轻松抓取二级页面!网站数据爬虫插件来袭
优采云 发布时间: 2023-04-06 23:09在如今的互联网时代,我们都知道网站是一个公司、组织或个人展示自己的重要平台。但是,在网站中,有一些信息是不对外公开的,需要通过登录或者其他方式才能获取到。这时候,就需要一个可以抓取二级页面的插件来帮助我们获取这些信息。本文将为大家详细介绍这款插件。
一、插件介绍
这款插件叫做“Web Scraper”,它是一款可以在浏览器上运行的数据爬取工具。它可以通过简单的配置,自动化地抓取目标网站上的数据,并将抓取到的数据转换成 Excel、CSV 或者 JSON 格式导出。这样,我们就可以方便地对这些数据进行分析和处理。
二、安装及使用
安装这款插件非常容易:只需要在 Chrome 浏览器上搜索 Web Scraper,然后点击添加即可。安装完成后,在浏览器右上角会出现一个小图标,点击该图标即可打开 Web Scraper 的主界面。
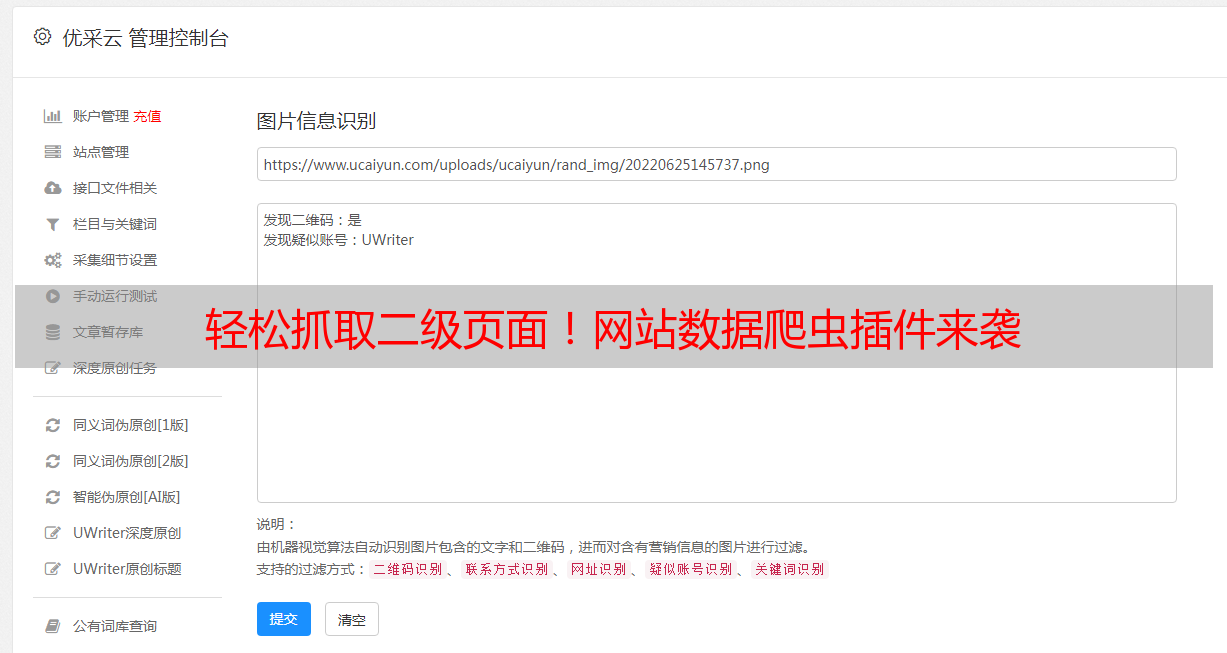
三、配置选择器
在使用 Web Scraper 之前,我们需要先进行一些配置。首先,我们需要打开目标网站,并进入需要抓取数据的页面。然后,在 Web Scraper 的主界面上点击“创建新选择器”按钮,进入选择器配置页面。
在选择器配置页面上,我们需要输入选择器名称、选择器类型以及选择器规则。其中,选择器类型可以是元素、链接或者图片等。选择器规则可以是 CSS 选择器、XPath 或者正则表达式等。这里我们以 CSS 选择器为例进行说明。
四、测试选择器
配置好了选择器之后,我们需要对它进行测试,确保它能够正常抓取数据。在测试之前,我们需要先设置网站的 Cookies。这可以通过在浏览器上登录目标网站并获取 Cookies 来实现。
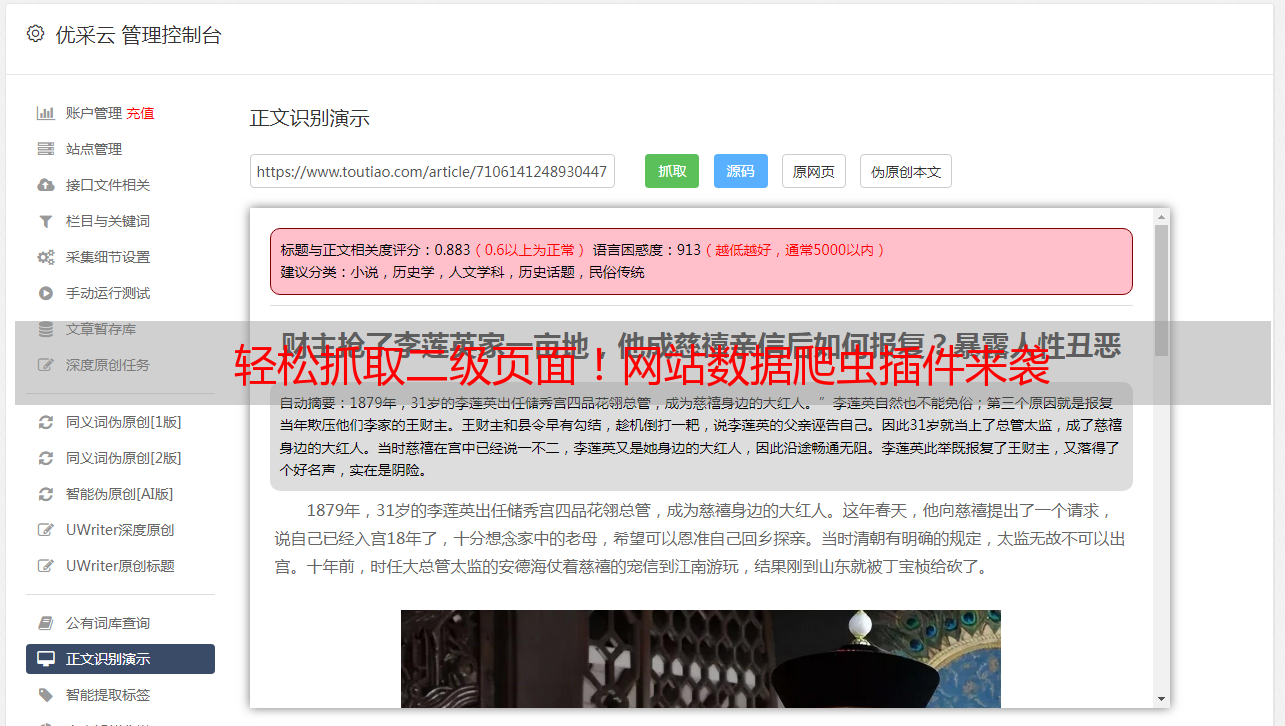
设置好 Cookies 之后,我们就可以点击 Web Scraper 主界面上的“运行”按钮进行测试了。如果测试成功,我们就可以看到抓取到的数据,并对其进行导出。
五、自动化抓取
除了手动测试之外,Web Scraper 还支持自动化抓取。具体来说,我们可以通过设置定时任务或者使用 Web Scraper Cloud 进行自动化抓取。
六、优采云
如果您需要更加专业的数据采集服务,那么就可以使用优采云来实现。优采云是一款专业的数据采集工具,它支持海量数据的采集和处理,并提供了丰富的数据分析和可视化功能。
七、SEO优化
在使用 Web Scraper 进行数据采集时,我们需要注意一些 SEO 优化技巧,以避免被目标网站封禁。具体来说,我们可以通过设置 User-Agent、使用代理 IP 和随机延时等技巧来减少被封禁的风险。
八、结语
通过本文的介绍,相信大家已经对 Web Scraper 这款插件有了更加深入的了解。在使用 Web Scraper 进行数据采集时,我们需要注意一些技巧,并且需要遵守法律规定和网站协议。如果您需要更加专业的数据采集服务,那么就可以选择优采云来实现。

