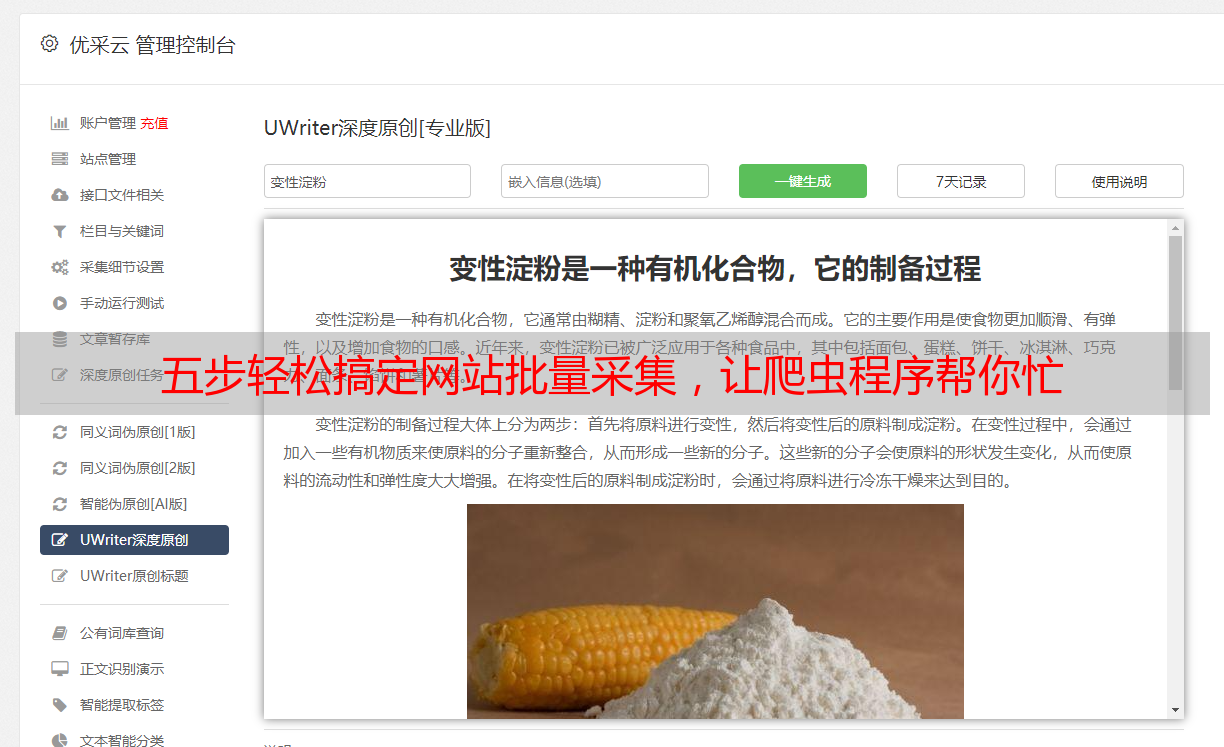
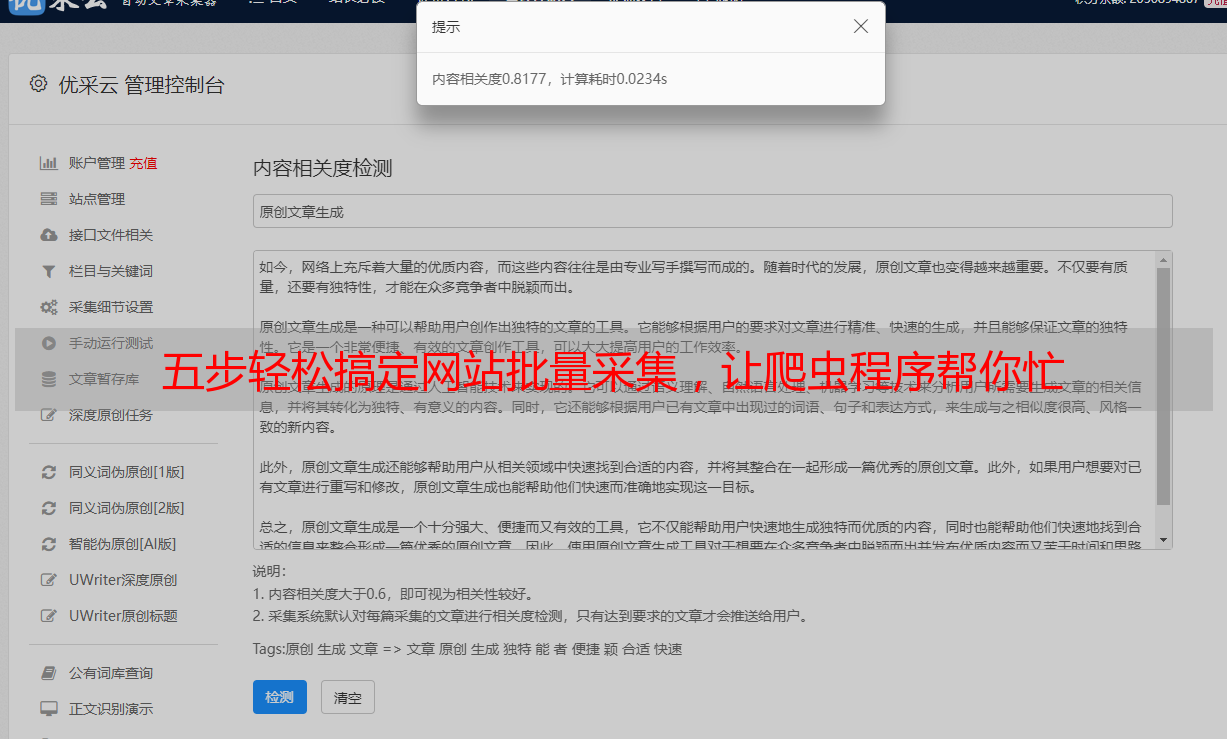
五步轻松搞定网站批量采集,让爬虫程序帮你忙
优采云 发布时间: 2024-01-02 04:321.寻找合适的网站采集工具
在开展批量网站采集工作前,您需要先挑选一款称心的采集工具。如选用知名开放源代码工具Scrapy或BeautifulSoup等,它们功能强大且配置多样,既能满足各种采集需求。
2.分析目标网站结构
在准备采集数据前,首先要对所选网站做深入结构研究。掌握网站页面布局,了解其网址命名规律及HTML标记等细节,将有助于我们更为高效地制订采集规则。
3.设定采集规则
依据目标网站的架构,制定适宜的数据采集策略。运用诸如XPath或CSS选择器来精确定位需收集对象,并建立高效的数据提取得当方法。在此过程中,切记防范反追击措施,防止网站对您的账户进行限制。
4.编写爬虫代码
依据既定规则编写爬虫代码,以利用网站采集工具的API或自行编写的自定义脚本来完成成批自动采集。请在编写过程中重视异常处理与日志记录,以便更有效地发现并解决可能出现的问题。
5.运行爬虫程序
完成编码工作后,请启动我们的爬虫程序来进行网站数据的采集工作吧!您可以选择在本地主机环境下执行程序,或者将其部署至云端服务器以实现分布式数据采集目的。在执行过程中,若需微调,您可灵活调整采集周期时长与并发处理进程数量,以确保两者间的高效性及对目标网站影响的合理控制。
6.数据清洗和处理
在收集后,我们常常需对数据做净化和调整,这有助于确保数据的高质及可用。您可通过运用相关技术处理工具或是编写简易脚本来实现这个需求。在此基础上,若是将机器学习这一法宝与之相结合,将会让我们对数据有更深入和细致的解读。
7.定期更新采集规则
因为网站的结构有变,我们建议您定期更新采集规则,以便确保可靠性与准确性。请务必关注目标网站的更新,以适时调整采集策略,我会全力协助您满足此需求。
8.注意合法合规
在进行网站采集时要遵守相关法律法规及网站使用协议哦~未经许可不可采集敏感信息或侵犯他人隐私。当然,如果是用于商务目的的话,还需特别关注商标、版权等知识产权问题呢。
9.遇到问题及时解决
在批量网站抓取过程中出现问题是无法避免的,比如目标站的反爬虫程序和网络连接故障等情况。面对困难,我们需要保持耐心,积极查阅资料,虚心向同行人士请教或是参考相关文献,逐步解决问题。
10.不断学习和提升
探讨批量网站采集,这不仅仅是一次提升自我的进程,更是持续追求新知、研磨技艺的旅程。请始终关注新近涌现的技术和工具,努力扩充您的知识库;以及,积极参与社区的讨论,分享彼此的心得体会,与同好们相互切磋度艺。
通过上述十项心得体验分享,希望每一位都能更为出色地完成网站批量采集任务。祝愿各位在实际操作过程中持续探究、革新思路,共同创造出更美好的职场生活环境。

