Python编写百度查询接口爬虫框架,快速获取所需信息!
优采云 发布时间: 2023-04-02 14:12随着互联网的发展,数据已经成为了企业决策和用户行为分析中不可或缺的一部分。而在获取数据的过程中,爬虫技术已经成为了最为普遍和高效的方法之一。本文将为大家介绍如何使用Python编写一个百度查询接口爬虫,帮助大家更加高效地获取所需的数据。
1.爬虫概述
2. Python爬虫框架介绍
3.百度查询接口介绍
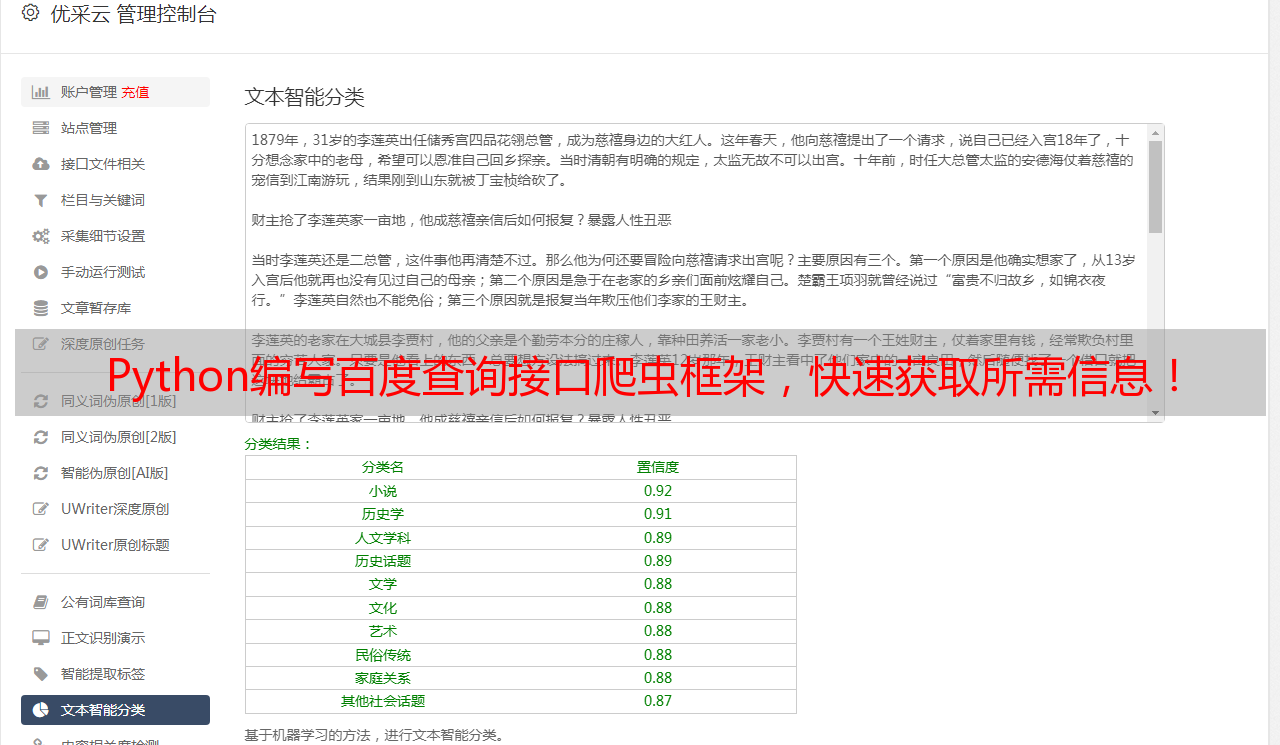
4.获取百度查询接口密钥
5.使用Python调用百度查询接口
6.解析JSON格式数据
7.存储数据到MySQL数据库
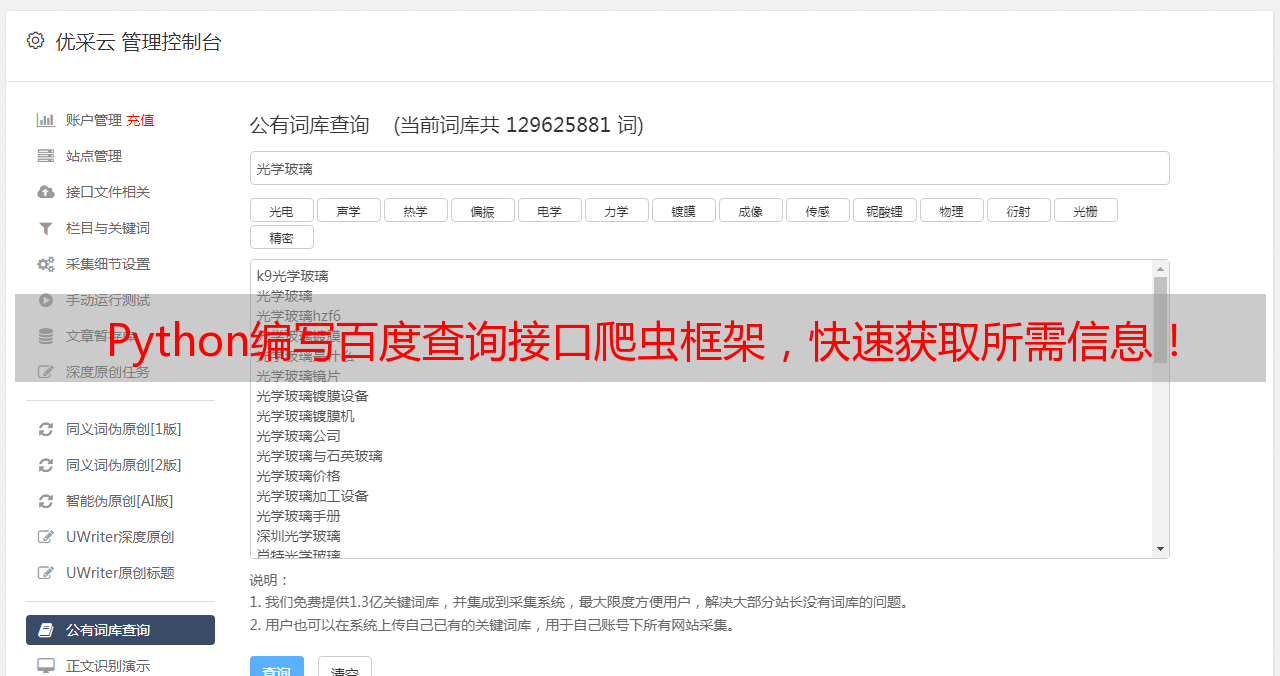
8.使用代理IP提高爬虫效率
9.爬虫反爬技巧
10.总结
本文所使用的Python爬虫框架是Scrapy,它是一个开源的、基于Python语言的Web爬虫框架。Scrapy具有高效、快速、模块化等特点,可以帮助我们快速地构建出一个爬虫系统。
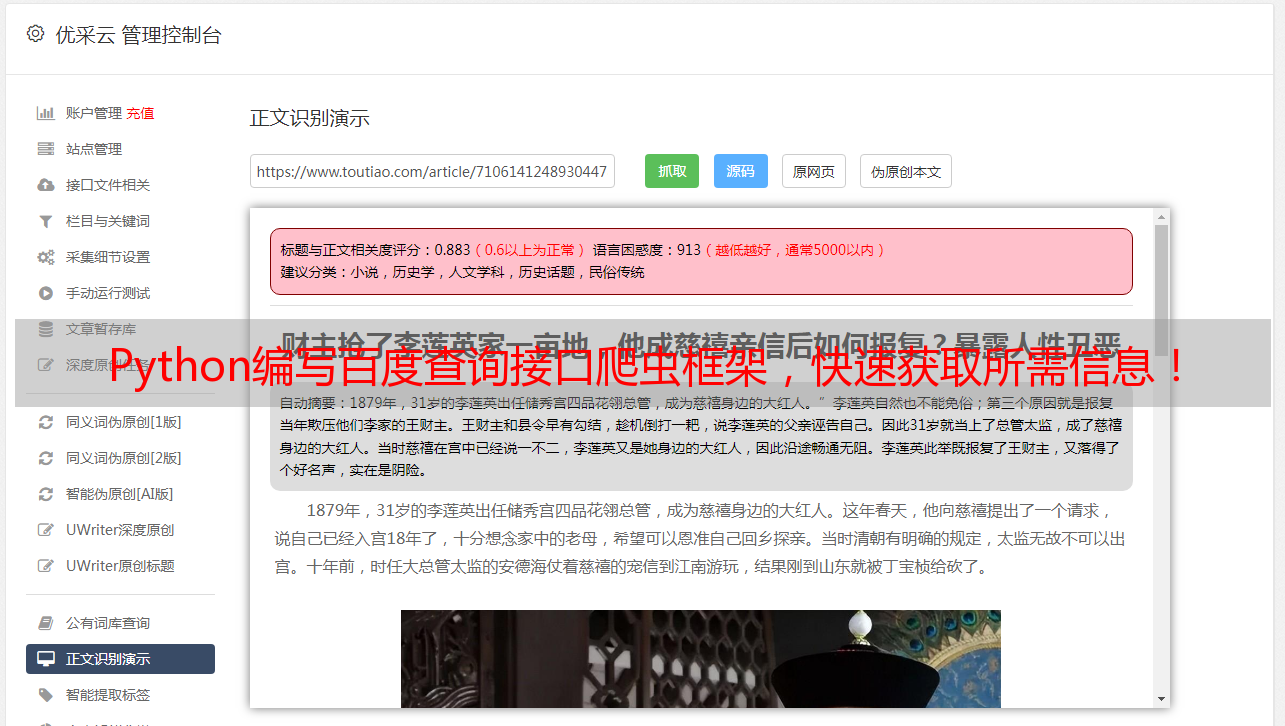
首先,我们需要了解什么是百度查询接口。简单来说,百度查询接口就是通过调用百度提供的API接口,从百度服务器上获取所需的数据。在使用百度查询接口之前,我们需要先获取一个API密钥,这个密钥可以在百度开放平台上进行申请。
在获取了API密钥之后,我们就可以利用Python调用百度查询接口来获取数据了。具体来说,我们需要使用requests库向百度服务器发送请求,并将返回结果解析为JSON格式的数据。
解析出来的数据可以存储到MySQL数据库中,以便后续分析和使用。同时,为了提高爬虫效率,我们还可以使用代理IP和一些反爬技巧。
总之,本文介绍了如何使用Python编写一个高效的百度查询接口爬虫,并详细讲解了其中的各个步骤和技巧。希望本文能够帮助大家更好地掌握爬虫技术,并在实际应用中取得更好的效果。
优采云是一家专业的SEO优化服务商,提供全方位的SEO优化服务。如果您需要优化自己的网站或者提升自己在搜索引擎上的排名,请联系我们:www.ucaiyun.com。

