PHP架构师教你无刷新采集神器
优采云 发布时间: 2024-03-09 20:19身为资深 PHP 架构师,今日与大家探讨运用 PHP 获取无需刷新的文章的独到心得。
-简介:介绍无刷新采集文章的背景和意义
-选择合适的采集工具:推荐几款常用的PHP采集工具
-探究目标网站框架:剖析目标网页 HTML 结构,明确需采集对象
-构建采集脚本:运用PHP技术编写采集脚本来实现无需刷新的数据采集。
-加强防爬措施设计:阐述我们应对网站反爬措施策略,以确保数据采集稳定性。
-数据维理及储藏:对收集所得的数据进行精密操作及妥善保存,确保数据品质与可访问性。
-定期升级与维护提示:为适应用户目标网站变更,建议定时核实并更新采集脚本。
-操作指南与技巧:提供关于提升采摘高效性与稳定性的注意事项及技巧说明
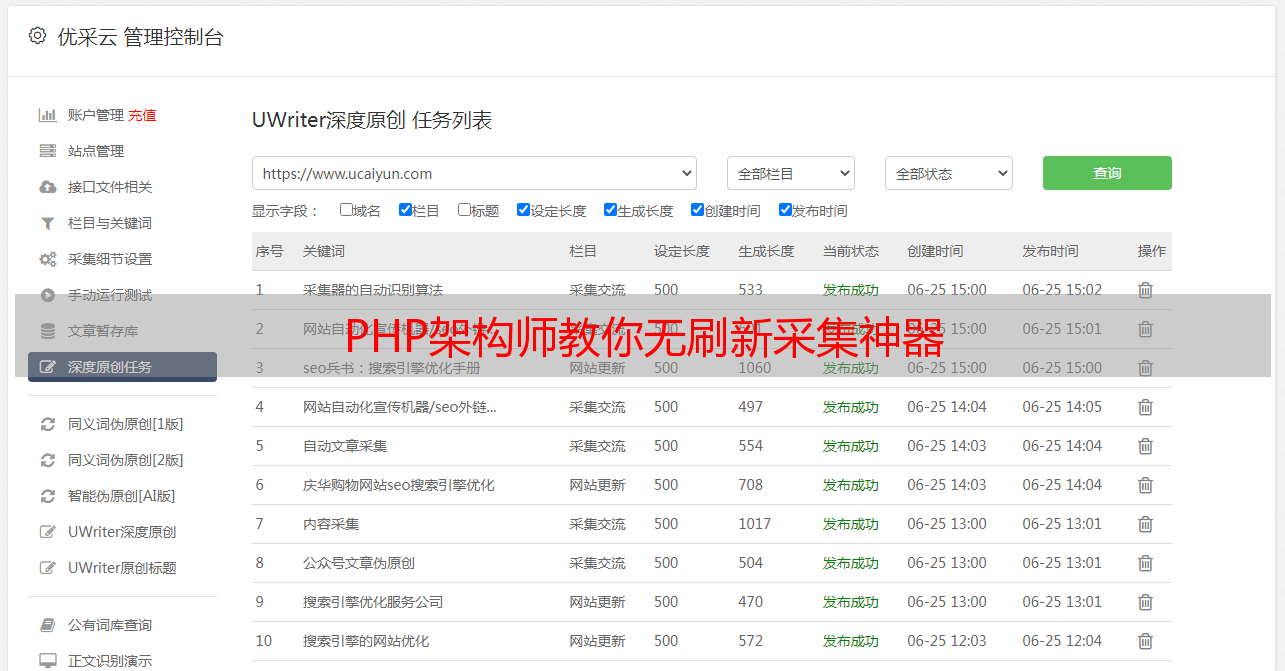
随着网络时代的来临,这个充斥着海量信息的空间带来了人们获取所需知识和信息的需求。然而,繁琐的手工复制与粘贴操作却无法满足这一需求,这种方法显得既低效又乏味。正是因为这种因素,自动化信息收集工具应运而生,帮助我们摆脱繁琐,提升工作效率。
选择合适的采集工具:
在php应用中,主流的抓取工具包括Guzzle和Curl,它们均具备高效HTTP请求能力,并支持多线程及cookie管理等多种特性,充分满足了无刷新的文章采集中的各种需求。
分析目标网页结构:
正式启动采集之际,务必掌握待采集页面的HTML结构,明确所需采集信息。借助浏览器的源码解析或开发者工具等途径,您便可锁定其中含有必要数据的HTML标签以及CSS选择器。
编写采集脚本:
运用PHP编程技术构建采集脚本能助力于实现在线采集文章且无需刷新的功能。首要步骤在于,应用采集工具向目标页面发出HTTP请求以获取其HTML源代码;其次,对于得到的原始文本进行深入分析,主要运用正则表达式或XPath的特殊规则提取所需数据。
增加反爬虫措施:
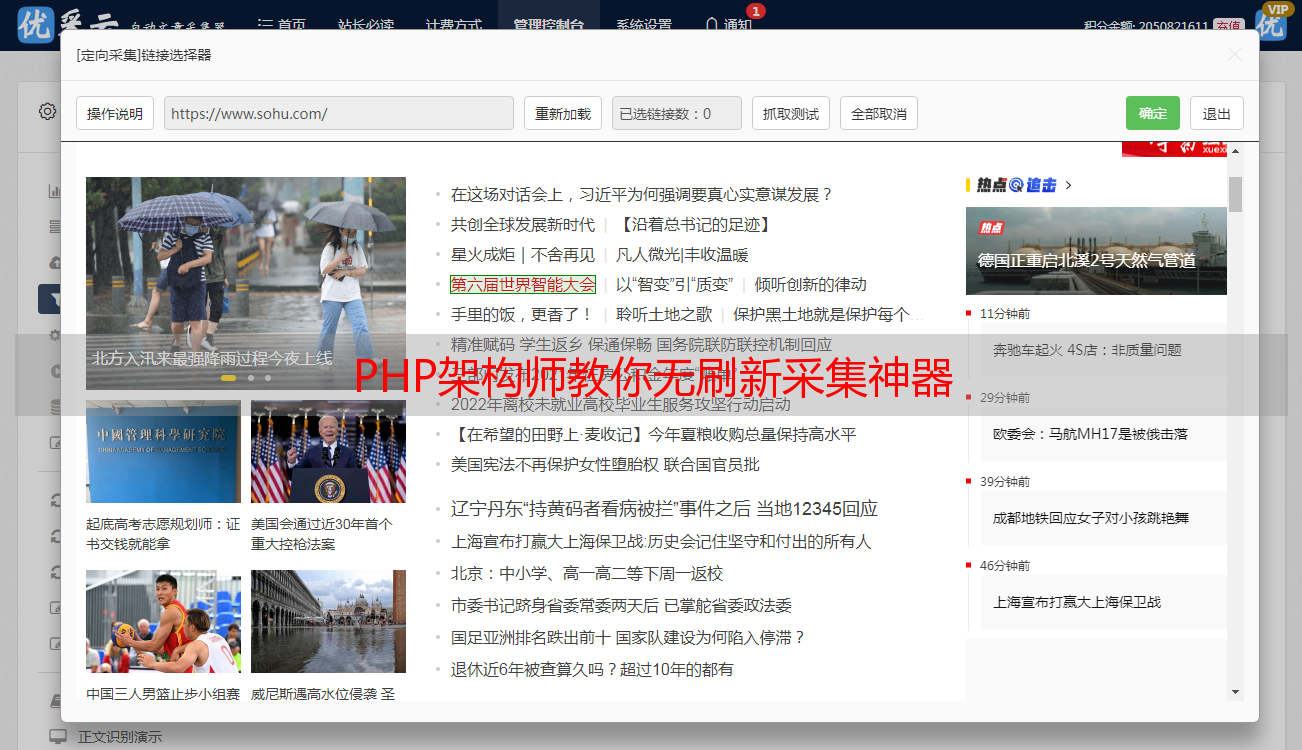
针对即定网站的潜在防爬策略,通过调整HTTP头部的User-Agent与Referer,以及控制请求频率和延迟时间。
数据处理与存储:
收集的数据需经过妥当处理与存储。运用字符串处理技术及正则表达式实现数据清洗与提炼,最后将得到的成果储存至数据库或文档之中。
定期更新与维护:
鉴于目标站点的变动性,有必要定期审查并升级摘抄脚本来应对站点布局及防爬虫措施的调整。与此同时,须确保摘抄脚本运行平稳,及时解决异常状况。
注意事项与技巧:
在实际采集环节,需关注诸多技术细节与策略。如设定合适的请求头信息、解决编码难题、利用代理IP等等。此外,恪守网络道德准则,严禁恶意采集及滥用数据。
遵循上述方法与策略,我们有能力运用PHP技术创建并实现无需刷新的文章采集功能。期望我的实践心得能为各位带来实质性的协助。

