网页数据一键搞定!HTML文章采集工具带你飞
优采云 发布时间: 2024-03-08 02:35HTML,全称超文本标记语言(HyperText Markup Language),是构成网页的基石。面向那些需从网页中提取特定数据的人士,HTML成为一项极具价值的工具。在此文中,我们将为您展示一款高效且便捷的HTML文献采集工具,助您快速获取所需信息。
1.背景介绍
随着网络科技的发展,我们每日都要访问形形色色的网站,从中获取所需的各类资讯。但手工复制并粘贴这些信息显然耗时且繁琐。为了改善这一状况,众多精通软件开发与科技探索的人才研发出各种HTML文章采集工具,助力用户自动提取网页中的关键信息。
2.工作原理
本文档介绍了一种HTML文章采集工具,通过解析网站HTML源码以抽取特定目标信息。仅需输入相应网址与所需内容匹配模式(如CSS选择器、XPath表述或者正则表达式),该工具即可自动识别并获取相关信息。
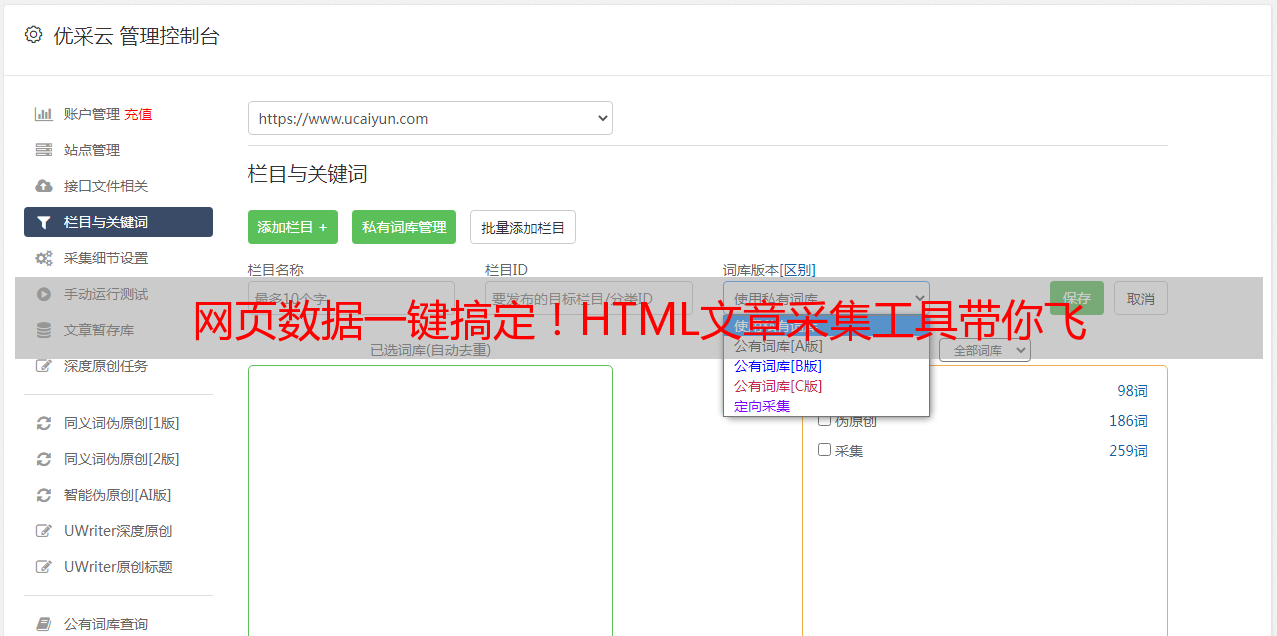
3.使用方法
运用HTML文章采集工具有其简易性。首先,需确定适配自身需求的工具。市场上既有免费又有购买等选项,如Octoparse和ParseHub等。其次,所需工具需正确安装及启动。至此,可填写目标网址并填入工具保有的功能以设定规则,预备完毕后,按下运行即可让工具自动采集和保留数据。
4.实际应用
文档采集器于诸多领域均大展身手。如市场调研方面,此类工具可协助搜寻竞品信息与定价策略;舆情剖析环节,同样有助于收集新闻网站及社交平台上的观点以理解公众对特定话题的反应;若涉及学术研究,便可用其搜集相关文献资料或数据信息。
5.注意事项
在应用HTML文章采集工具过程中,有几个关键要求。首要原则是遵守网站规定及隐私保护准则,严禁滥用采集工具;其次,需建立合适数据提取策略,保证采集数据精准完整;最终,务必及时升级工具,以期提升用户体验与功能完善。
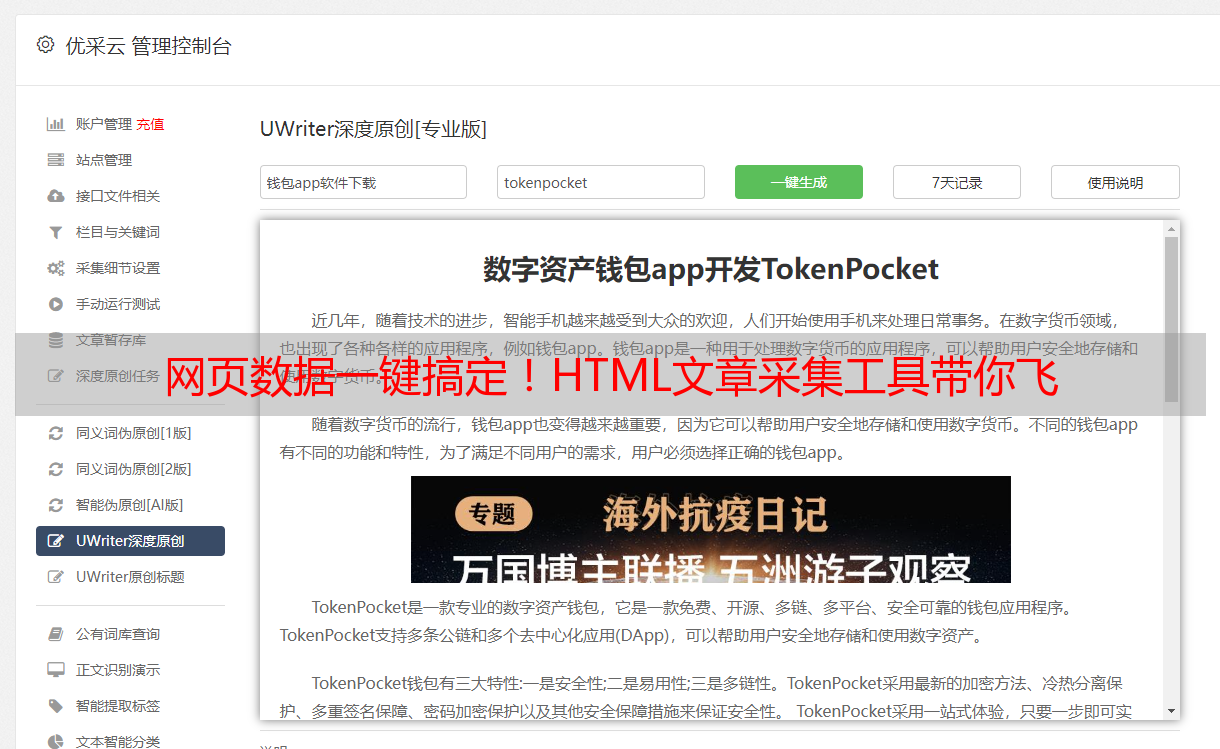
6.工具推荐
尽管市面琳琅满目的HTML文章采集工具繁多,然而本人仍旧倾向于倾情推荐几个品质出众的代表作。首推的就是,具有雄厚实力与亲民易用双重特质的Octoparse,其广泛地满足各类数据搜集需求。其次,则为功能卓越且配备优越用户体验的ParseHub,其支持用户自定义化数据提取规则,极大简化操作流程。
7.学习资源
若您对 HTML 文章抓取器产生浓厚的好奇心并且愿意深入研究与理解其相关知识点,以下提供的学习资源有助于您:
在知乎此类权威性技术交流平台检索关键字,便可获取许多优质的图文资源及讨论。
-查阅在线教育平台上与网页数据采集、Python网络爬虫相关的课程资料。
-阅读相关书籍和文档,如《Python网络数据采集》等。
8.总结
海量文本发掘工具乃高效实用之利器,助您轻松收集所需信息。在运用过程中,须恪守网站规定及隐私政策,合理设定数据搜集规则。通过深入研究相关领域并熟练掌握技巧,便可有效利用此工具以实现个人需求。期待作者此文对您有所启发!

