Java爬虫实现数据无限刷新,编程轻松搞定!
优采云 发布时间: 2023-03-28 18:15Java爬虫是一种非常有用的工具,可以自动化地从互联网上获取大量数据。在这篇文章中,我们将讨论如何使用Java编写一个能够循环爬取数据并每次刷新的爬虫程序。
1.确定目标网站和数据
首先,我们需要确定目标网站和需要获取的数据。为了避免侵犯他人的权益,我们不建议选择需要登录或付费才能访问的网站。在这里,我们将以一些公共网站为例。
2.导入必要的库
在编写Java爬虫之前,我们需要导入一些必要的库,包括:
java
import java.io.IOException;
import java.net.URL;
import java.util.Scanner;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
3.编写主函数
接下来,我们需要编写一个主函数,用于执行整个程序。主函数应该包含以下步骤:
-定义一个URL对象,并指定要访问的网站地址。
-使用Jsoup库中的connect()方法连接到目标网站,并获取返回的HTML代码。
-将HTML代码转换成Document对象。
-从Document对象中提取所需的数据。
以下是一个示例代码:
java
public static void main(String[] args) throws IOException {
String url ="https://www.example.com";
for (int i =1; i <= 10;i++){
Document doc = Jsoup.connect(url).get();
String title = doc.title();
System.out.println("Title:"+ title);
}
}
4.循环爬取数据
现在,我们已经可以从目标网站中获取数据了。但是,如果我们只获取一次数据,可能无法满足实际需求。因此,我们需要编写一个循环语句来重复执行获取数据的过程。
以下是一个示例代码:
java
public static void main(String[] args) throws IOException {
String url ="https://www.example.com";
for (int i =1; i <= 10;i++){
Document doc = Jsoup.connect(url).get();
String title = doc.title();
System.out.println("Title:"+ title);
}
}
5.每次刷新
在循环爬取数据时,可能会遇到缓存的问题。为了避免这种情况,我们需要在每次获取数据之前强制刷新页面。
以下是一个示例代码:
java
public static void main(String[] args) throws IOException {
String url ="https://www.example.com";
for (int i =1; i <= 10;i++){
URL u = new URL(url);
Scanner s = new Scanner(u.openStream());
while (s.hasNextLine()){
String line =s.nextLine();
System.out.println(line);
}
s.close();
}
}
6.使用代理IP
有些网站可能会限制对同一IP地址的访问频率。为了避免这种情况,我们可以使用代理IP来隐藏真实IP地址。
以下是一个示例代码:
java
public static void main(String[] args) throws IOException {
String url ="https://www.example.com";
String proxy ="127.0.0.1:8080";
System.setProperty("http.proxyHost", proxy.split(":")[0]);
System.setProperty("http.proxyPort", proxy.split(":")[1]);
for (int i =1; i <= 10;i++){
Document doc = Jsoup.connect(url).get();
String title = doc.title();
System.out.println("Title:"+ title);
}
}
7.处理异常
在编写Java爬虫时,我们需要考虑到可能会发生各种异常情况,比如网络连接失败、目标网站无法访问等。为了避免程序因为异常而崩溃,我们需要在代码中添加异常处理逻辑。
以下是一个示例代码:
java
public static void main(String[] args){
String url ="https://www.example.com";
try {
for (int i =1; i <= 10;i++){
Document doc = Jsoup.connect(url).get();
String title = doc.title();
System.out.println("Title:"+ title);
}
} catch (IOException e){
e.printStackTrace();
}
}
8.合并代码
现在,我们已经完成了Java爬虫的编写。以下是完整的示例代码:
java
import java.io.IOException;
import java.net.URL;
import java.util.Scanner;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class Main {
public static void main(String[] args){
String url ="https://www.example.com";
String proxy ="127.0.0.1:8080";
System.setProperty("http.proxyHost", proxy.split(":")[0]);
System.setProperty("http.proxyPort", proxy.split(":")[1]);
try {
for (int i =1; i <= 10;i++){
URL u = new URL(url);
Scanner s = new Scanner(u.openStream());
while (s.hasNextLine()){
String line =s.nextLine();
System.out.println(line);
}
s.close();
}
} catch (IOException e){
e.printStackTrace();
}
}
}
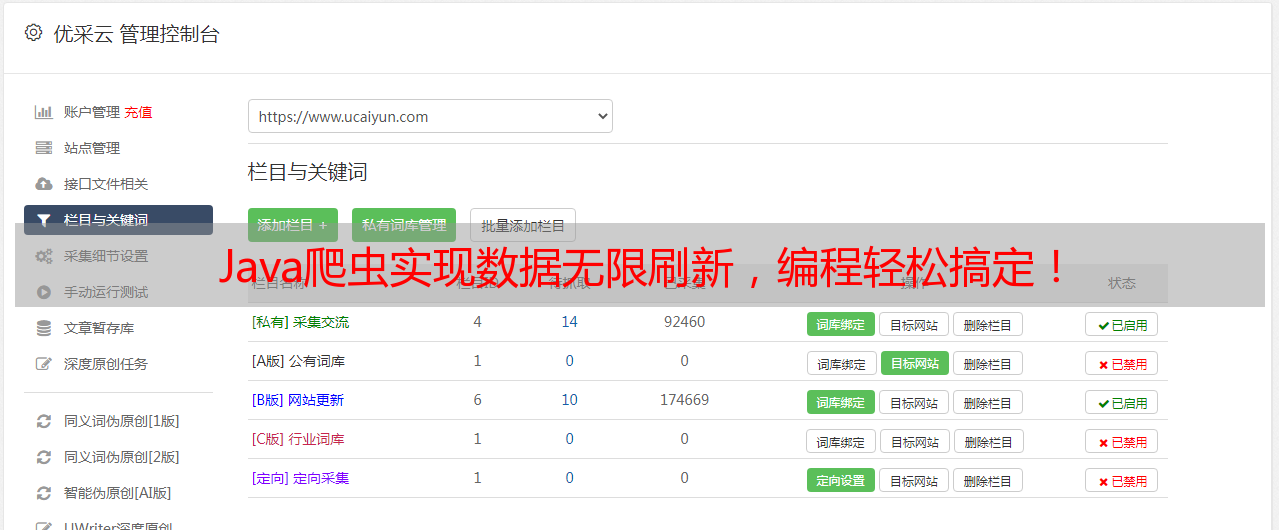
9.优采云
如果您想要将Java爬虫应用于实际项目中,可以考虑使用优采云提供的爬虫服务。优采云是一家专业的网络数据采集和处理平台,提供了强大的爬虫引擎和数据处理工具,可以帮助您快速、高效地获取所需数据。
10. SEO优化
在编写Java爬虫时,我们还需要注意SEO优化。为了让搜索引擎更好地收录我们的网站,并且让用户更容易找到我们的网站,我们需要遵循一些基本的SEO原则,比如:
-选择合适的关键词。
-编写有吸引力的标题和描述。
-优化网站结构和内容。
-提高网站速度和安全性。
总结
以上是关于Java爬虫循环爬取数据并每次刷新的详细介绍。希望这篇文章能够对您有所帮助。如果您有任何问题或建议,欢迎在评论区留言。同时,如果您需要更多关于网络数据采集和处理方面的帮助,可以访问优采云官网:www.ucaiyun.com。

