PHP神器!零基础学习,轻松采集网页内容
优采云 发布时间: 2024-02-25 14:45本文旨在与您分享一种使用PHP完成文章采集的简便方法。借助于PHP卓越的强大功能及高度灵活性,即使面对无规则的数据结构,也能实现所需的文章内容采撷。
1.基础准备
为了顺利开展,请确保您拥有安装有PHP系统且具有简单编程经验的服务器设备。此外,需安装cURL及SimpleXML等 PHP扩展以方便后续编写运用程序码。
2.确定目标网站
在抓取网页信息前,请务必选好目标网站。选择信誉优良、运行稳定且含有丰富高质内容的网站是关键,并遵循他们的使用规定及相关法律。
3.分析页面结构
为了确保顺利采集,请您首先对目标网站进行严谨的页面结构剖析。您可以通过查看HTML源代码,熟悉其页面排版、元素选取以及数据所在之处,这些都有助于我们编写精准的代码以获取所需文章。
4.使用cURL获取页面内容
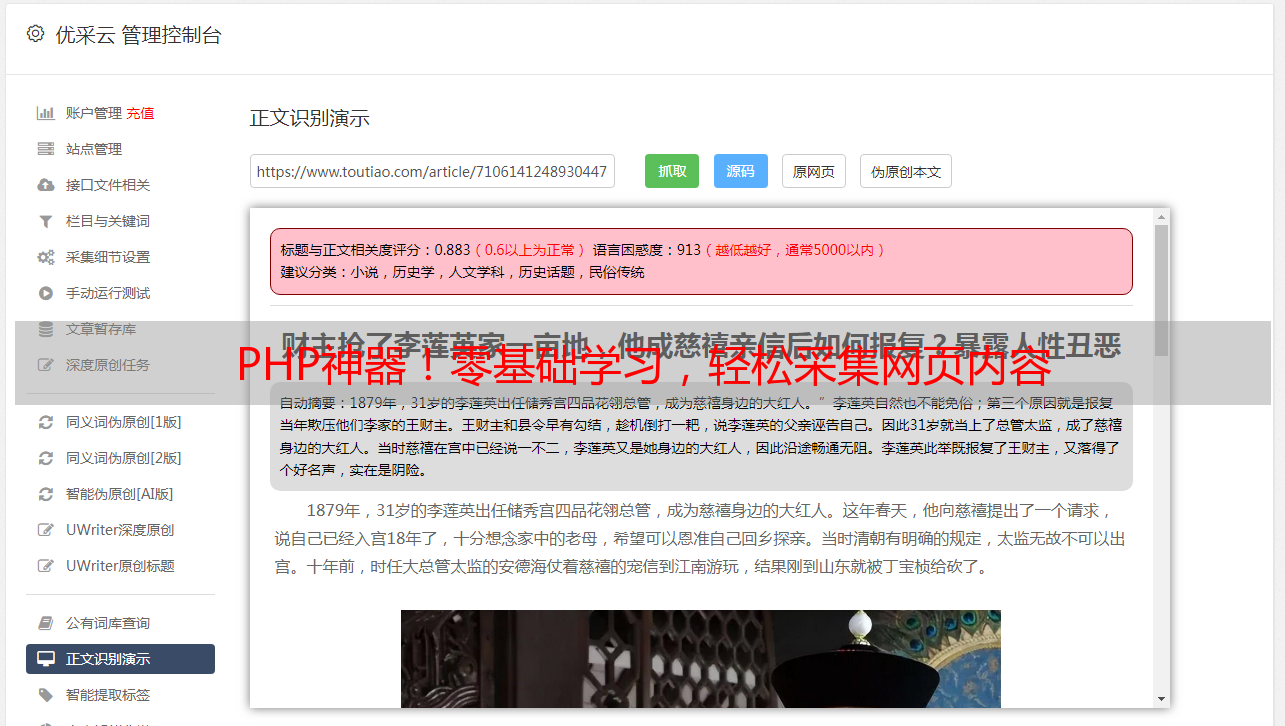
用了cURL库后,就可轻而易举地获取目标网页的HTML代码了哦!通过设定恰当的请求头信息,提供合适的参数,妥善处理Cookies,我们就能模拟出浏览器的行为呢,最后得到完整的网页信息。
5.解析HTML内容
尊敬的读者们,当您获得了网页的HTML代码之后,我们推荐用PHPDOM解析器或者正则表达式来精准提取您所关心的文章内容。利用页面框架与元素选择,轻松找到并提取包括标题、主体文字、作者及发表日期在内的各类资讯。
6.清洗和处理数据
提取完文章内容后,通常会涉及到一些处理步骤,如清除HTML标记、滤除特殊字符、调整日期样式等。通过巧妙地编写相关代码,原始数据将被转化成更清晰易用的格式。
7.存储数据
在提取和处理完文章数据后,接下来就是决定如何妥善安置这些宝贵资料。我们有两种选择:利用数据库来储存这些数据,或是把它们导出成易于管理的CSV或JSON格式的文件。具体的选择应因地制宜,依据实际情况而定。
8.自动化采集
如果您有定期采集文章的需求,不妨运用自动化技术来简化流程哦!只需设定定时任务或者利用PHP脚本触发采集功能,就可轻松完成自动化采集,把握最新鲜的文章信息。
9.注意法律和道德
寻章取义之际,务必尊守相关法纪,秉持公道良心。确保所选目标站点文章之权无虞,不侵害他方权益。并尊崇其版权及隐私声明之规定。
10.不断学习和改进
身为PHP开发人员,我们需要始终保持虚心好学及持续进步的精神。密切关注行业内新的技术、工具以及优秀的实践经验,从而持续优化我们的抓取代码。这样,通过不断地学习、实践,我们就能够提升抓取的效率与质量。
期待本次分享能帮到对 PHP 提取无规则文章有兴趣的您。学习一些基础知识与技巧后,相信您也能够顺利从各大网站获取需要的文章信息。祝您采集之旅愉快!

