PHP爬虫实战指南:从安装到数据处理,一文搞定
优采云 发布时间: 2024-02-20 11:18尊敬的读者们,生活在一个信息爆棚的时代,我们无时无刻不面临着浩如烟海的文章阅读需求。在此,我以一位资讯从业者的身份,为您带来一份实用的PHP文章采集指南。希望这篇文章能助您一臂之力,让您更好地挖掘所需的文章。
一、准备工作
首先,希望您已顺利安装了PHP运行环境并熟知相关语法。此外,建议您装载实用且简易操作的第三方库——Goutte。
二、选择目标网站
首先,建议您确定要采集的目标网站类型,如新闻网站、博客或论坛等。在此基础上,确保选取的网站同意被爬取是必要的注意事项。
三、分析目标网站结构
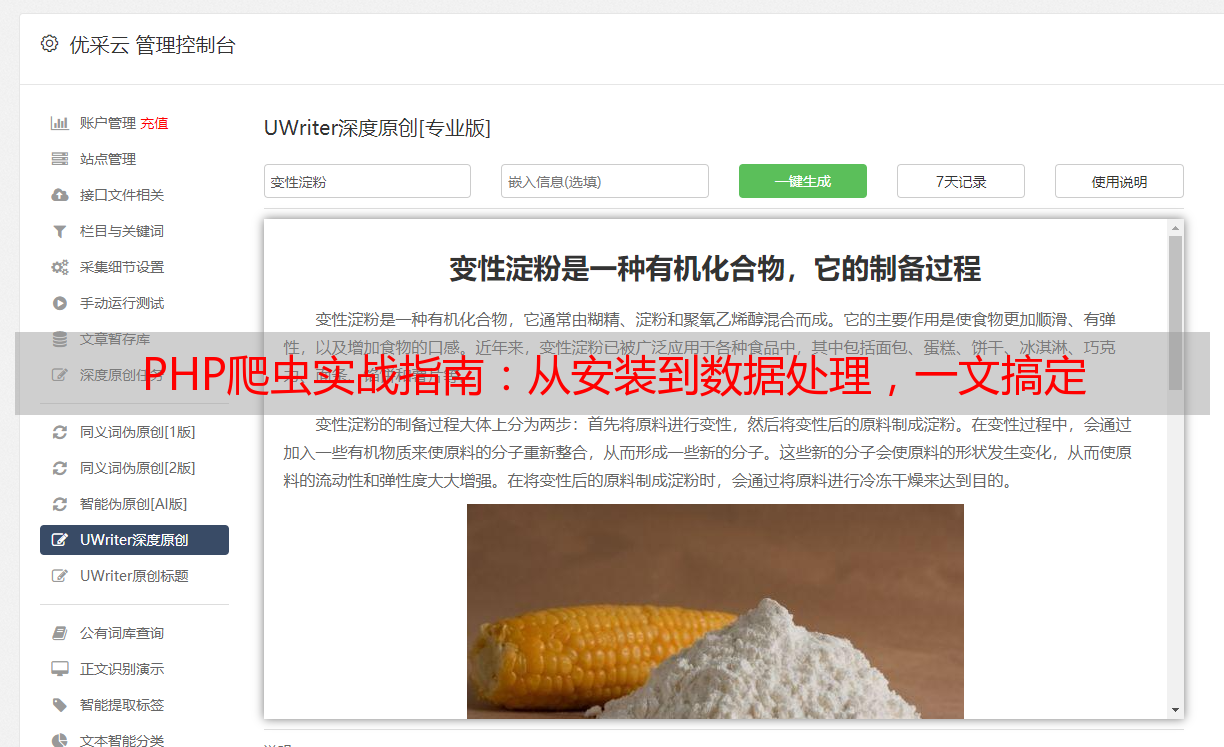
在动手敲码前,请务必先行了解并分析目标站点的架构,重点关注页面URL以及HTML元素定位等方面。这样能助您更高效地完成代码撰写工作。
四、编写代码
接下来,我们可以试着开始编写程序啦!首先呢,我们需要借助Goutte库来实现网页的请求和解析,然后借助XPath或者CSS选择器,根据特定网站的格式进行信息查找及定位哦~
五、处理数据
成功取得文章信息之后,可通过运用正则表达式或字符串处理函数等手段对其进行必要的数据处理。
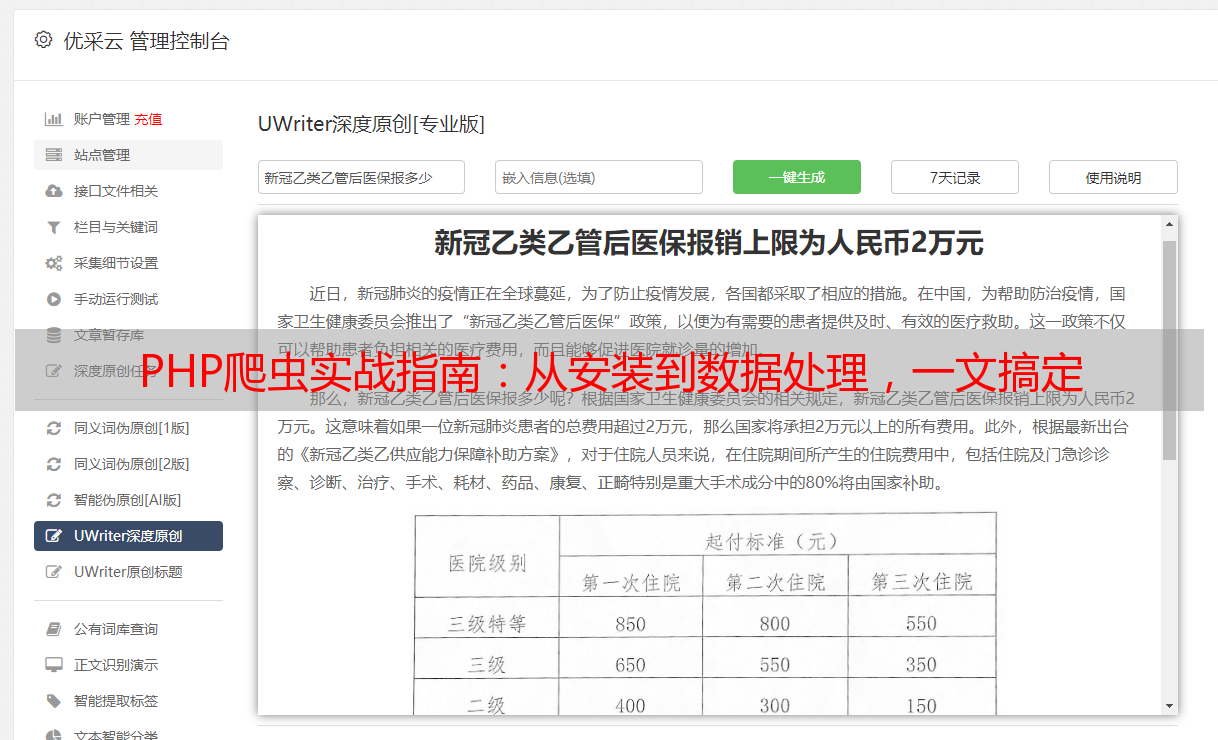
六、存储数据
我们有两种获取和保存文章信息的途径,您既可选择将其直接输出到屏幕上,亦可用MySQL数据库进行储存。在此,个人建议您考虑选用MySQL数据库来妥善保管宝贵数据。
七、定时任务
如果想定期获取文章,我们可以启用定时任务来实现。简言之,只需设定一个定时脚本,便能让采集程序在预设的时间自动运行,并将数据妥善保留。
遵循上述七大环节,便可轻松构建出简单且实战价值极高的PHP文章采集程序。请切记,实际运用过程中还需关注诸多细节并妥善解决。希望此番经验分享能为您提供启示。善用科技手段可使工作效果更上一层楼哦!

