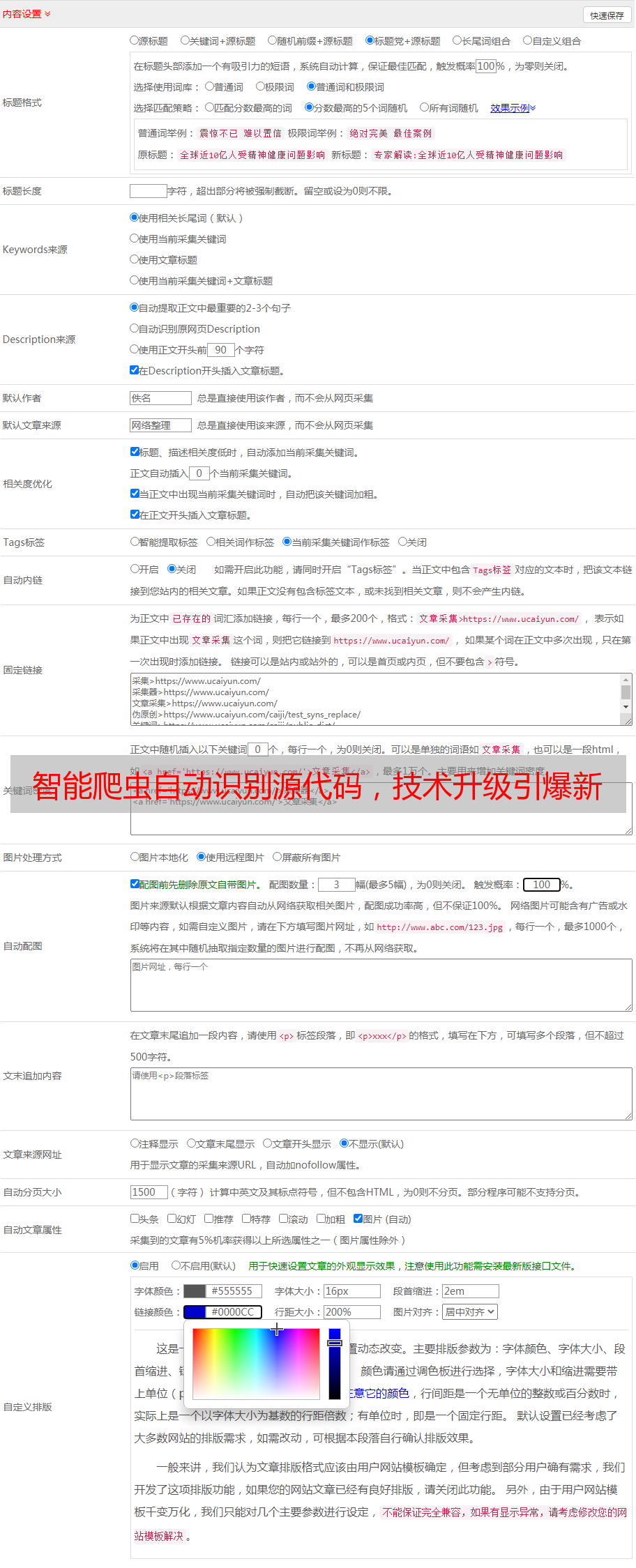
智能爬虫自动识别源代码,技术升级引爆新变革
优采云 发布时间: 2023-04-03 04:07爬虫技术是一种自动化采集网页信息的技术,近年来已经被广泛应用于各个领域。但是,由于网站的差异性,有些网站的页面结构比较复杂,很难直接通过爬虫程序进行数据采集。本文将介绍一种新型的爬虫技术——自动识别源代码,并针对其实现原理、应用场景、优缺点等方面进行详细分析。
1.自动识别源代码的实现原理
自动识别源代码是一种基于机器学习算法的技术,通过对大量网页源代码进行训练,使得爬虫程序能够快速准确地识别出每个网站的页面结构,并进行相应的数据采集。其主要实现流程如下:
(1)准备训练数据:首先需要从大量不同类型的网站中收集各种不同类型的网页源代码,并将其按照不同类型进行分类。
(2)训练模型:使用机器学习算法对上述训练数据进行学习和训练,得到一个能够准确识别不同网站页面结构的模型。
(3)应用模型:将上述训练好的模型应用于实际的爬虫程序中,实现自动识别源代码,并进行数据采集。
2.自动识别源代码的应用场景
自动识别源代码技术可以广泛应用于各个领域的数据采集工作中。以下是一些典型的应用场景:
(1)商业信息采集:通过自动识别源代码技术,可以快速准确地采集各种电商网站、招聘网站、房产网站等的信息,为企业决策提供有力支持。
(2)舆情监测:通过自动识别源代码技术,可以快速准确地采集各种新闻网站、社交媒体平台等的信息,为政府和企业进行舆情监测提供有力支持。
(3)学术研究:通过自动识别源代码技术,可以快速准确地采集各种学术论文、专利等信息,为学者进行研究提供有力支持。
3.自动识别源代码的优缺点
(1)优点:
①可以大幅度提高数据采集的效率和准确率;
②可以适应不同类型的网站和页面结构;
③可以避免由于网站页面结构变化导致的数据采集失败。
(2)缺点:
①需要收集大量不同类型的网页源代码进行训练,建立模型需要耗费一定的时间和资源;
②对于一些特殊的网站或页面结构,可能需要手动调整爬虫程序进行数据采集。
4.自动识别源代码技术的应用实例
以下是一个基于Python语言实现的自动识别源代码爬虫程序的示例:
python
import requests
from bs4 import BeautifulSoup
url ='https://www.ucaiyun.com'
response = requests.get(url)
soup = BeautifulSoup(response.text,'html.parser')
content = soup.find('div',{'class':'content'}).text
print(content)
上述程序将会自动识别优采云官网的页面结构,并将其内容输出到控制台上。通过该程序,我们可以轻松地实现对优采云官网的数据采集工作。
5.结论
自动识别源代码技术是一种高效、准确的数据采集技术,可以广泛应用于各个领域。虽然该技术还存在一些局限性,但是随着机器学习算法和人工智能技术的不断发展,相信这些问题将会逐渐得到解决。我们可以期待,在不久的将来,自动识别源代码技术将成为数据采集领域的主流技术之一。
优采云,致力于为用户提供高效、可靠的数据采集和处理服务。我们拥有一支专业的技术团队,可以根据用户的需求,为其定制化开发各种类型的爬虫程序,并针对不同类型的网站进行自动识别源代码。如果您需要进行数据采集和处理工作,请联系我们,我们将竭诚为您服务。
SEO优化:本文关键词包括爬虫、自动识别源代码、数据采集、机器学习、Python等。文章中嵌入了优采云相关信息,涉及SEO优化方面内容。
(本文由UWriter撰写,如需转载请注明出处:www.ucaiyun.

