轻松获取所需信息,教你网页文章提取技巧
优采云 发布时间: 2023-03-31 06:12在互联网时代,我们每天都需要从海量的网页中获取所需信息。但是,有时候我们只需要其中的一小部分内容,却需要在繁杂的页面中寻找。这时候,网页文章提取就显得尤为重要。本文将介绍网页文章提取的方法和技巧,帮助你轻松获取所需信息。
1.什么是网页文章提取?
在浏览网页时,我们经常会遇到需要提取某个特定信息的情况。比如,在一个新闻网站上看到一篇报道,只想获取其中的标题、作者和正文内容。这时候,就需要使用网页文章提取技术来获取所需信息。
2.常用的网页文章提取工具
目前市面上有很多优秀的网页文章提取工具,比如Python中的BeautifulSoup、Scrapy等;还有一些浏览器插件,如FireShot、Evernote等。这些工具可以根据自己的需求选择使用。
3.使用BeautifulSoup进行网页文章提取
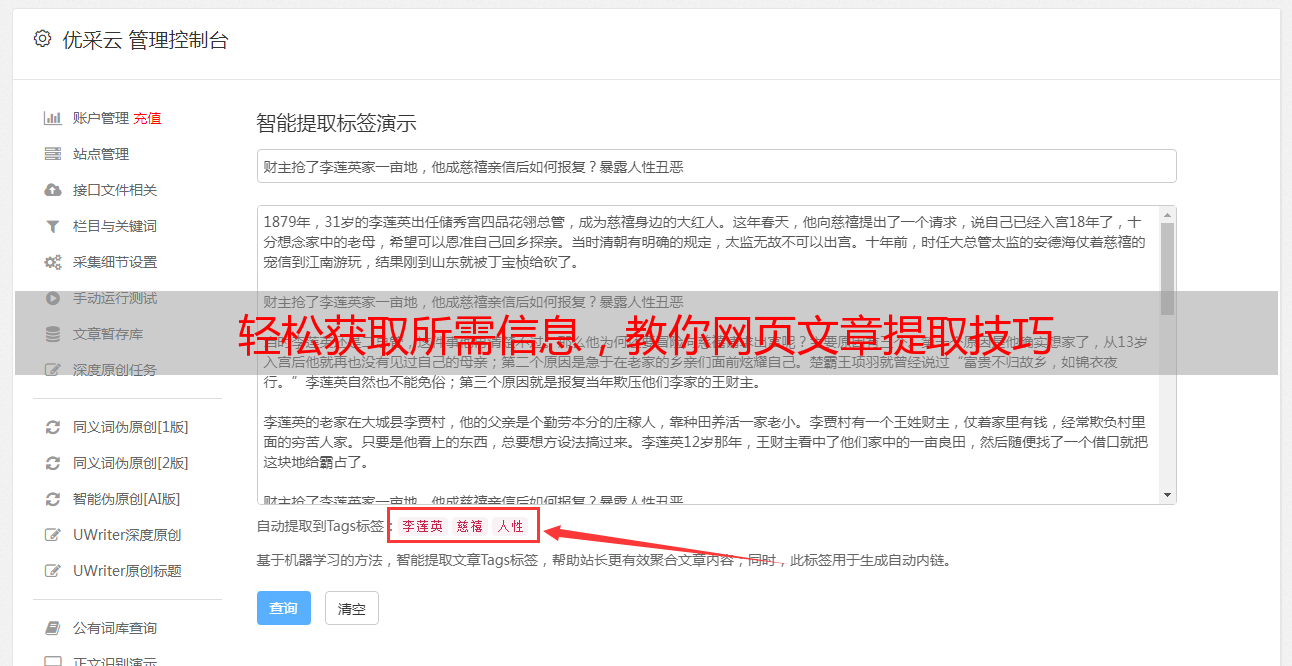
BeautifulSoup是一个Python库,可以用于从HTML或XML文件中提取数据。它能够解析HTML标记,并将其转换成Python对象,使用户可以轻松地遍历和搜索HTML文档中的元素。
下面是一个简单的示例,演示如何使用BeautifulSoup从网页中提取标题和正文内容:
from bs4 import BeautifulSoup
import requests
url ='https://www.example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text,'html.parser')
#获取标题
title = soup.title.string
#获取正文内容
content = soup.find('div', class_='article-content').get_text()
print(title)
print(content)
4.使用Scrapy进行网页文章提取
Scrapy是一个Python框架,可以用于爬取网站并提取数据。它具有高效性、灵活性和可扩展性,常被用于*敏*感*词*数据抓取。
下面是一个示例,演示如何使用Scrapy从网页中提取标题和正文内容:
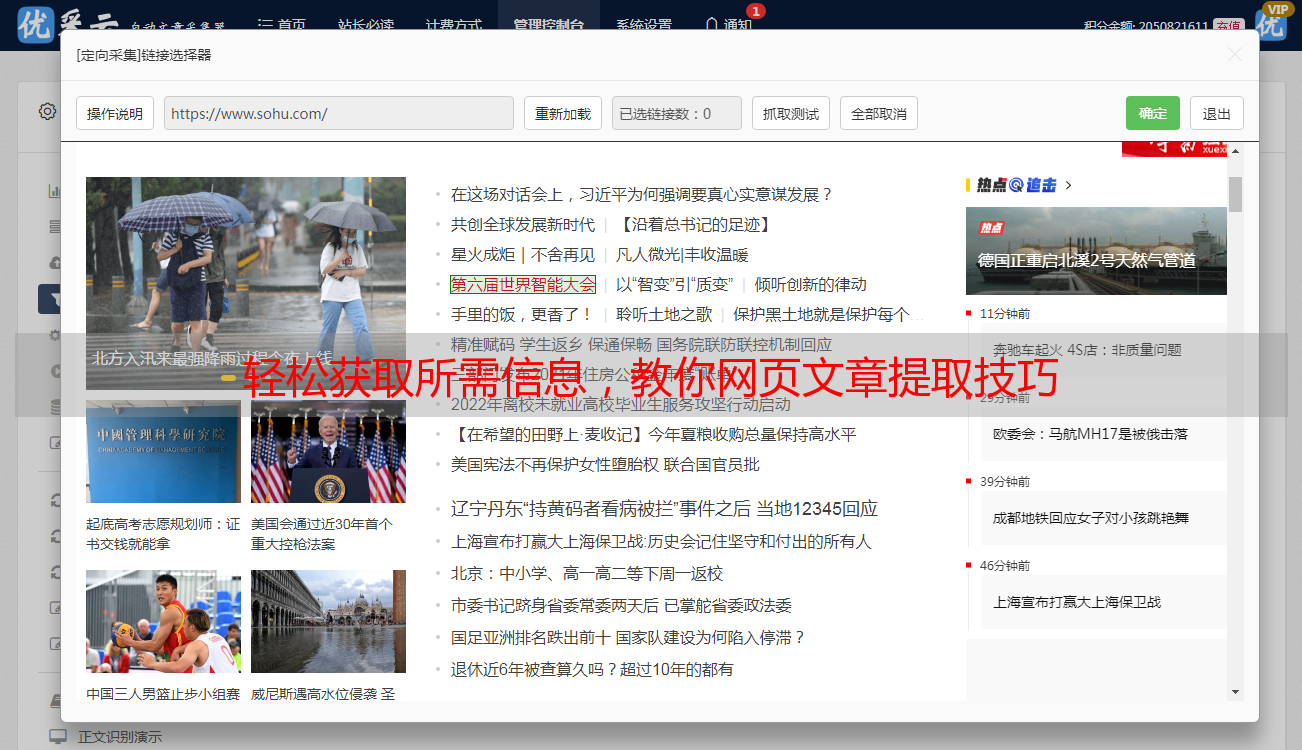
import scrapy
class ExampleSpider(scrapy.Spider):
name ="example"
start_urls =['https://www.example.com']
def parse(self, response):
#获取标题
title = response.css('title::text').get()
#获取正文内容
content = response.css('div.article-content::text').get()
yield {
'title': title,
'content': content,
}
5.网页文章提取的注意事项
在进行网页文章提取时,需要注意以下几点:
-确定好所需信息的位置和标记;
-避免过度频繁地请求同一页面,以免被封IP;
-注意网站的反爬虫机制,不要给网站带来不必要的麻烦。
6.网页文章提取在SEO优化中的应用
网页文章提取技术在SEO优化中也有着重要的应用。通过提取网页中的标题、关键词和正文内容,可以帮助搜索引擎更好地理解网页的主题和内容,从而提升网站排名。
7.优采云:一站式SEO工具平台
如果你想更加轻松地进行网页文章提取和SEO优化,那么可以使用优采云这个一站式SEO工具平台。它提供了包括关键词分析、竞争对手分析、链接分析、网站监控等多种功能,帮助用户轻松实现SEO优化。
8.总结
本文介绍了网页文章提取的方法和技巧,以及其在SEO优化中的应用。希望能够帮助读者更加轻松地获取所需信息,并实现更好的网站排名。

