零基础学Python,轻松编写网站文章采集源码
优采云 发布时间: 2024-01-15 07:36身为一位专注于网络工程管理的工程师,我有幸接洽了许多种不同的需求,这其中包括网站文章采集。今日与您分享有关此话题的专业知识以及实践经验。
一、什么是网站文章采集源码?
本文中所提及的“网站文章采集源码”,即是根据预设的程序来自动收集其它网站的文章内容,将之存储于本地或其它数据存储设备中。这一技术有助于人们迅速掌握大量的信息资源,有效地节省了宝贵的时间和劳动力成本。
二、为什么需要网站文章采集源码?
深入研究:研究团队可藉由搜集其他网页之文类资料,开展数据剖析与探寻。
内容整合:我们会精心采集来自多方的优质文章,尽力为您呈现多元化的资讯内容。
爬虫应用:所需的网页数据,往往需借助文章采集源码的辅助,以可供搜索引擎及数据挖掘工具所使用。
三、如何编写网站文章采集源码?
尊敬的读者们,请依据自己对程序设计的基本了解以及您的特定需求来自由地挑选和学习Python、Java或PHP等任意能满足您要求的多种编程语言哦!
探索网络爬虫:了解并熟悉基本的网络爬虫运作机理以及相关的技能,比如HTTP请求、HTML分析等方面的内容。
尊敬的您,请先解析出要采集的目标网站的构造,即掌握其页面结构以及数据储存的方式,以对采集策略进行明确的制定。
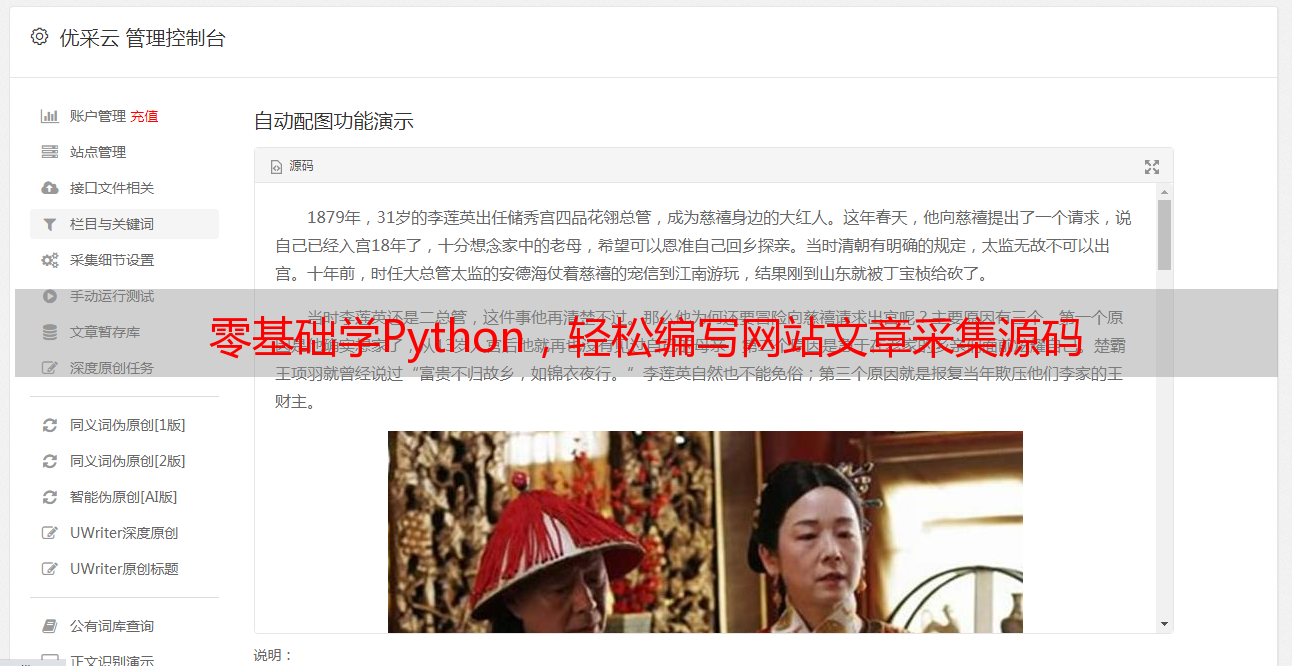
采集:依据目标网站架构与策略,设计并实现相应的采集代码,完成文章内容的抓取及储存。
四、网站文章采集源码需要注意什么?
合规原则:为了遵循相关法律法规,请确保您的采集代码无侵权行为。
速率调控:请适当掌控获取数据的速率,以免给目标网站增加不必要的负荷。
反爬虫措施:部分网址为避免被爬取,实施了防爬策略,我们应针对其特点做出相应应对。
五、如何优化网站文章采集源码?
1.多线程并发:通过使用多线程并发技术可以提高采集效率。
代理IP的合理运用:代理IP能有效隐蔽您的真实IP,预防被目的网站误判为不良用户而禁止访问。
定时任务设定:您可安排定时任务以自动化数据采集,降低您的手动操作参与度。
六、常见的网站文章采集源码工具有哪些?
尊敬的读者,我们为您推荐Scrapy——这是一款Python研发并完全公开的网络爬虫架构,功能完备并且十分灵巧。
BeautifulSoup:一款 Python 库,可便捷地从 HTML 及 XML 文件中抽取所需数据。
您好!这款名为Selenium的软件是一款优秀的Web自动化测试工具,它能够实现对网站的模拟浏览以及数据采集。
七、如何避免被反爬虫机制封禁?
善用随机 User-Agent:我们会在每次发送请求的时候,随机挑选一个 User-Agent 头部信息。
设定访问间隔:请设置合理的时间间隔,以反映出实际使用者的网页浏览习惯哦!
请启用代理IP服务:此服务能够隐藏您的真实IP,加大反爬虫过程中的难度。
八、网站文章采集源码的应用场景有哪些?
数据分析探索:我们利用多站点所提供的文章数据,进行深度分析研究。
内容汇聚平台:就如同为读者打造了一处知识宝库,汇集了来自各个领域的精彩文章供大家品读参考。
网络爬虫功能:利用网络爬虫技术,便捷地获取指定网站的文章内容。
在此,我们向您详细介绍了关于网站文章采集源码相关的信息。衷心希望这些知识能够给各位带来实用价值。如有疑问,欢迎随时与我们沟通交流哦!

