使用爬网软件爬网公共网络数据的案例(以点屏为例)
优采云 发布时间: 2020-08-08 07:52选择邯郸:
点击食物
选择任何商业区:
选择商家:
我们发现这些URL非常规则,这些规则将有助于我们抓取数据!
让我们再次查看任何页面的源代码
我们观察每个零件的分布位置,这会减小我们的爬行范围并加快爬行速度.
第二,URL采集
打开优采云采集器软件.
创建一个新任务.
我们发现第一步是设置URL采集规则. 这是非常重要的一步,它将影响我们采集的数据量.
我们发现,我们抓取的数据全部在商家详细信息页面上:
因此,我们必须找到一种访问此页面的方法!
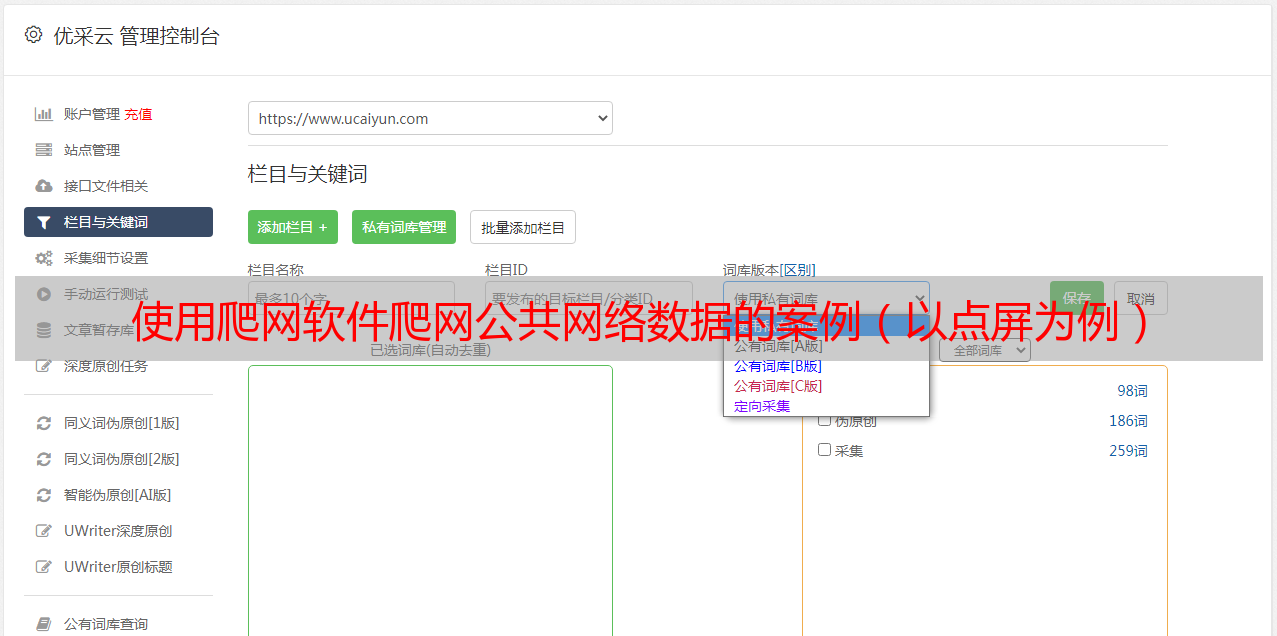
这里我选择按业务区域进行爬网(这可以优化数据,还可以根据管理区域,业务类型,甚至不选择要爬网的条件)
我们选择一个商业区作为起始爬网地址.
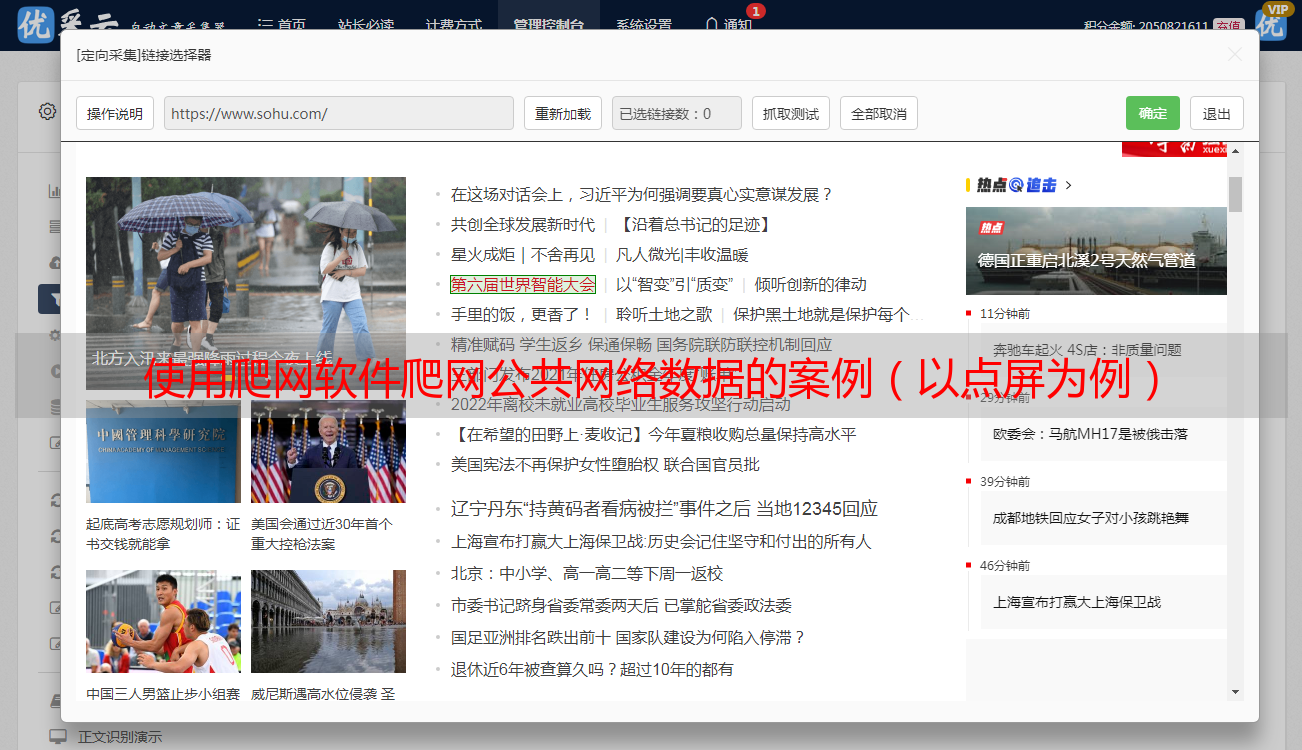
我们将在此页面上找到15个商人!
每个商人将对应一个联系. 如果选择单个连接,则只会抓取15条数据,因此我们必须找到一种解决分页问题的方法.
让我们观察第二页和第三页的连接:
很明显,第一个是唯一不变的,而下一页是在变化的.
单击向导以添加>>批处理URL
将页码设置为地址参数,选择从2开始,然后每次递增一次,共14项.
我们可以在下面的阅读物中看到想要查看的链接.
单击URL采集测试,您将获得以下结果:
我们采集了15页,每页采集了15条数据. 这就是我们想要的!
三,内容采集
在第二部分中,我们将设置内容采集规则.
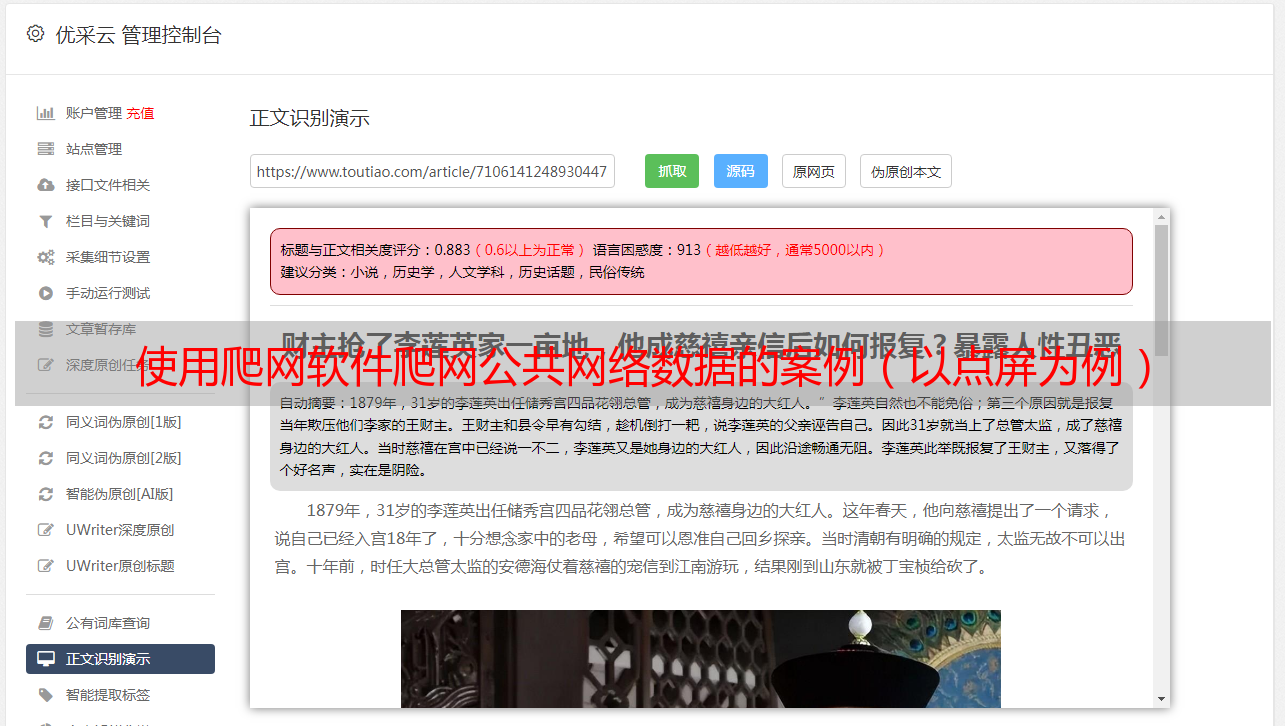
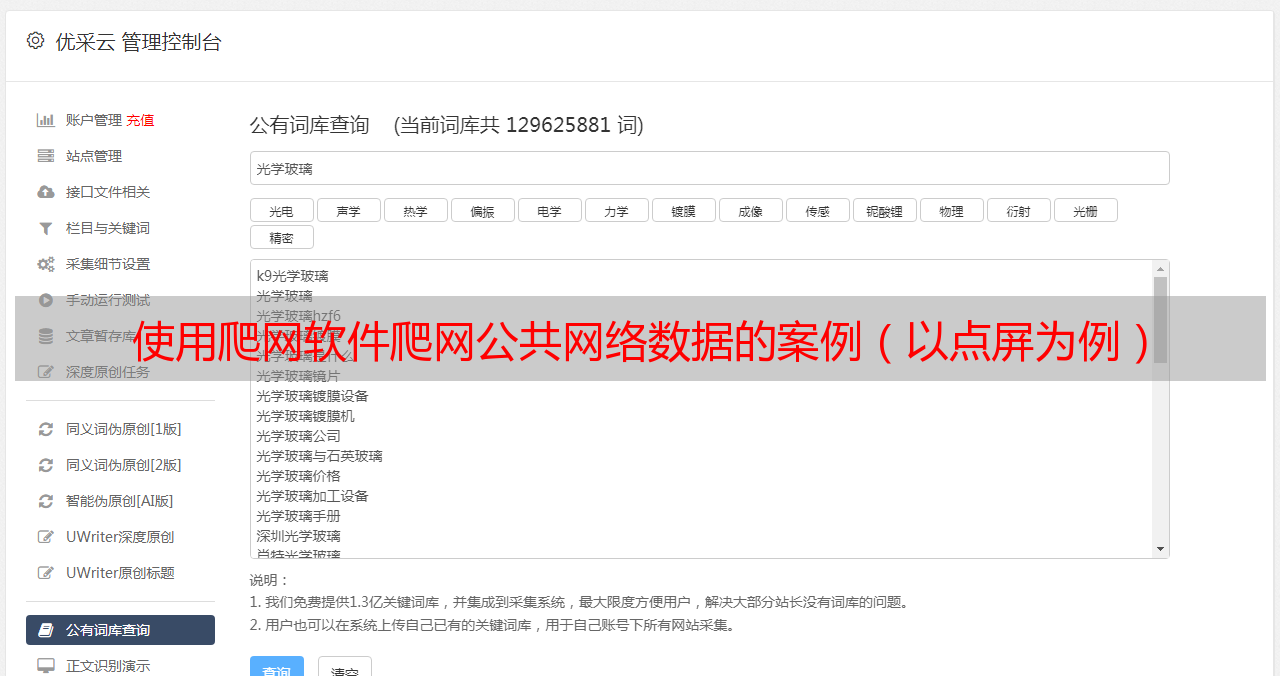
我们要在此处采集的数据是: 经度,纬度,商户名称,位置信息,品味,环境,服务,评论数量,人均消费量. 分别设置它们.
我们首先观察源代码中每个部分的特征,然后填写开始字符串和结束字符串.
请注意,我们最好确保起始字符串是唯一的,否则将选择第一个进行拦截.
让我们首先看看JS的这一段,其中收录了大部分数据.
经度
商家名称
位置信息
让我们看一下以下更具特色的源代码
味道
评论数
人均消费
内容采集规则的基本设置已经完成,让我们测试一下数据:
测试成功!
四个内容发布
内容发布将导出采集的数据. 这里的免费版本仅支持导出到txt.
为方便转换为excel,我们设置了以下规则:
标签都用逗号分隔,并且每条数据都用换行符添加.
基本设置已完成,单击右下角以保存并退出.
开始采集和导出数据!
将txt转换为excel
以下是我们导出的txt数据
它看起来凌乱且使用不便,因此我们将其另存为excel
打开excel,单击打开文件,选择所有文件,找到我们的txt
选择分隔符>>逗号分隔
单击“完成”,我们将获得所需的数据格式!
有了这些数据,我们就可以开始数据可视化之旅!

