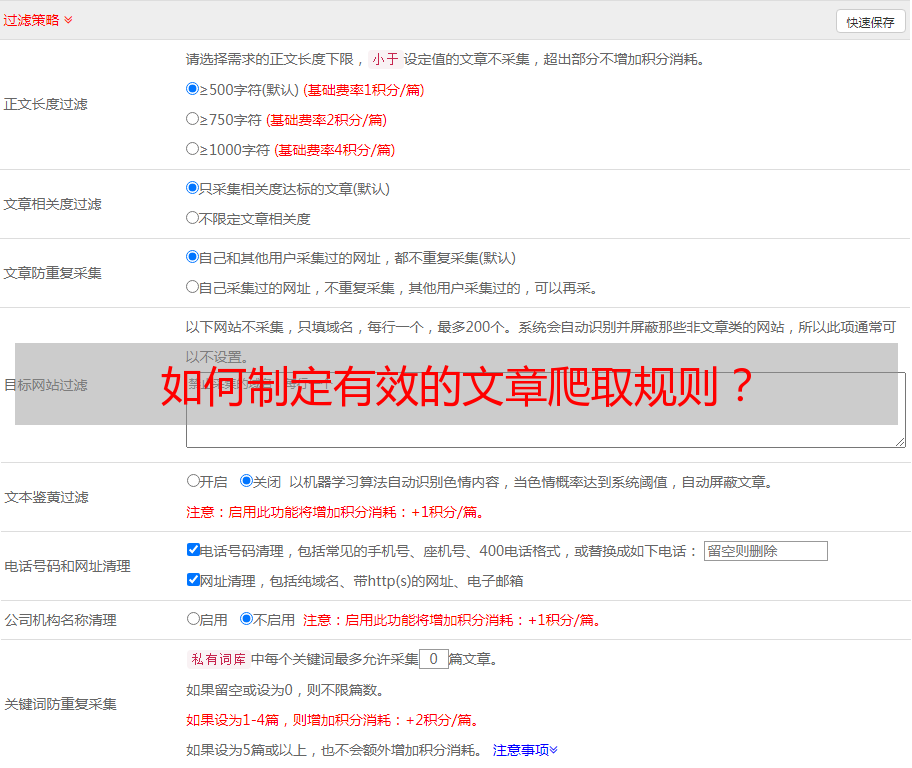
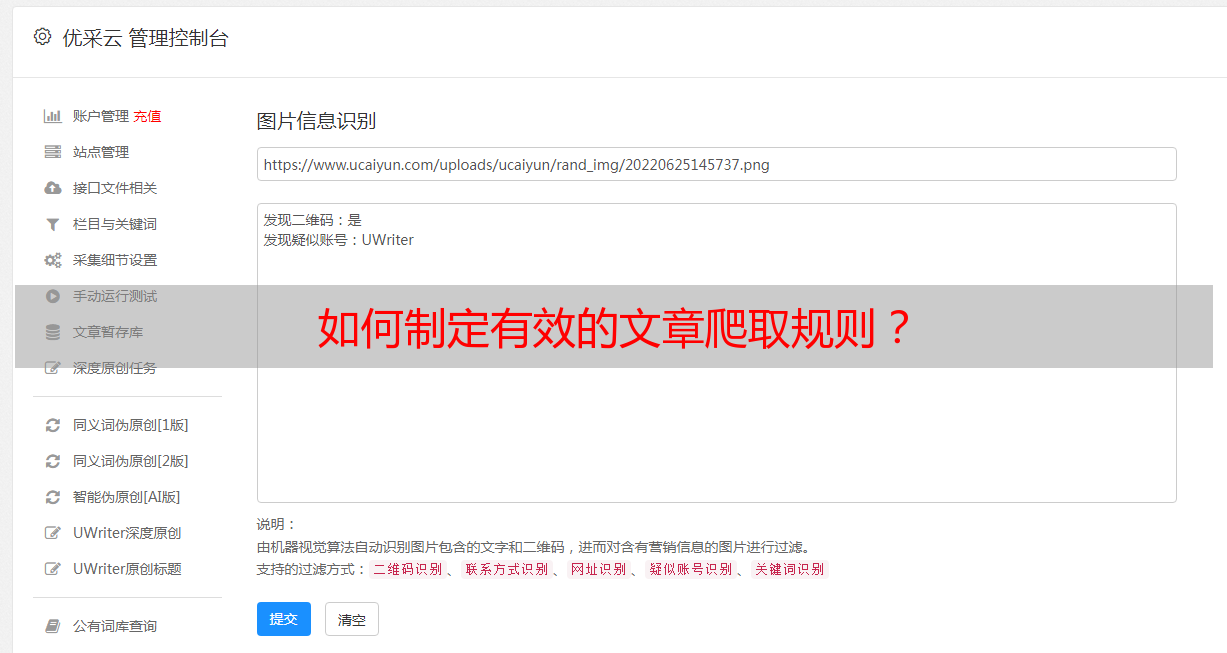
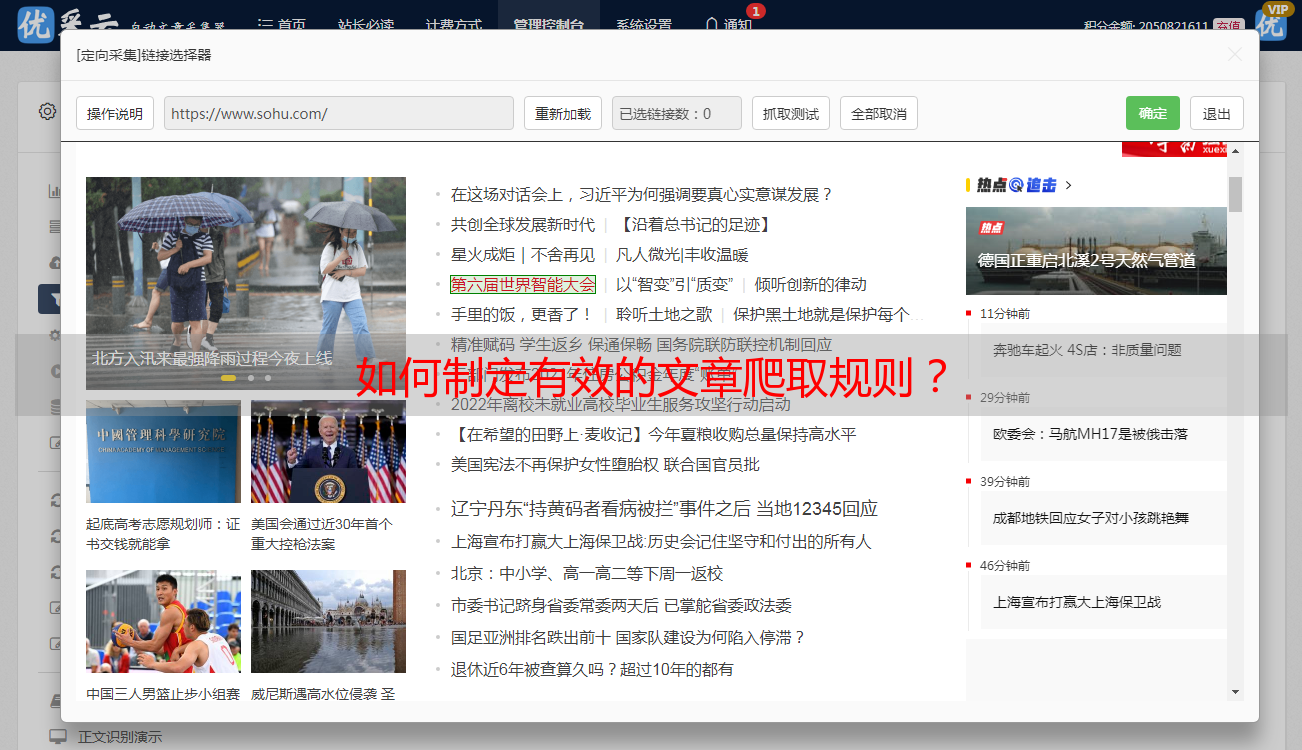
如何制定有效的文章爬取规则?
优采云 发布时间: 2023-04-01 01:09爬虫是一种获取互联网数据的技术,而爬取文章也是其中常见的应用之一。但是,爬取文章的过程中需要遵循一定的规则,否则就会涉及到版权等问题。那么,爬取文章的规则怎么定呢?
1.明确目的
在开始爬取文章之前,需要明确自己的目的。是为了获取信息,还是为了转载?如果是为了获取信息,则需要注意保护原作者的版权;如果是为了转载,则需要遵守相关法律法规。
2.尊重版权
无论是获取信息还是转载,都需要尊重原作者的版权。在爬取文章时,应该注明出处,并且不得篡改、修改原文内容。
3.遵守robots.txt协议
robots.txt协议是网络爬虫必须遵守的协议之一。该协议定义了哪些页面可以被搜索引擎爬虫访问,哪些页面不允许被访问。因此,在爬取文章时,需要先查看对方网站是否有robots.txt文件,并遵守其中规定。
4.限制爬取频率
频繁地访问对方网站会对其服务器造成负担,也容易被对方网站封禁。因此,在爬取文章时,需要限制访问频率,避免对对方网站造成影响。
5.不要过度爬取
在爬取文章时,不要一次性爬取大量文章,否则容易被对方网站封禁。应该控制爬取数量,并且定期更新已经爬取的文章。
6.避免重复爬取
为了避免重复爬取已经存在的文章,可以使用哈希值或者时间戳等方式进行去重处理。
7.防止反爬虫
为了防止对方网站采取反爬虫措施,可以使用代理IP、随机UA等方式进行反反爬虫处理。
8.保护个人信息
在爬取文章时,需要注意保护个人信息。不要将获取到的用户数据用于非法用途,并对用户数据进行加密处理。
9.优化SEO
在进行文章转载时,需要对其进行SEO优化。例如添加关键词、优化标题和描述等方式,以提高文章的搜索排名。
总之,在进行文章爬取时,需要遵守相关法律法规,并且注重保护原作者的版权。同时,也需要注意数据安全和隐私保护。如果您需要更多关于数据采集的技术支持,请访问优采云(www.ucaiyun.com)。

