深度探究:高效文章自动化采集源码实用操作建议
优采云 发布时间: 2024-03-06 12:53在长期积累的行业经验中,我始终专注于深度探究及实践构建高效文章自动化采集源码的策略。经过不懈努力,我得以深入研发出一套实用性极强的方法与资源,以协助广大用户迅速提取并规范处理海量文章数据。本文将详细论述我宝贵的心得体会,同时也将为您细致讲解该源码的基本运行机制和实用操作建议。
一、需求分析
首先,在开发各类软件及工具前,务必要明晰自身所需。对于文章自动采集源码而言,关键需求主要集中在以下几个方向:
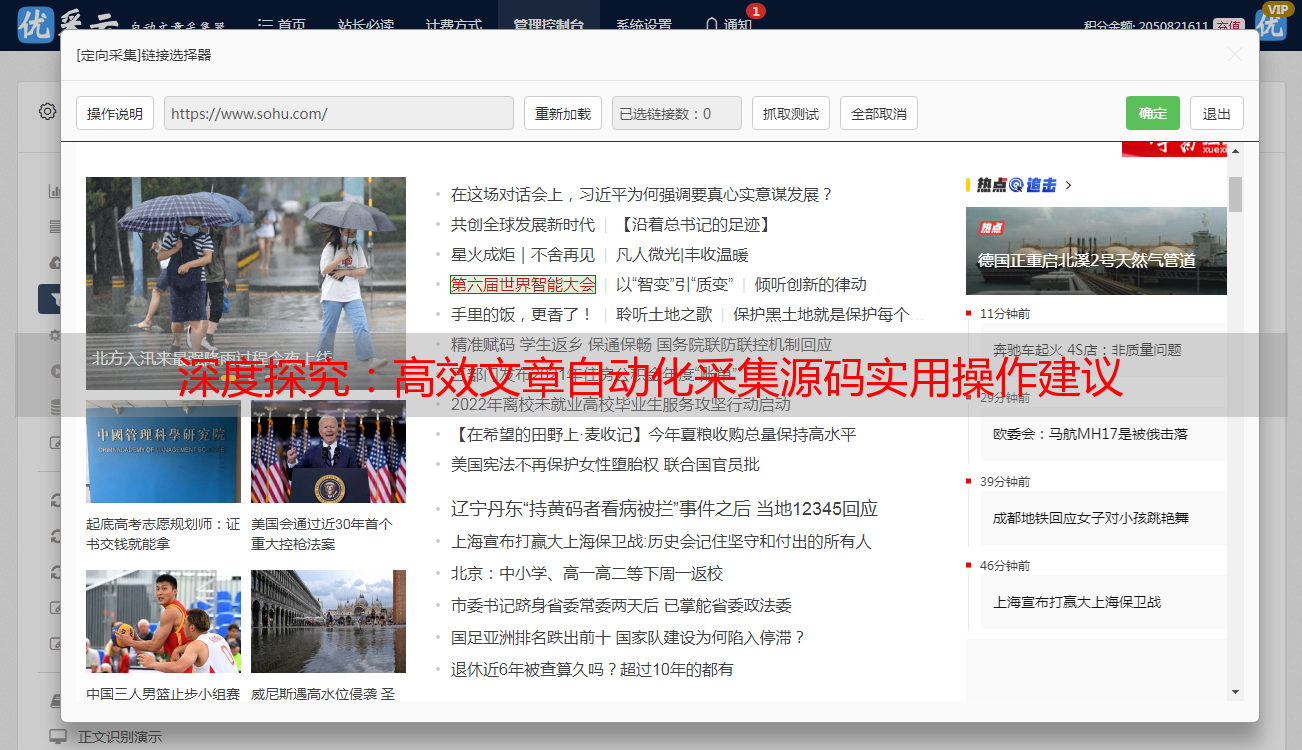
数据采集源:明确采集文章所依托的媒介平台,包括但不限于各大网站、论坛、博客等。
确立数据类型:明确需求采集的元素类型,诸如文本、图像、影音资料等等。
数据规模:设定所需收集数据的规模,比如每日采集包含100条、1000条甚至更多数量。
4.数据整理:确定采集到的数据如何进行整理和存储。
二、技术选型
依据需求分析成果,我们有资格选用适当的技术以完成文章自动抓取程序代码。在此,我向您推荐几种常见的实用技术:
网站搜集工具:运用Python的爬蟲模塊(例如:Scrapy,BeautifulSoup),能迅速剝奪網頁文章數據。
数据管理:为传输来的数据选择适当的数据库,如MySQL或MongoDB等。
数据处理:通过使用Python高效的数据处理模块Pandas以及NumPy等,实现对采集数据的精准清洗与深度分析。
三、源码开发
根据选用之术,我们可着手研发自动采集文章代码。以下为规划的关键步骤:
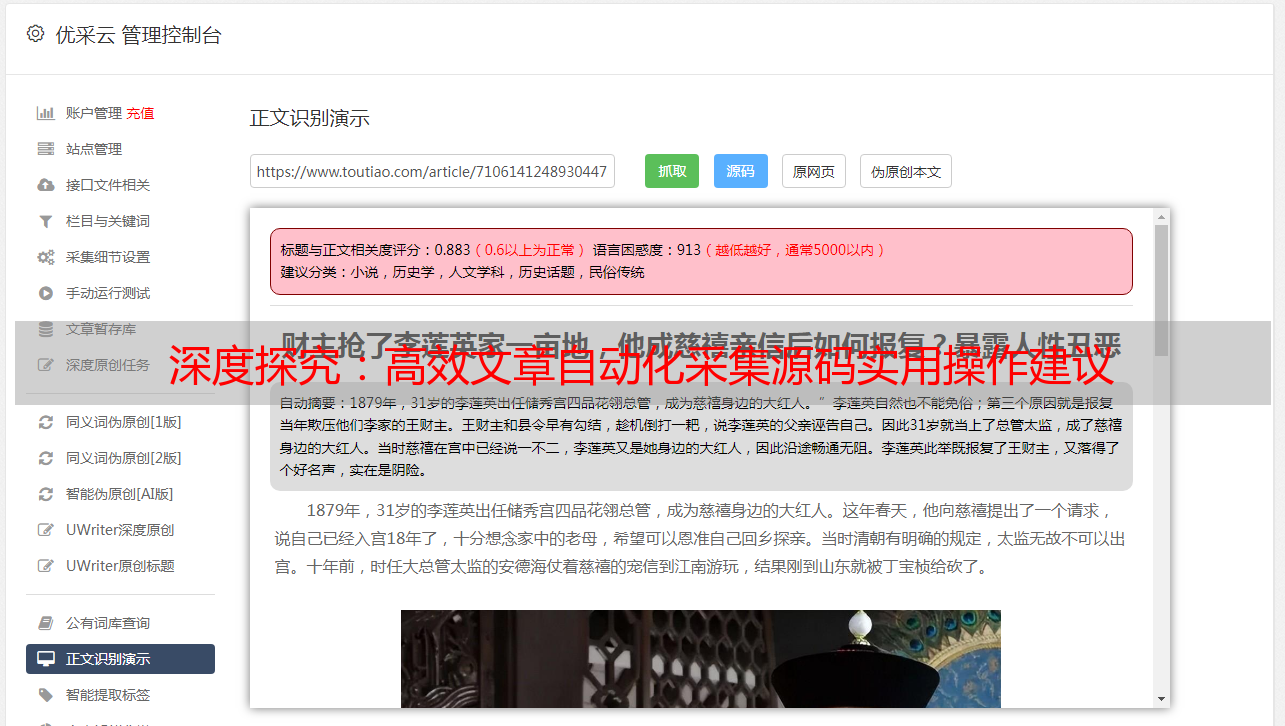
网页剖析:依目标网站HTML构造,运用爬虫框架精准解析获取所需数据。
数据存储:针对解析后的数据,依据标准化规则进行规范化处理,随后,将其导入数据库内,为方便下一轮检索,构建相应的索引。
定时任务设定:采用定期执行代码的方式,确保数据的实时性。
异常处理:解决网络异常及页面解析问题,以确保源码的稳定性与可靠性。
四、优化与改进
当核心代码编撰完毕,依照实际应用场景予以调整与升级十分关键。下述几点优化策略值得重视:
并发机制:通过使用多线程或协程实现高性能,提升源代码的数据采集效率。
应对措施:依据目标网络的防范机制调整我们的策略,诸如更换代理IP、设定请求头部参数等手段来完成。
数据处理:对所收数据进行筛选及去除重复部分,以保障数据的优良和精确度。
数据解析:运用数据操作软件针对搜集得来的数据展开深入的统计与剖析,筛选出具有宝贵价值的消息。
五、使用案例
为展示文章自动采集源码的实用性,特举实例分享。某知名电商期望获取消费者在各类社交媒体上发布的产品评价,进行深入情感剖析。借助于文章自动采集源码,该团队有效捕获了海量用户评价,开展情感分析,为此取得了宝贵的市场洞见。
六、总结
由长期实践积累所得,我深信文章自动采集源代码之独特价值在于迅速收集并整合海量文章信息。在开发过程中,需求分析、技术选择、源代码创建以及持续优化与改良至关重要。期望此篇经验分享能对阁下研发高效文章自动采集源代码产生积极影响。
本文即为关于文章自动采集源码的实践心得共享,倾力助您理解掌握。若您有任何疑问或建议,请随时留言互动!

