HTML页面数据采集:10种技术助你打造高效收割机
优采云 发布时间: 2023-04-09 02:12HTML页面数据采集可以理解为通过程序自动化地抓取网页上的信息,这项技术在当今数据驱动的时代变得越来越重要。无论是商业智能、市场调研还是竞品分析,数据采集都是必不可少的环节。本文将从以下10个方面详细介绍HTML页面数据采集技术,帮助你打造自己的“数据收割机”。
1.为什么要进行HTML页面数据采集?
2.常见的HTML页面数据采集工具和技术
3.如何分析目标网站的HTML结构
4.如何模拟浏览器行为
5.如何处理反爬虫机制
6.如何处理JavaScript渲染
7.如何使用正则表达式解析HTML
8.如何使用XPath解析HTML
9.如何使用CSS选择器解析HTML
10. HTML页面数据采集案例分析
首先,我们需要了解为什么要进行HTML页面数据采集。随着互联网技术的快速发展,信息量也呈爆炸式增长。而这些信息中包含着许多有价值的商业情报、市场调研、竞品分析等等。如何高效地获取这些信息成为了许多企业和个人所关注的问题。HTML页面数据采集技术可以帮助我们快速准确地获取所需信息,提高工作效率和竞争力。
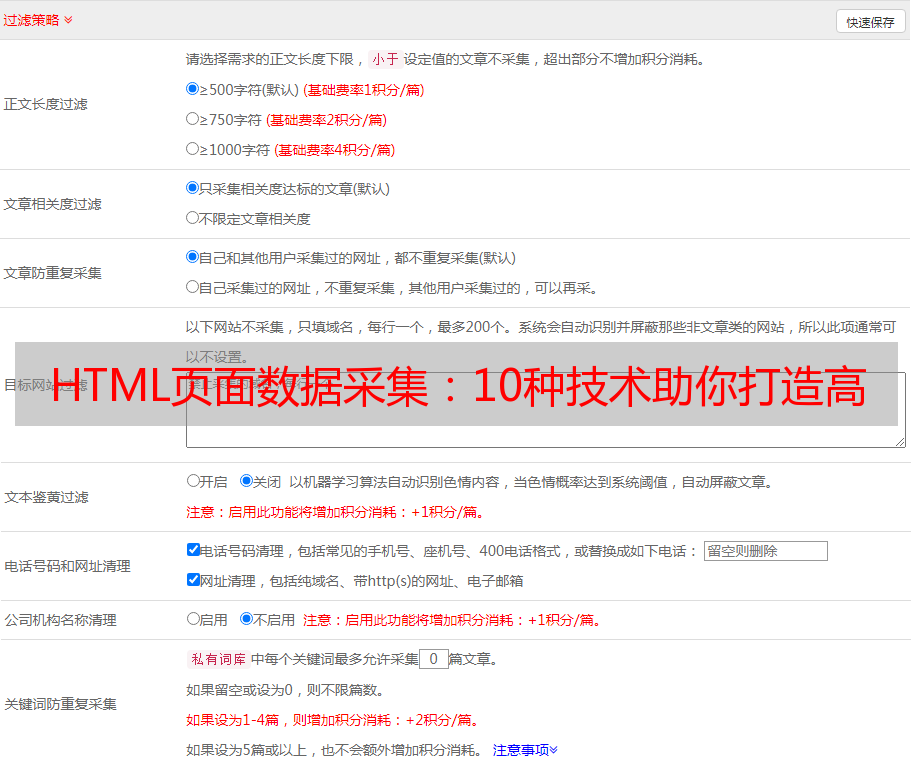
接下来,我们需要了解常见的HTML页面数据采集工具和技术。常见的工具有Python中的Requests、BeautifulSoup、Scrapy等等;技术包括分析HTML结构、模拟浏览器行为、处理反爬虫机制、处理JavaScript渲染等等。这些工具和技术都有各自的优缺点,在实际应用中需要根据具体情况进行选择。
在进行HTML页面数据采集之前,我们需要对目标网站的HTML结构进行分析。这包括查看网页源代码、分析网页结构、确定需要采集的内容等等。只有深入了解目标网站的HTML结构,才能更好地进行数据采集。
模拟浏览器行为也是HTML页面数据采集中重要的一环。由于许多网站会根据用户的行为返回不同的内容,因此模拟浏览器行为可以帮助我们获取更全面准确的信息。
反爬虫机制是许多网站为保护自身利益而设置的障碍。常见的反爬虫机制包括IP封禁、验证码识别、请求频率限制等等。如何处理这些反爬虫机制也是HTML页面数据采集中需要解决的问题。
JavaScript渲染也是许多网站为了提高用户体验而使用的技术,但这也给HTML页面数据采集带来了一定的困难。我们需要使用一些技术手段(如Selenium、PhantomJS等)模拟JavaScript渲染,从而获取完整的网页内容。
在进行HTML页面数据采集时,我们可以使用正则表达式、XPath或CSS选择器对HTML进行解析,从而获取所需信息。不同的解析方法有各自的优缺点,在实际应用中需要根据具体情况进行选择。
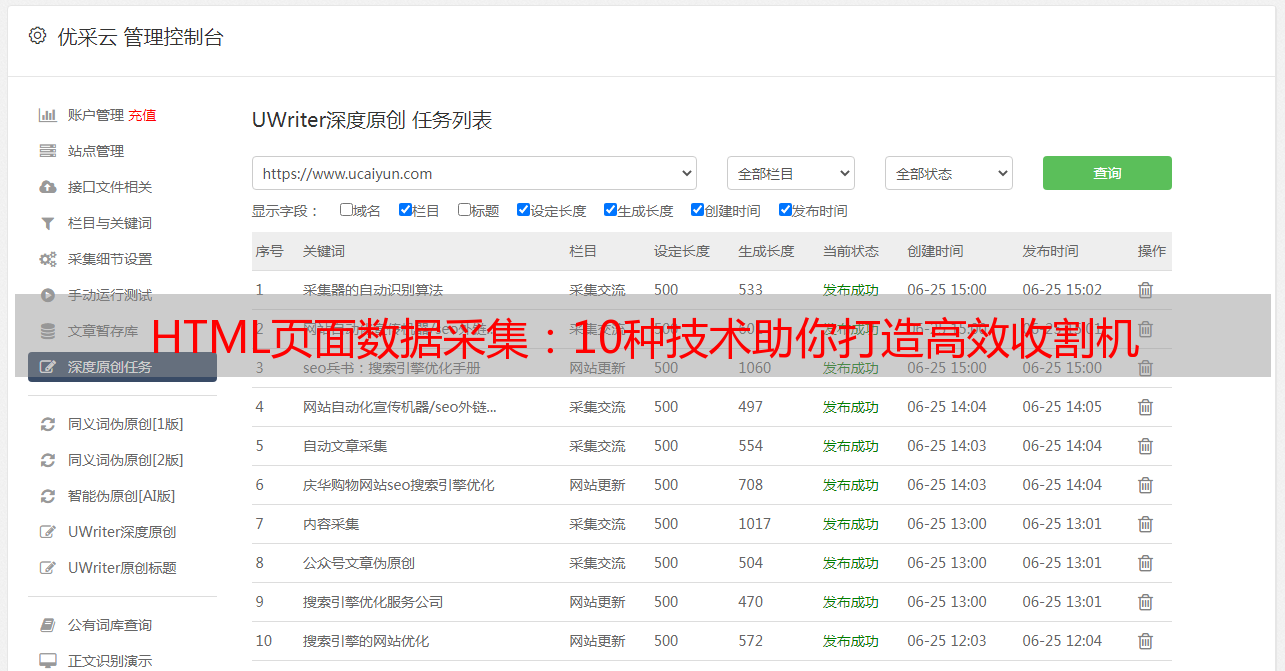
最后,我们将通过一个实际案例来展示HTML页面数据采集的应用。以优采云(www.ucaiyun.com)为例,我们可以通过HTML页面数据采集技术获取该网站上的关键信息,如网站流量、SEO排名、用户行为等等。这些信息对于优采云的市场调研和竞品分析非常有价值。
总之,HTML页面数据采集技术在当今数据驱动的时代变得越来越重要。通过深入了解目标网站的HTML结构、模拟浏览器行为、处理反爬虫机制和JavaScript渲染等等技术手段,我们可以打造自己的“数据收割机”,获取更多有价值的商业情报和市场信息。

