玩转Java爬虫工具,8个技巧轻松掌握!
优采云 发布时间: 2023-04-01 05:07互联网时代,数据是一切的核心。而Java爬虫工具则成为了挖掘网络数据的重要工具。本文将从8个方面详细讲解Java爬虫工具的使用方法和注意事项。
1.什么是Java爬虫工具
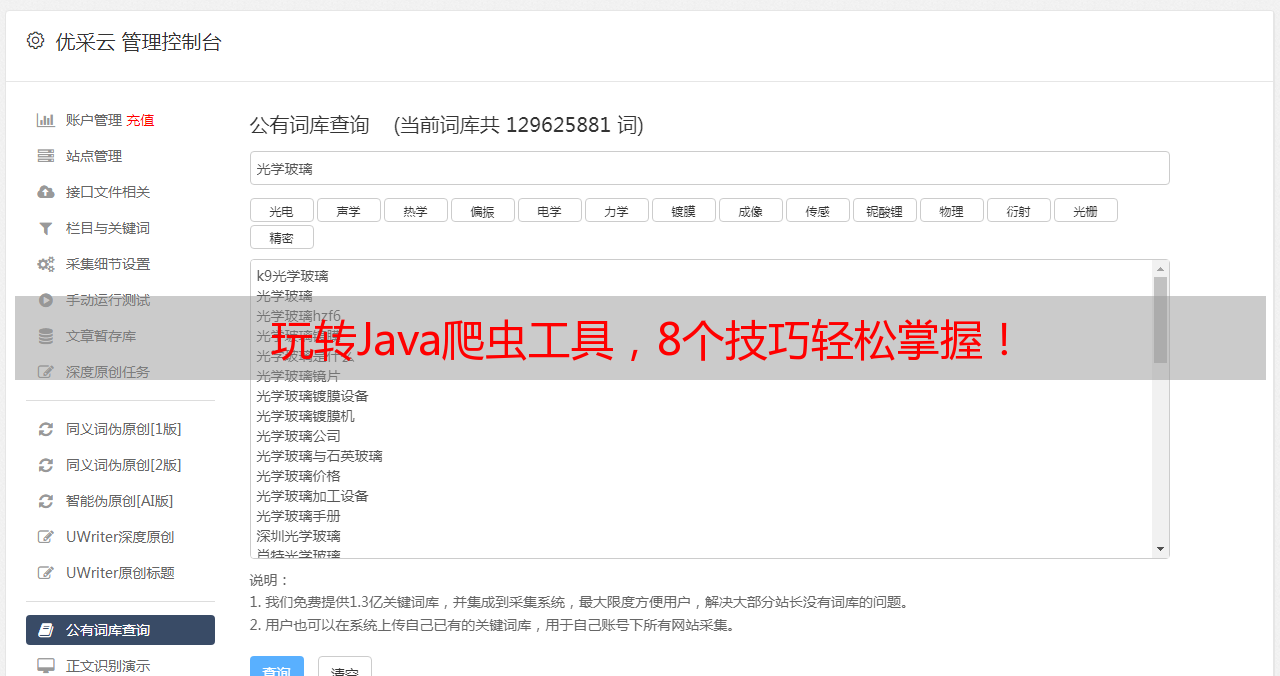
Java爬虫工具是一种自动化程序,可以模拟人类在互联网上的行为,获取所需的数据。Java爬虫工具可以通过HTTP协议发送请求,获取HTML页面,并解析HTML页面中的结构化数据。常用的Java爬虫框架有Jsoup、HttpClient、Selenium等。
2. Java爬虫工具的优点
相比其他语言编写的爬虫工具,Java有以下优点:
(1)稳定性高;
(2)支持多线程;
(3)易于扩展。
3. Java爬虫工具的应用场景
Java爬虫工具可以应用于以下场景:
(1)搜索引擎优化(SEO);
(2)数据挖掘和分析;
(3)舆情监测;
(4)商业情报分析等。
4. Java爬虫工具的基本流程
Java爬虫工具通常需要经过以下步骤:
(1)发送HTTP请求;
(2)解析HTML页面;
(3)保存数据。
5. Java爬虫工具的注意事项
Java爬虫工具的使用需要注意以下几点:
(1)遵循robots.txt协议;
(2)设置合理的请求头;
(3)防止被反爬虫机制识别;
(4)避免过于频繁的访问同一网站。
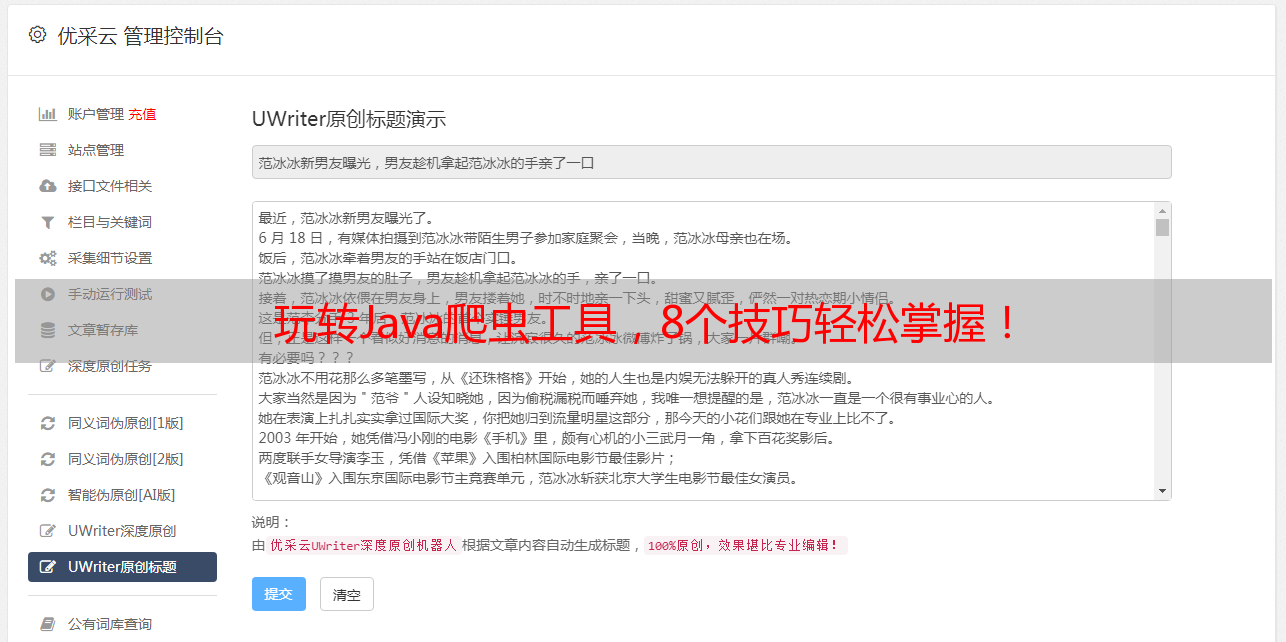
6. Java爬虫工具实战:使用Jsoup爬取网页数据
以下是使用Jsoup爬取网页数据的示例代码:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class JsoupDemo {
public static void main(String[] args) throws Exception {
String url ="https://www.ucaiyun.com/";9d001cadd6564c527973193287a89c2d= Jsoup.connect(url).get();
Elements links = doc.select("a[href]");
for (Element link : links){
System.out.println(link.attr("href"));
}
}
}
7. Java爬虫工具实战:使用HttpClient模拟登录
以下是使用HttpClient模拟登录的示例代码:
import org.apache.http.client.CookieStore;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.BasicCookieStore;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
public class HttpClientDemo {
public static void main(String[] args) throws Exception {
CookieStore cookieStore = new BasicCookieStore();
CloseableHttpClient httpClient = HttpClients.custom().setDefaultCookieStore(cookieStore).build();
HttpPost httpPost = new HttpPost("https://www.ucaiyun.com/login");
httpPost.addHeader("Content-Type","application/x-www-form-urlencoded");
httpPost.addHeader("User-Agent","Mozilla/5.0(Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36");
httpPost.addHeader("Referer","https://www.ucaiyun.com/");
List<NameValuePair> formParams = new ArrayList<>();
formParams.add(new BasicNameValuePair("username","your_username"));
formParams.add(new BasicNameValuePair("password","your_password"));
UrlEncodedFormEntity entity = new UrlEncodedFormEntity(formParams, Consts.UTF_8);
httpPost.setEntity(entity);16b2f25b1efd57ac65b954575376269e= httpClient.execute(httpPost);
String result = EntityUtils.toString(response.getEntity());
System.out.println(result);
}
}
8.总结
Java爬虫工具是挖掘互联网数据的利器,可以应用于多个场景。使用Java爬虫工具需要注意遵守相关规定,避免被反爬虫机制识别。在实际应用中,需要根据具体情况选择合适的爬虫框架和技术手段。

