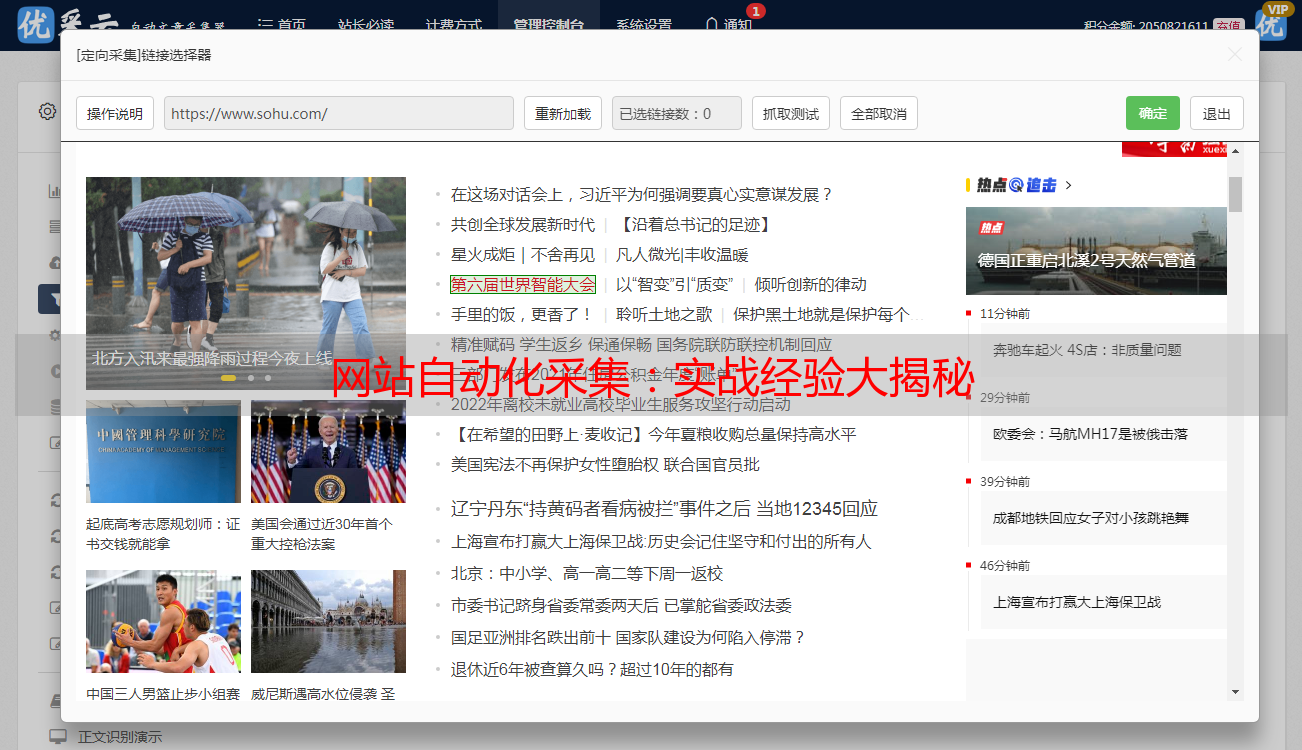
实施网站自动化采集之初,要务首于定立可靠且具有可操作性的信息访问策略。务必慎重选择目标网站,因为这将直接决定所求数据能否顺利获得。评估目标网站的结构布局、质量及更新速率等多重因素,有助于做出妥帖的决策。
二、制定详细的采集计划
正式采集实施之前,务必确立完整且科学的采集策略。其核心内容在于确定有效抓取的网页及所要提取的关键数据字段,同时,兼顾采集周期以提升执行效率,杜绝无谓的繁复操作。
三、编写高效的爬虫程序
网站自动采集效果的优劣取决于高效爬虫软件的研发。熟知各类主流爬虫框架及其工具链至关重要,以多线程、分布式等前沿技术提高采集速度。另外,合理控制请求间隔并撰写正确的请求标头,以规避目标站点的封锁策略。
四、处理反爬机制
众多站点已经实施了多样化的防爬措施来抵御系统的数据抓取行为。因此,理解并掌握如何有效地规避这些机制显得尤为必要。以下是常用的应对策略:模拟用户登录、使用代理服务器及设置随机请求头部。
五、数据清洗与存储
原始数据清洗和归类乃实现精准资料提取的关键环节。利用正则表达式和XPath等先进技术,可成功提纯并筛选所需数据,进而归整妥善处理过的讯息至储存在数据库或文档中,以便进行深度的后续研究及其实际应用。
六、定时更新与监控
由于诸多网站信息会实时修改,因此有必要实施常态化的数据收集与更新的工作,此举可借助定时任务或消息队列等工具实现自动化过程。此外,为了保证数据采集中出现问题的时候能及时得到解决处理,管理一套完善的监测系统尤为关键。
七、合法合规操作
在网站自动抓取过程中,严格遵守法律法规以及尊重目标站点的使用条款至为关键。维护他人的知识产权和隐私权既是我们身为采集者的应尽义务,同时也是不可忽视的责任。因此,在执行每项任务之前,请务必认真研究并遵守相关规定。
八、持续学习与技术更新
凭借网络数据实时采集技术的迅猛发展,新型工具和战略也在此过程中不断涌现。因此,从业人士需怀揣不断学习的理念,保持对行业趋势和技术变革的关注,从而在日益激烈的市场环境中立于不败之地。
九、分享与交流
综观全局,共享共通乃关键所在。在网站采集过程中,与同行携手探索学习乃无价之宝。参加各种科技研讨会、论坛及社团活动,皆能拓展人际圈,借鉴他人经验以利于自我提升。
期盼此经验启示能为即将涉足网页自动搜集领域的同仁带来深远影响。在当今资讯过载之世代,通过精湛的自动搜集技术,我们能够方便快捷地获得众多有价值的数据资源。愿我们携手共讨,深挖这个取之不尽的知识宝藏!

