轻松获取想要信息,网页书籍抓取实用技巧!
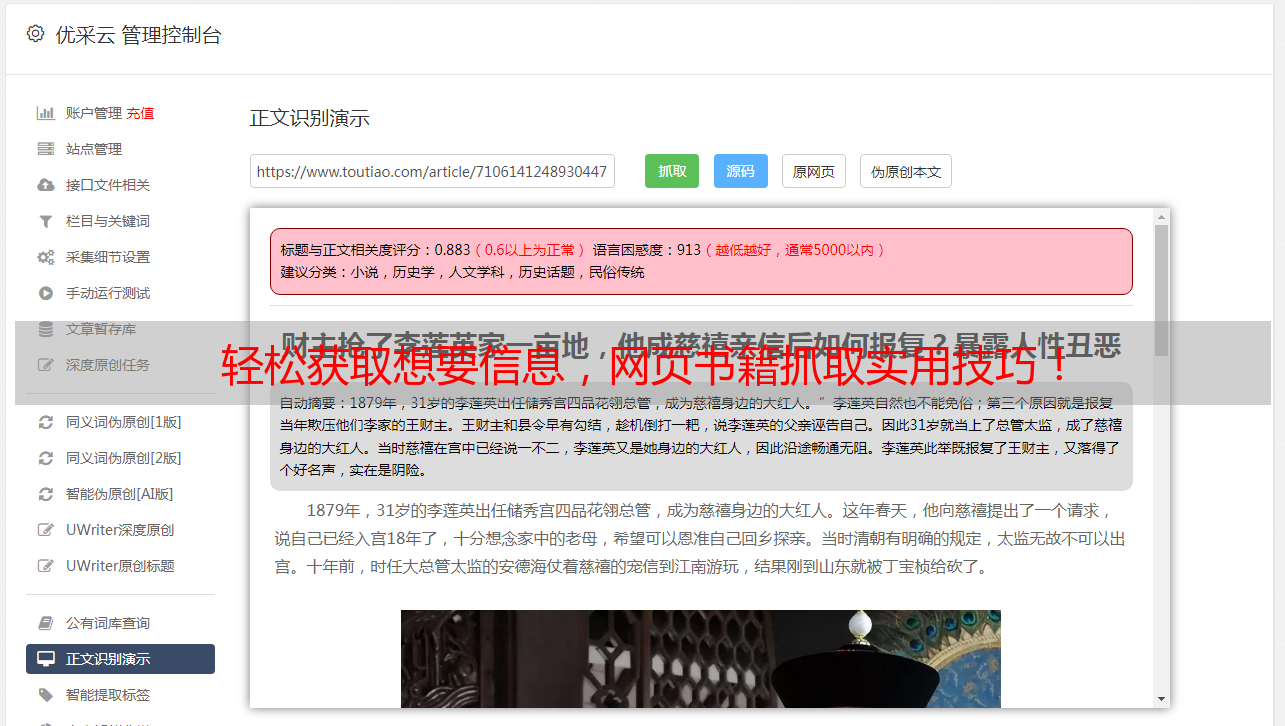
优采云 发布时间: 2023-04-03 14:14在数字化时代,越来越多的书籍被数字化并上传至网络,这为人们获取知识提供了极大的方便。但是,对于需要大量阅读的人来说,如何快速获取所需信息成为了一个亟待解决的问题。本文将从8个方面逐步分析如何通过网页书籍抓取来快速获取你想要的信息。
一、什么是网页书籍抓取?
网页书籍抓取即通过编写程序代码从互联网上自动化地获取所需的书籍信息。这种方式可以大幅度提高效率,减少手动搜索和筛选所需信息的时间。
二、为什么需要网页书籍抓取?
随着数字化时代的到来,越来越多的书籍被上传至网络,但是手动搜索和筛选所需信息需要耗费大量时间和精力。因此,利用网页书籍抓取工具可以快速获取所需信息。
三、如何进行网页书籍抓取?
1.使用Python语言编写爬虫程序;
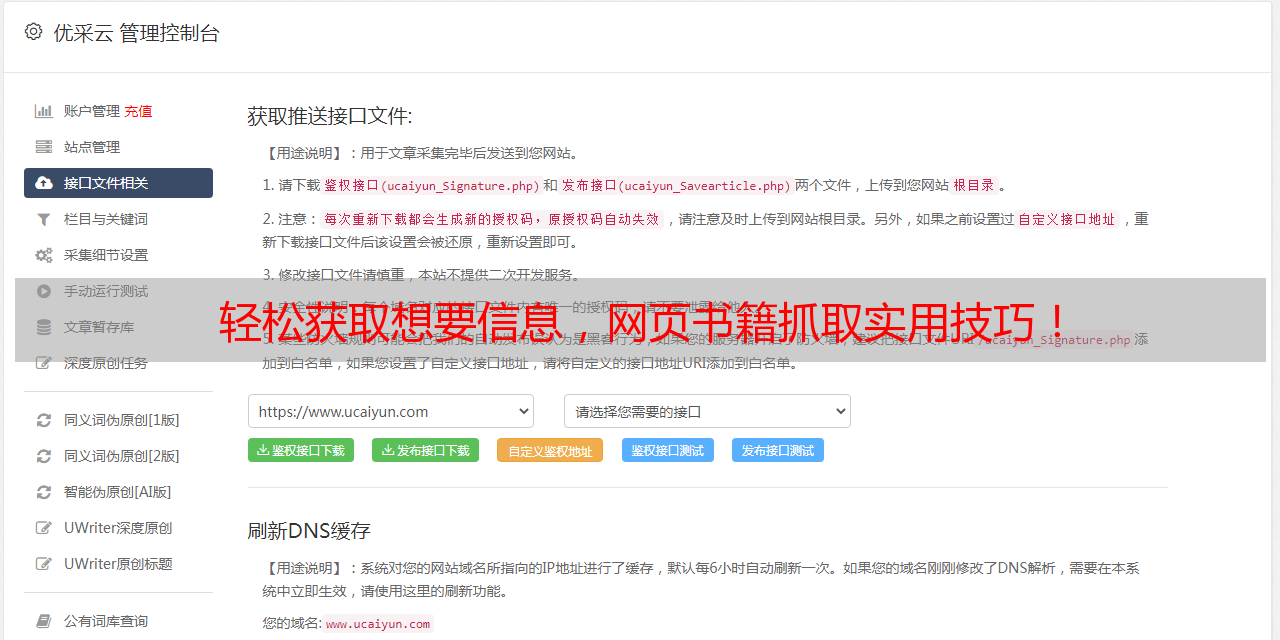
2.通过网络API接口调用第三方数据采集工具;
3.使用开源框架Scrapy进行数据爬取。
四、常用网页书籍抓取工具有哪些?
1. BeautifulSoup:一个用于解析HTML和XML文档的Python库;
2. Scrapy:一个用于数据抓取、处理和存储的Python框架;
3. Selenium:一个用于Web应用程序测试的自动化工具,也可以用于数据抓取。
五、网页书籍抓取的难点是什么?

1.网站反爬虫机制;
2.数据格式不统一,需要进行清洗和处理;
3.数据量庞大,需要进行有效的存储和管理。
六、如何应对网站的反爬虫机制?
1.降低请求频率,避免过多请求被拦截;
2.模拟用户行为,如模拟登录、浏览等;
3.更换IP地址,避免被封禁。
七、如何处理数据格式不统一的问题?
1.使用正则表达式对数据进行匹配和提取;
2.使用Python库进行数据清洗和处理。
八、如何有效地存储和管理数据?
1.使用数据库进行数据存储和管理;
2.利用云端存储服务,如阿里云、腾讯云等。
综上所述,通过网页书籍抓取可以大幅度提高信息获取效率。但是,在使用网页书籍抓取工具时需要注意网站反爬虫机制,数据格式不统一以及数据存储和管理等问题。如果您需要更多关于网页书籍抓取的信息,可以了解优采云,并进行SEO优化,网址为www.ucaiyun.com。

