轻松抓取网页代码,这些网站必备!
优采云 发布时间: 2023-04-11 02:09在互联网时代,信息是最重要的资源之一。而获取这些信息的方式之一就是通过抓取网页代码来实现。在这个过程中,有许多网站可以帮助你完成这个任务。下面将详细介绍这些网站的使用方法和注意事项。
一、什么是抓取网页代码?
在介绍具体的网站前,我们先来了解一下什么是抓取网页代码。简单来说,抓取网页代码就是通过程序自动获取指定页面的源代码,并对其进行分析,提取出所需信息。这种方法可以大大提高信息获取效率,尤其是对于需要大量数据的情况下。
二、抓取网页代码的注意事项
在进行抓取网页代码之前,有几个需要注意的问题。
1.合法性问题:要注意是否违反了相关法律规定。
2.尊重版权:不要随意复制他人创作的内容。
3.反爬虫机制:部分网站会设置反爬虫机制,请遵守相关规定。
4.数据格式:要注意数据格式是否符合自己的需求。
三、抓取网页代码的常用工具
1.Python语言
Python语言是目前最流行的编程语言之一,其强大的网络爬虫框架和大量的第三方库可以方便地实现网页代码的抓取。
2. Beautiful Soup
Beautiful Soup是Python中一个非常强大的HTML/XML解析库,可以帮助我们方便地处理HTML文档中的数据。
3. Scrapy
Scrapy是Python中一个高效的网络爬虫框架,支持多线程、分布式等功能,可以快速地抓取大量数据。
四、抓取网页代码的常用网站
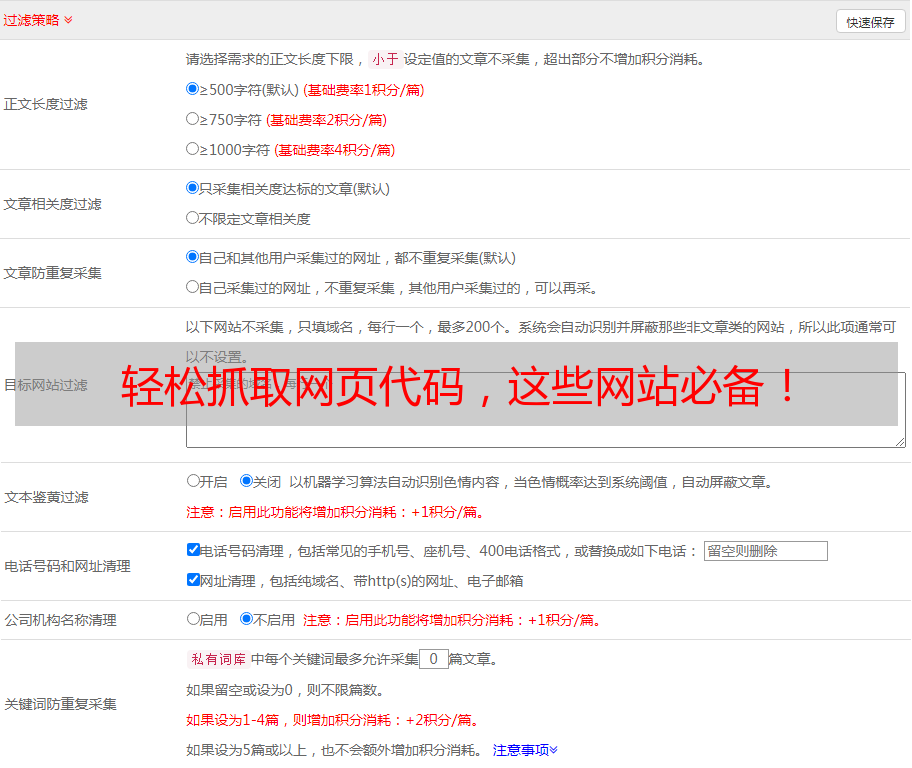
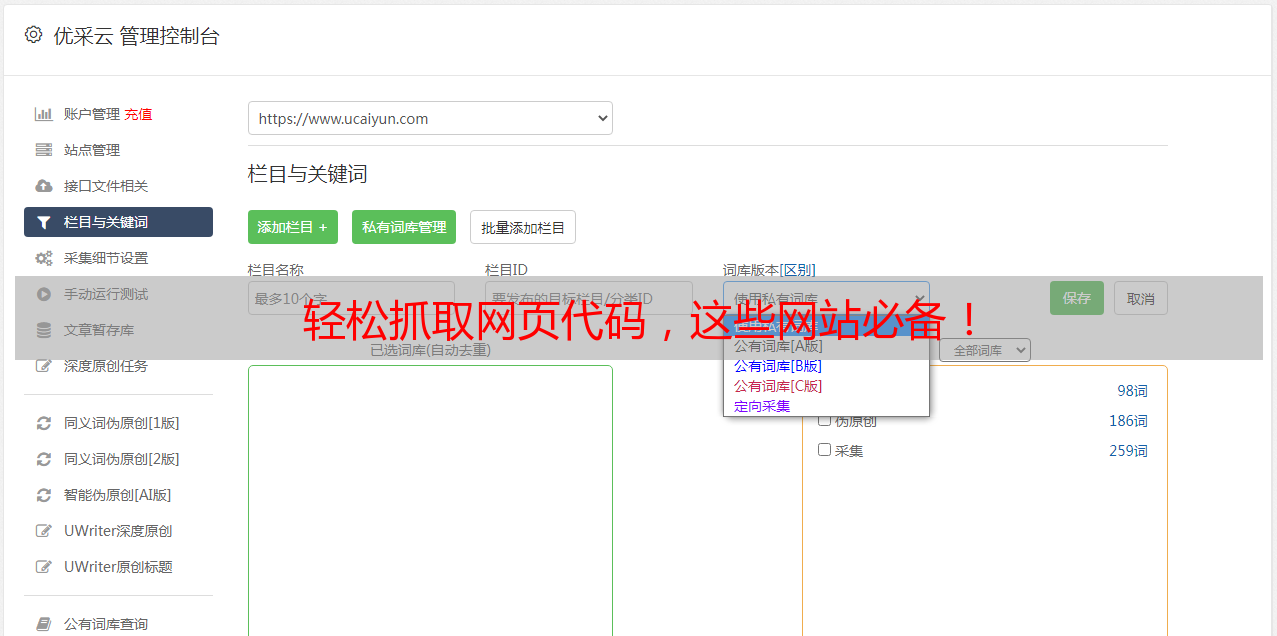
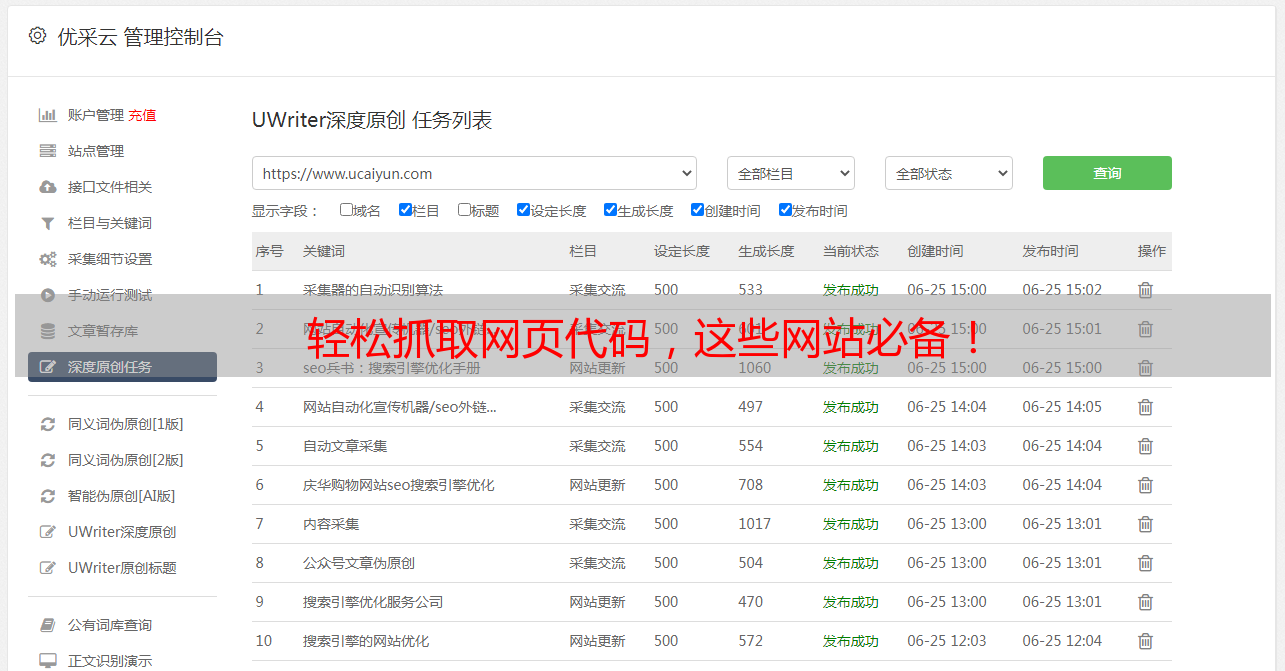
1.优采云(www.ucaiyun.com)
优采云是一款专业的SEO优化工具,可以帮助用户轻松地获取目标网站的源代码,并对其进行分析。同时,它还提供了丰富的数据分析和可视化功能,方便用户进行深入研究。
2.爬虫工具箱(www.pcgzhan.com)
爬虫工具箱是一个在线的抓取网页代码工具,支持多种数据格式输出和自定义规则设置。同时,它还提供了强大的反爬虫机制和代理池服务,可以有效地应对各种网络环境。
3. DataMiner(dataminer.io)
DataMiner是一个基于浏览器插件的抓取网页代码工具,支持多种浏览器和平台。它可以快速地抓取目标网站的数据,并自动转换为CSV、JSON等格式,方便用户进行后续处理。
4. Octoparse(www.octoparse.com)
Octoparse是一款强大的自动化抓取工具,支持多种数据格式输出和自定义规则设置。它还提供了丰富的数据分析和可视化功能,方便用户进行深入研究。
五、抓取网页代码的注意事项
在使用这些抓取网页代码工具时,需要注意以下几点:
1.合法性问题:要注意是否违反了相关法律规定。
2.尊重版权:不要随意复制他人创作的内容。
3.反爬虫机制:部分网站会设置反爬虫机制,请遵守相关规定。
4.数据格式:要注意数据格式是否符合自己的需求。
六、如何防止被反爬虫?
在进行抓取网页代码时,有时会遇到被反爬虫机制拦截的情况。这时可以采用以下几种方法来绕过反爬虫机制:
1.使用代理IP:通过更换IP地址来绕过反爬虫机制。
2.模拟浏览器行为:通过模拟浏览器行为来绕过反爬虫机制。
3.随机延时:通过随机延时的方式来绕过反爬虫机制。
七、抓取网页代码的案例分析
以下是一个抓取新浪财经*敏*感*词*的案例分析。
1.确定目标网站和数据格式。
2.使用Python中的requests库获取网页源代码。
3.使用Beautiful Soup解析HTML文档,并提取所需数据。
4.将数据转换为CSV格式并保存到本地文件中。
八、抓取网页代码的优缺点
抓取网页代码的优点:
1.可以大量快速地获取所需信息。
2.可以对信息进行深入研究和分析。
抓取网页代码的缺点:
1.容易遭受反爬虫机制的拦截。
2.需要一定的编程能力和技术水平。
九、总结
抓取网页代码是一种高效、快捷获取信息的方法,但需要注意合法性问题和反爬虫机制。通过掌握相关工具和技术,可以轻松实现对目标数据的抓取。同时,我们也要尊重版权,合法合规地使用这些工具。如果您需要更加专业的SEO优化工具,请访问优采云官网(www.ucaiyun.com)。

