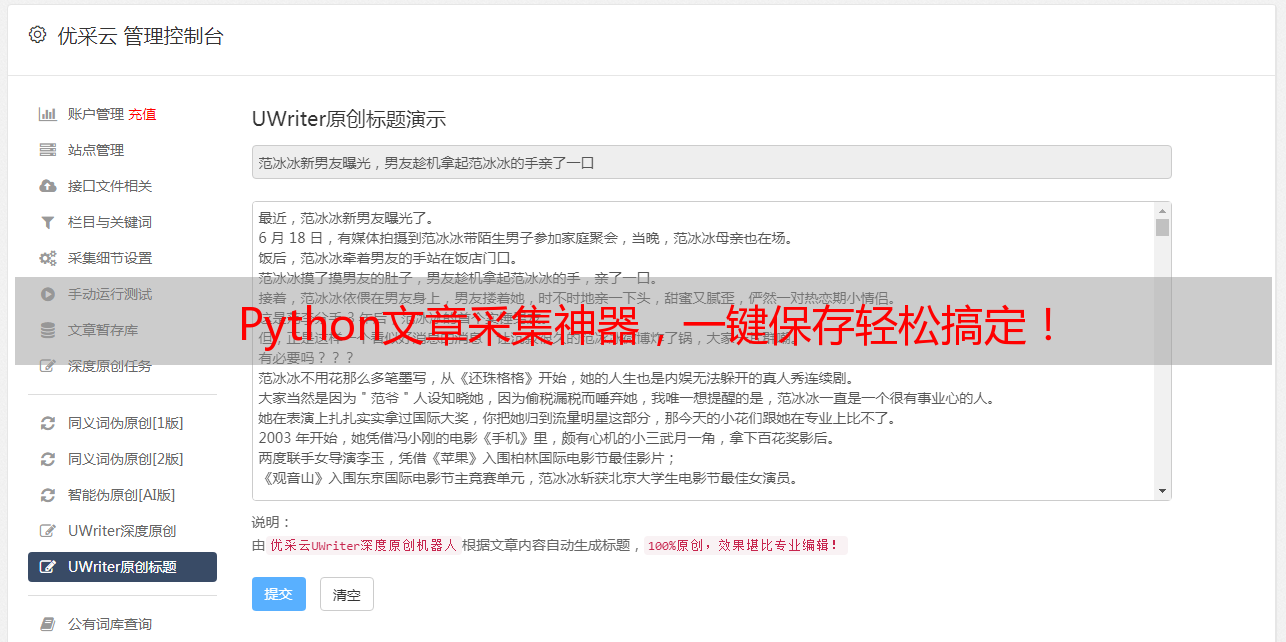
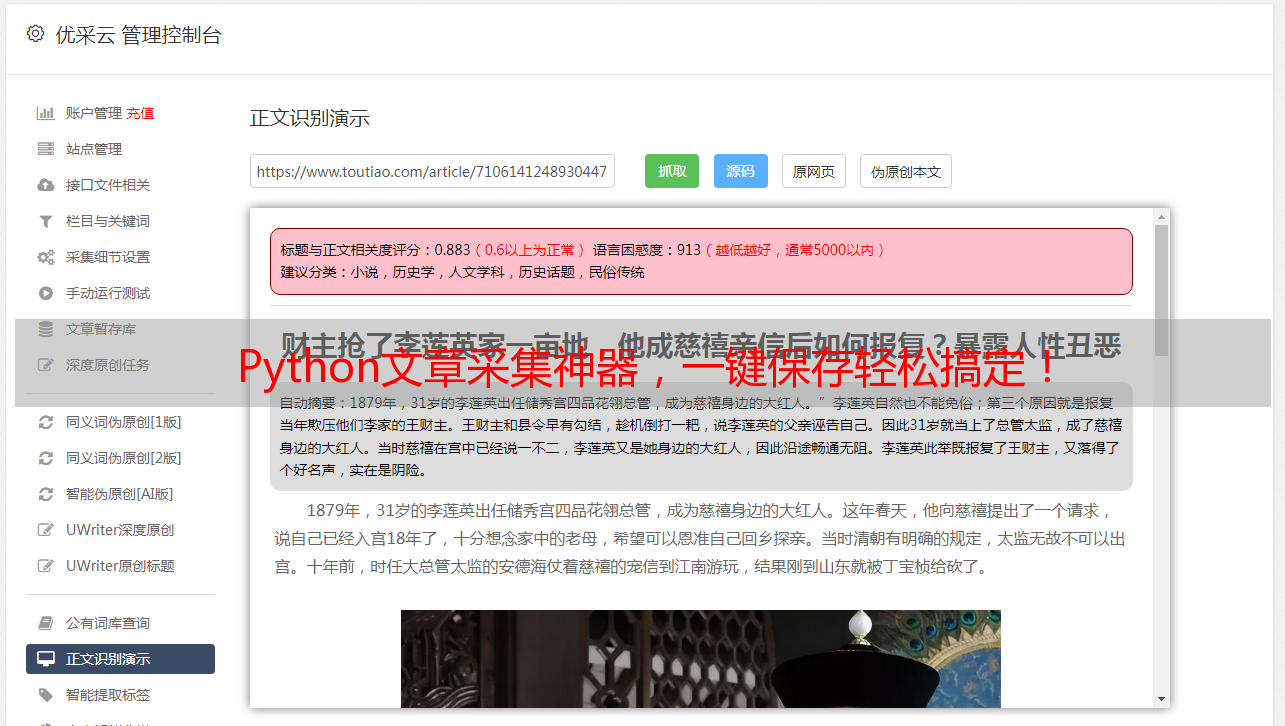
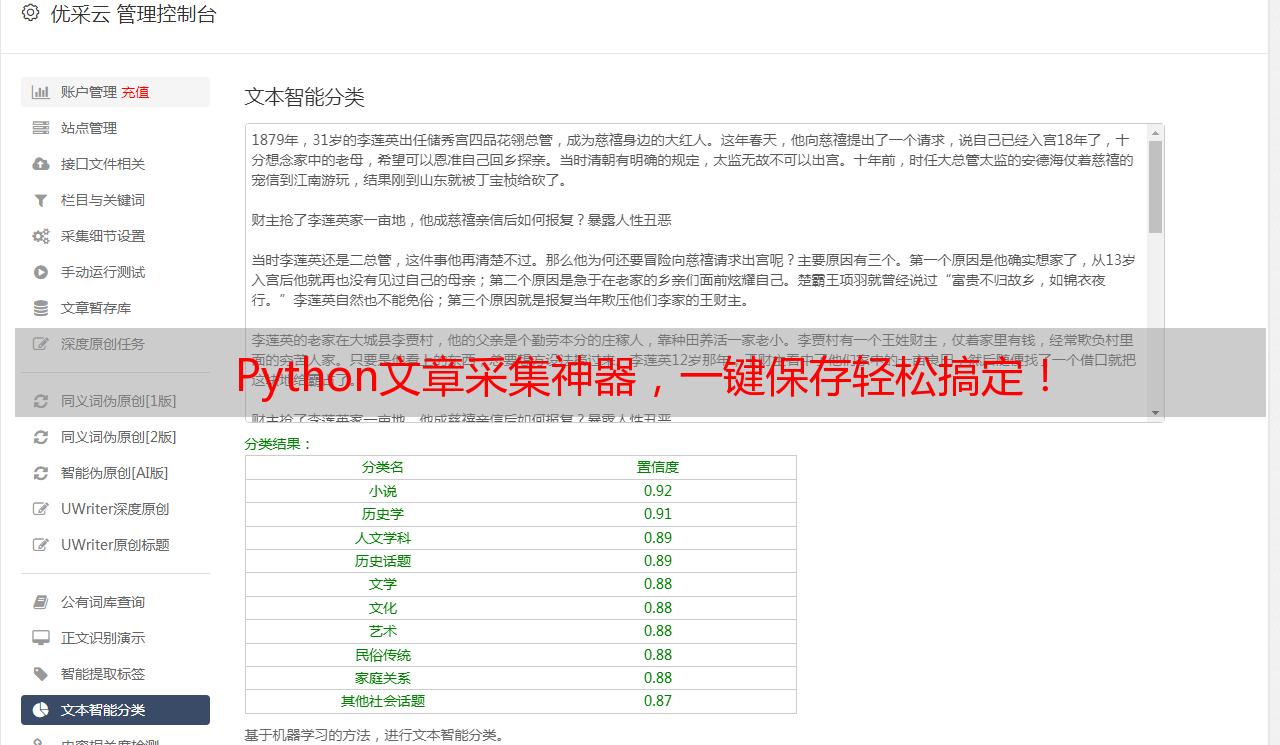
Python文章采集神器,一键保存轻松搞定!
优采云 发布时间: 2023-03-29 20:19在大数据时代,数据是企业和个人决策的重要依据。而如何获取大量的数据则成为了一个重要的问题。Python 作为一种高效、简洁、易于学习和使用的编程语言,被广泛应用于数据采集和处理领域。本文将为大家介绍 Python 采集文章保存的方法,帮助大家更好地获取所需数据。
1.确定数据来源
在开始采集之前,我们需要确定所需数据的来源。可以通过搜索引擎、社交媒体、论坛等途径来获取所需数据。需要注意的是,不同网站的页面结构可能有所不同,需要根据实际情况进行调整。
2.安装必要的库
在 Python 中,我们可以利用 Requests 库来发送 HTTP 请求,并利用 BeautifulSoup 库来解析 HTML 页面。因此,在开始采集之前,我们需要安装这两个库。
python
import requests
from bs4 import BeautifulSoup
3.发送 HTTP 请求
在获取网页内容之前,我们需要先发送 HTTP 请求。下面是一个简单的示例代码:
python
url ='https://www.ucaiyun.com'
response = requests.get(url)
其中,url 是所需数据的网址。requests.get()方法会向该网址发送 GET 请求,并返回一个 Response 对象。
4.解析 HTML 页面
获取到 Response 对象之后,我们需要从中提取所需数据。这时,我们可以利用 BeautifulSoup 库来解析 HTML 页面。下面是一个简单的示例代码:
python
soup = BeautifulSoup(response.text,'html.parser')
其中,response.text 是 Response 对象的文本内容。'html.parser'是一个解析器,用于解析 HTML 页面。
5.提取所需数据
在解析 HTML 页面之后,我们需要从中提取所需数据。可以通过查看网页源代码来确定所需数据的位置,并使用 BeautifulSoup 库提供的方法进行提取。下面是一个简单的示例代码:
python
data = soup.find('div',{'class':'content'}).text
其中,'div'表示要查找的标签名,{'class':'content'}表示要查找的标签属性。text 属性表示要提取的文本内容。
6.保存数据
在获取到所需数据之后,我们需要将其保存下来以备后续分析。可以将数据保存为 CSV、JSON、Excel 等格式。下面是一个简单的示例代码:
python
import csv
with open('data.csv','w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['title','content'])
writer.writerow([title, content])
其中,'data.csv'是保存数据的文件名。writerow()方法用于向 CSV 文件中写入一行数据。
7.自动化采集
如果需要采集大量的数据,手动采集显然是不可行的。这时,我们可以编写 Python 脚本来自动化采集。可以利用循环语句和条件语句来实现自动化采集。下面是一个简单的示例代码:
python
import time
for page in range(1, 11):
url =f'https://www.ucaiyun.com?page={page}'
response = requests.get(url)
soup = BeautifulSoup(response.text,'html.parser')
data = soup.find_all('div',{'class':'content'})
for item in data:
title = item.find('h2').text
content = item.find('p').text
with open('data.csv','a', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow([title, content])
time.sleep(1)
其中,range(1, 11)表示要采集的页面范围。f'https://www.ucaiyun.com?page={page}'表示要采集的网址。find_all()方法用于查找所有符合条件的标签。
8.数据清洗和处理
在获取到大量数据之后,我们需要对其进行清洗和处理,以便后续分析。可以利用 Pandas 库来进行数据清洗和处理。下面是一个简单的示例代码:
python
import pandas as pd
df = pd.read_csv('data.csv')
df.drop_duplicates(inplace=True)
df.to_csv('cleaned_data.csv', index=False)
其中,'data.csv'是原始数据文件名,'cleaned_data.csv'是处理后的数据文件名。drop_duplicates()方法用于去除重复数据。
9.总结
Python 采集文章保存是一种高效、简洁、易于学习和使用的数据采集方法。通过使用 Requests 库和 BeautifulSoup 库,我们可以轻松地获取所需数据。通过自动化采集和数据清洗处理,我们可以大大提高数据采集和处理的效率。如果您需要更多关于 Python 数据采集和处理方面的内容,可以访问优采云(www.ucaiyun.com)了解更多信息。

