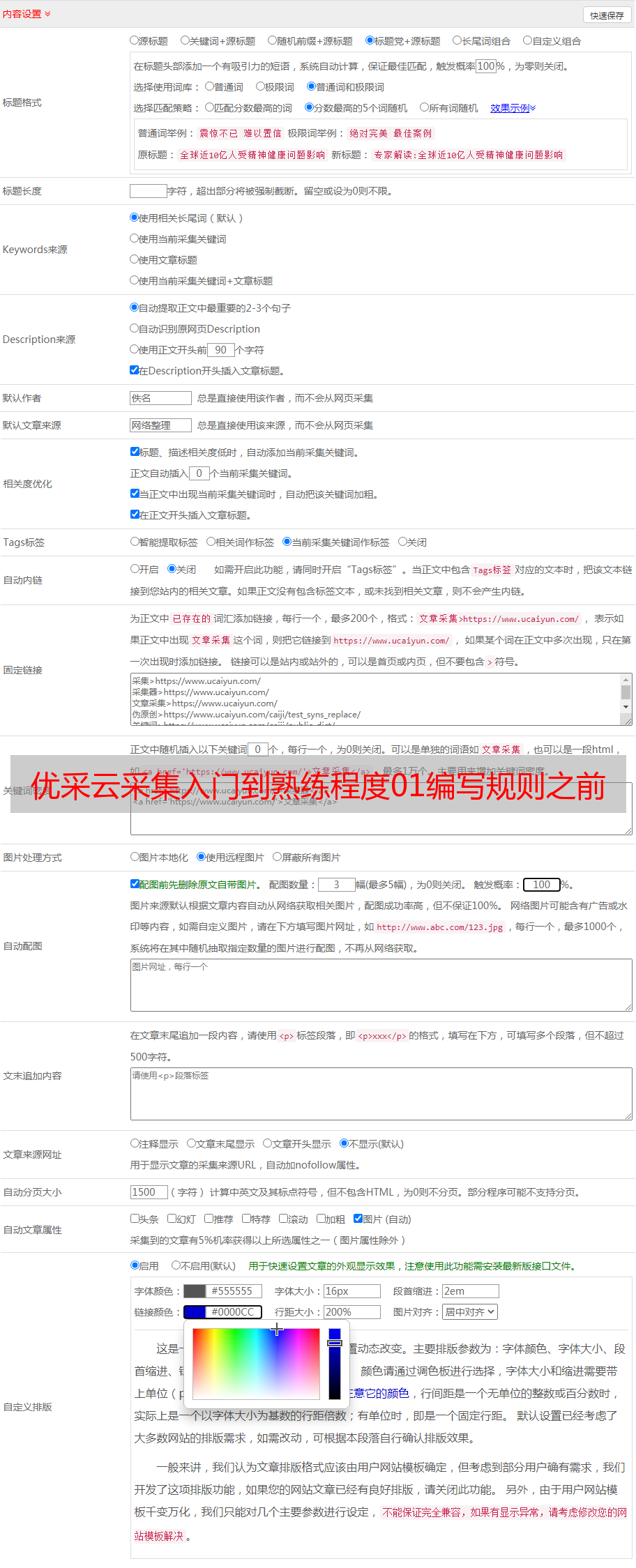
优采云采集入门到熟练程度01编写规则之前的准备工作
优采云 发布时间: 2020-08-08 05:28本文将在开始时解释一些必要的知识,有些知识太基础或Internet上有非常现成的教义,我将提供链接.
1. 什么是网络数据采集?可以采集什么?什么问题可以解决?
1,网络数据采集的概念
顾名思义,它是通过从网页采集数据来实现的. 在浏览器中看到的是网页,也称为页面. 每个单词和每个数字都可以称为数据. 网页数据采集是系统地提取网页上的字符以获得有用的数据.
小白中的一些小白问优采云,可以采集些什么. 这是一个可悲的问题. 您可以尝试采集可以在任何网页上看到的字符. 如果看不到它,只要它出现在源代码中,就可以尽力采集它. 优采云只是一个采集工具. 您需要自己查找数据源. 不要把优采云当作自动售货机. 只需单击您想要的. 那并没那么简单. 首先要找到数据源页面,所以不要问以下白痴问题:
问: 优采云可以采集北京的所有餐厅信息吗?
答案:
应该这样考虑问题: 在哪里可以找到所有北京餐厅的信息?滇平选择北京的食物选择应该有很多这类信息. 所有的信息都很困难,但是点屏有很多信息,基本上可以满足我的需求. 因此,问题直接变为: 优采云能否采集有关北京地区的信息以及滇平的美食企业?答案是肯定的.
2. Web数据采集的结果是什么?
优采云采集的数据非常容易理解,只需将其视为简化的Excel工作表即可. 作为采集器,优采云只提取网页中的字符串信息. 通过循环采集,最终结果是一个表. 与excel不同,此表仅收录文本,不收录图片和其他内容. 所有数据都将存储在一个表中.
3. 网页数据采集的主要功能,要解决什么问题
就像前面提到的需求一样,您可能需要北京地区所有餐馆的业务信息. 这是为了什么也许您想打电话给这些商人来宣传您的产品信息,或者您只需要计算周围的竞争对手,或者只是老板的一时兴起就可以采集这些数据,或者这是您大学毕业论文所需的主题. 数据需求是多种多样的,但它们都是一个过程: 输入(数据源)-采集(优采云)-处理(数据清理)-输出(最终用途). 数据不是万能药,但是数据的最终使用权取决于您.
第二,优采云采集器是什么?采集原则是什么?
1. 优采云采集工具简介
优采云官方网站:
优采云是一种工具,程序和软件,可将繁琐的数据采集工作简化为自动执行,从而解决了海量数据采集的问题.
它的下载和安装相对简单. 优采云本身可以免费使用. 免费版本的基本操作是可以的,但是仅允许单机采集,并且在导出数据时需要点. 如果您不想花太多钱,可以使用独立的馆藏和积分出口. 作为旗舰版配置,云采集主要是为了解决采集速度慢的问题,将在后面详细讨论.
建议仔细阅读《 优采云入门手册》:
本文将不对油彩云的基本操作进行过多解释. 也许您会批评我: 这不是入门教学吗?为什么不谈论呢?在这方面,我只能说优采云官方网站上的教学视频非常简单,软件操作入门的难度也很低. 预计我将努力解释这些基本操作. 最好通过示例来解释它们. 而且你没有给我钱,优采云也没有给我钱,我为什么说得这么好?不是吗?
2. 优采云的采集原则
优采云的采集原理可以简单地理解为模拟用户访问特定页面并从页面源代码中提取所需信息. 一切都基于模拟用户访问和用户操作. 这是优采云的核心-“模拟”. 这个核心决定了许多问题. 有关详细信息,请参见我的另一篇文章“市场上的主流采集工具和个人感觉的比较”.
注意: 是的,您找不到这篇文章,为什么?因为我还没有写它,哈哈哈...(对不起,这只是暂时的,因为我没有完成链接,所以我没有更新链接),但是我对智虎的回答有一些解释,你可以单击此处查看.
三,采集之前需要知道的事情
1,什么是网页,HTML,源代码
网页本身不直接显示在此处,渲染后将显示您看到的页面. 举一个傻瓜式例子,就像您看到一个面包,但是看不到面包中的面粉,鸡蛋和添加剂. 您只会看到由原材料处理的成品. 这就是它们之间的关系. 源代码是原材料. 通常,网页基于以HTML语言编写的源代码,该源代码是在通过浏览器进行解析和呈现后获得的,即IE,chrome,Firefox等. 可视化页面. 自己不了解百度这一部分的朋友,在此不再赘述.
2,为什么看源代码很重要?
由于您在浏览器中看到的页面已被“处理”,因此您可能看不到最真实的数据. 源代码显示了这些数据,实际上您可能认为可以从源代码中提取出您认为无法提取的数据. 优采云的工作机制是从源代码中提取数据.
3,什么是Xpath以及为什么如此重要
XPath是用于在XML文档中查找信息的语言. XPath可用于遍历XML文档中的元素和属性. 不在乎xml是什么,html也是一种文档,xpath支持在其中定位元素和查找属性信息. 定位元素指的是什么?让我们看一下HTML代码示例:
第一次接触的人必须头晕目眩. 没有办法. 从未参加过编程的人们必须感到所有内容都已编码. 但是现实就是这样. 只有通过可视化编码的事物,才能实现机器与人之间的交互. HTML是一种树结构,许多其他元素嵌套在一个元素下,理论上是无限嵌套. 例如:
1
1.1
1.1.1
2
2.1
2.1.1
等等等...每个元素都是一个元素,并且该元素具有其自己的属性(进入新页面,触发操作,提交表单等). 找到元素后,就可以提取属性或文本以准确提取我们需要的数据. 理解起来并不麻烦,只需将其视为目录即可,该目录可以通过xpath代码位于特定章节的特定子节中.
Xpath非常重要的原因是,优采云的所有定位和规则细节都取决于xpath,因此,如果您不掌握xpath,就不可能很好地使用优采云. 有关特定的xpath教程,建议参考W3SCHOOL网站. 不要害怕无聊,要克服困难就可以突破: 单击此处.
当然,不要太担心. 以后会有很多例程供您学习,解决xpath例程的问题会容易得多.
4,要准备的软件
首先,您需要一个浏览器,您肯定会非常高兴地说我有很多东西!我们不需要任何其他东西. Ucai Cloud的核心是Firefox浏览器,因此最安全的过程是安装Firefox浏览器. 接下来是例行时间. 请在Internet上找到它,或在Firefox浏览器中下载并安装两个插件:
Firebug和Firepath的作用分别是提供便捷的xpath定位和检查功能.
成功安装后,我们进入Internet上的任何网页,然后单击F12快捷键进入开发人员操作区域.
请注意我的屏幕截图. 您必须先单击下面的“ firepath”选项卡以进入firepath操作界面. 在此界面中,首先单击左侧的小按钮,然后在页面上单击要提取的数据位置. 您可以查看源代码信息并自动生成元素的xpath代码.
借助此工具,优采云可以更准确地实现循环定位元素,并解决许多人莫名其妙的数据泄漏,丢失和数据采集中断的问题.
有人会问,为什么不使用IE,Google,QQ浏览器,傲游浏览器,搜狗浏览器?
这很简单. 简而言之,优采云中的浏览器是Firefox内核...因此只有Firefox才能看到最一致的浏览器. 而且,firepath非常易于使用. 我还没有在Google上找到与其完全相同的插件. 有一个更好的Google插件,称为xpath helper. 您也可以尝试.
四来,开始采集!
如果您认为我会开始在本文中进行采集,那么您错了!这是例行程序,为什么我要在一篇文章中写那么多?你不付我稿费...以上是所有准备工作. 在下一篇文章中,我将使用一些网站做一些案例来解释采集过程. 我的原则不是使用繁琐的基础教程,而是直接使用实际的入门方法. 可以通过推理将一些细节和经验扩展到更多案例,从而避免昂首阔步并树立信心!
Brother Rabbit Data Geek Club的QQ组: 组ID: 462346024
个人WordPress博客:
了解该列:
简书首页:

