如何高效批量爬取网页文章?4个经验小窍门
优采云 发布时间: 2024-02-19 06:16批量爬取网页文章工作可谓是令人生爱又生恨。然而,面对日益增长的信息需求,对研究学者、学生或是数据分析专家而言,这项工作能为他们节约大量时间与精力。然而,如何有效实施批量采集,并不能轻而易举。以下是一些我所积累的经验与小窍门,希望能助您在这个过程中如虎添翼。
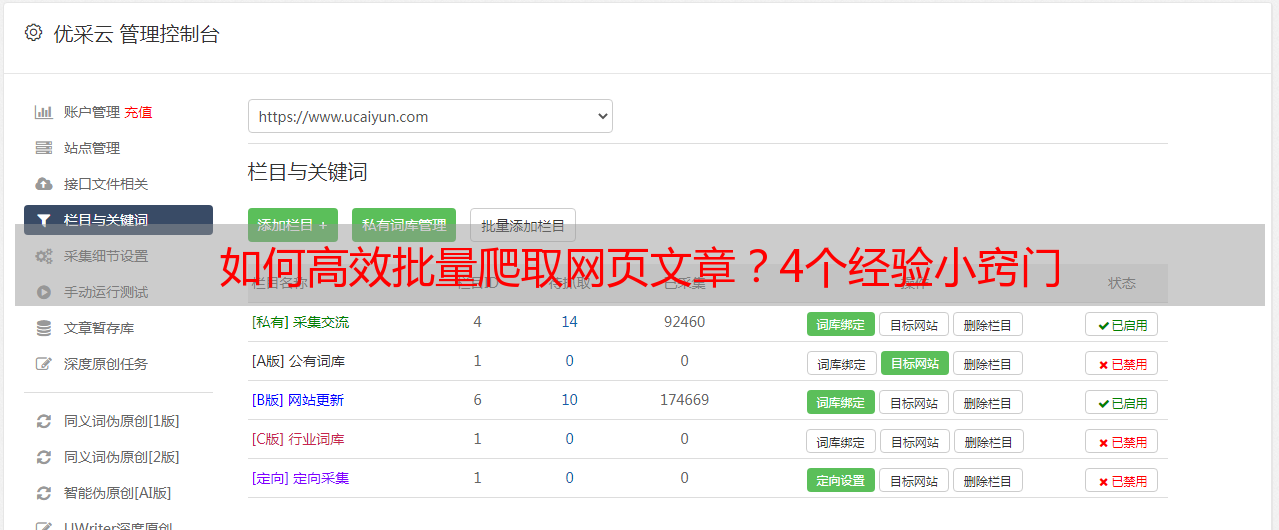
1.明确采集目标
首先,请您确定下您的采集中的主要目标。例如,只收集某一特定领域的文章,或是尽可能搜集广泛的各种文章;再比如,仅从某个特定网站采集全部内容,或专注于某些特定主题。只有明确目标,我们才能更准确地策划并实施采集。
2.选择合适的工具
挑选适当的工具确实能大幅度提升文章批量采集的工作效率哦!市面上有许多卓越的网络爬虫软件待您挑选,例如,众所周知的Python里的BeautifulSoup、以及Scrapy等等。请根据自身实际需求和技能水平选出适用的工具,并用心学习其应用方法吧。
3.编写抓取规则
在处理大量网页采集工作中,设定恰当的抓取规则尤为关键。一般来说,利用正则表达式或XPath便能有效地萃取出所需要的信息。熟悉并掌握HTML结构以及标签的基本知识,于设置抓取规则过程中将大有裨益。
4.设置合理的并发数
在采集大量网页文章的时候,适当设置并发数可以有效提升效率哦!因为过低的并发数会拖慢速度,而过高的数量可能会引起对方网站反爬虫机制的启动。所以呢,根据个人的网络情况以及目标网站的反爬虫策略,我们可以选择适合的数值喔!
5.使用代理IP
若想防止被目标站封锁 IP 地址,我们推荐您尝试使用代理 IP 进行大批量网页收集文章的操作。借助代理 IP 池这一工具,可采取轮换登入多台 IP 地址的方式,进而有效提升收集文章的成功率。
6.处理异常情况
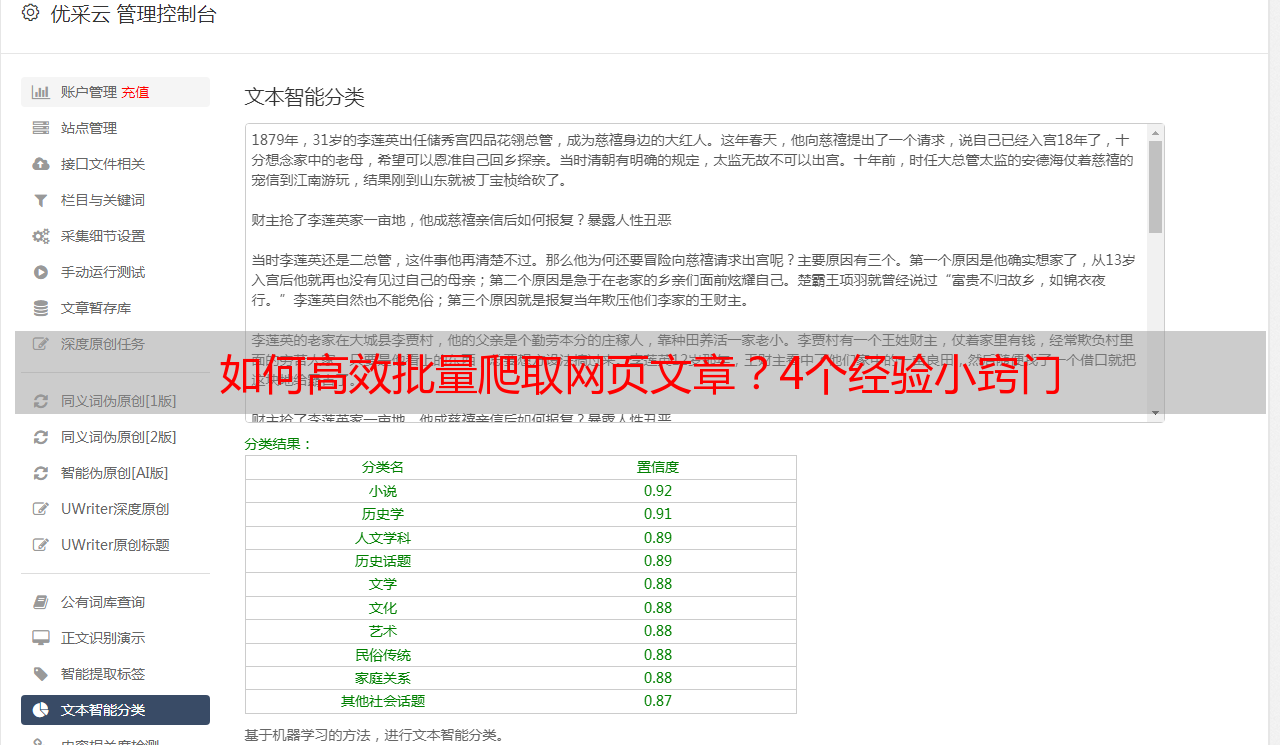
在大批量网页采集文章时,或许会遭遇网络连接超时或页面解析出错之类的情况。对此,您可以进行适当的异常处理编码,确保程序能自行处理异常并持续相关采集任务。
7.合理安排采集时间
为减轻目标站点压力,建议您在非忙时段进行批量采集文章。科学规划采集时间有助于降低被封闭的风险并提升采集效果。
8.注意法律和道德问题
如果您想要批量采集网页上的内容,请务必遵守相关法规和职业道德,铭记对知识产权的尊重。使用他人文章时,应明确标注来源与作者,以避免侵害他人权益。
9.定期更新抓取规则
当贵站改版或更新后,恳请您关注并适时调整我们的抓取规则以确保获取到最新鲜的文章内容。
选择一个适合的工具以提高效率,然后制定一个详实的采集规则,再设定适当的线程数量,这样才能有效而有序地进行大量文章的采集工作。在这个过程中,耐心与细致都是极为重要的。相信这些小技巧会对您的工作大有裨益!

