应对网站更新机制的爬虫技巧,助力互联网数据获取
优采云 发布时间: 2023-04-04 16:18爬虫技术是互联网数据获取的重要手段之一,但随着网站技术的不断升级,爬虫也面临着越来越复杂的反爬机制。本文将从以下九个方面展开讨论如何应对网站更新机制。
一、反爬机制的原理和现状
目前,常见的反爬机制包括IP封禁、验证码识别、JS渲染、User-Agent检测等。文章详细介绍了这些反爬机制的原理和应对方法。
二、数据抓取策略优化
针对反爬机制,我们需要优化数据抓取策略。比如设置合理的请求频率、使用代理IP等,文章详细介绍了如何进行数据抓取策略优化。
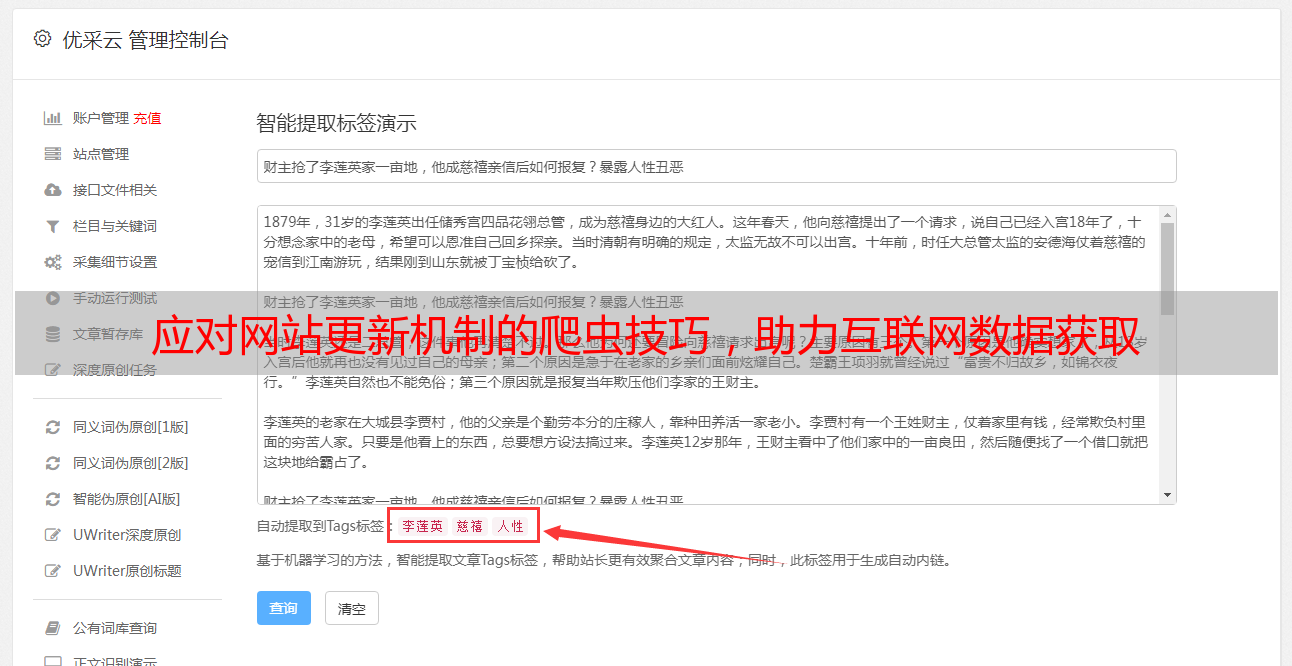
三、动态页面抓取方案
动态页面是现在网站的主流设计方式,传统的静态页面抓取技术已经无法适用。文章介绍了动态页面抓取方案,并给出了详细步骤和代码示例。
四、网站结构分析
了解网站结构可以更好地为我们的爬虫设计提供指导。文章介绍了如何进行网站结构分析,并给出了实例。
五、反爬虫行为分析
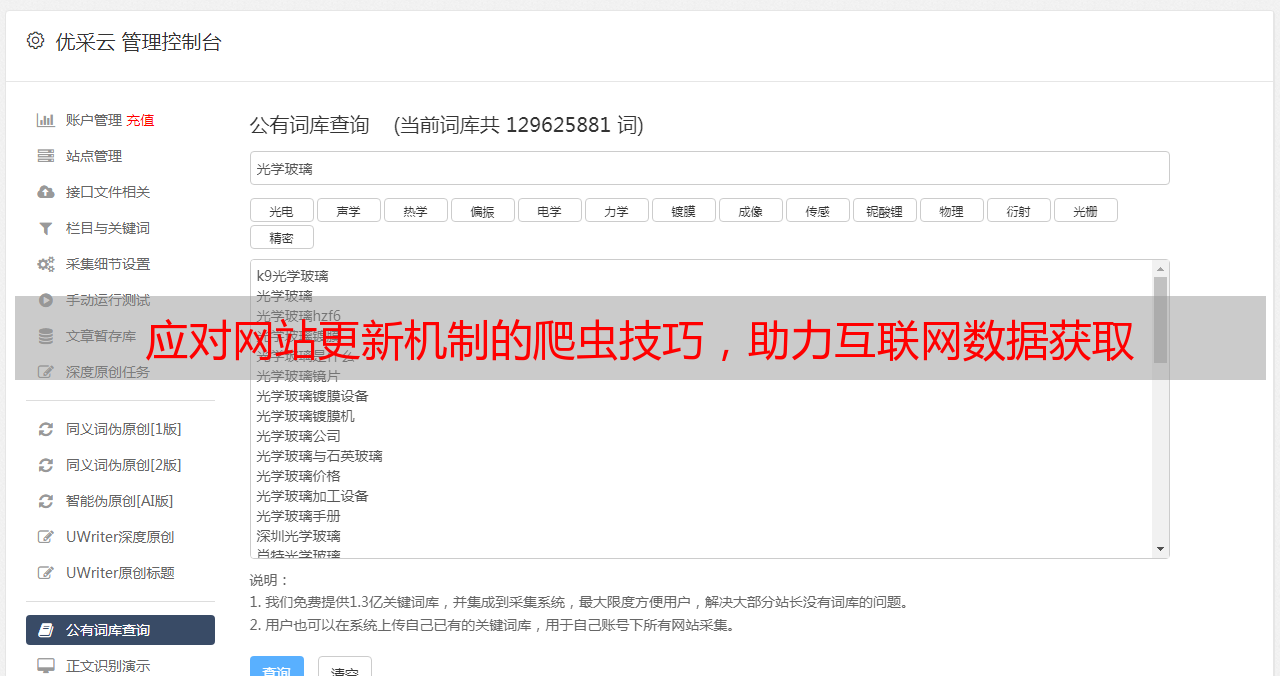
对于一些反爬虫机制,我们需要进行深入的行为分析,以便更好地应对。文章介绍了如何进行反爬虫行为分析,并给出了实例。
六、使用浏览器模拟工具
对于一些需要JS渲染的网站,我们需要使用浏览器模拟工具来获取数据。文章介绍了如何使用浏览器模拟工具,并给出了详细步骤和代码示例。
七、多线程抓取
多线程抓取可以提高数据获取效率,减少被反爬机制识别的概率。文章介绍了如何进行多线程抓取,并给出了实例。
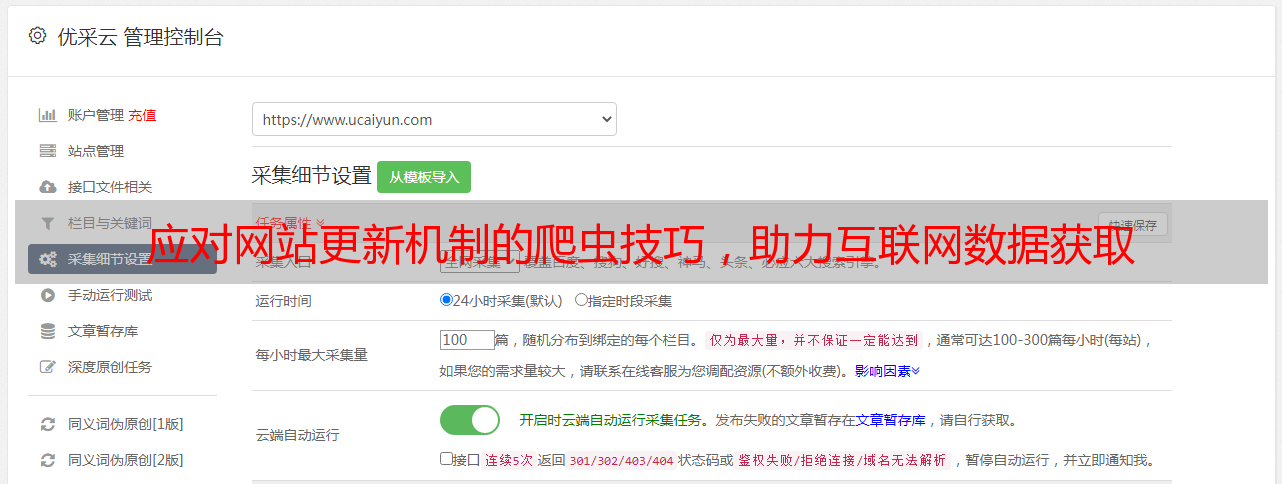
八、定时更新策略
网站结构和数据都是不断变化的,我们需要定时更新爬虫策略以保证数据的准确性。文章介绍了如何制定定时更新策略,并给出了实例。
九、合法合规使用爬虫技术
在使用爬虫技术时,我们需要遵守相关法律法规和道德规范,文章详细介绍了合法合规使用爬虫技术的注意事项。
总之,针对网站更新机制,我们需要不断优化自己的技术手段,才能更好地应对挑战。优采云提供的SEO优化服务可以帮助网站更好地被搜索引擎收录,欢迎访问www.ucaiyun.com了解更多信息。

