轻松掌握特定码抓取技巧,浏览器开发者工具帮你实现!
优采云 发布时间: 2023-03-27 19:15在网站开发和数据分析中,经常需要从页面中获取特定的代码或信息。如何快速准确地抓取网站特定码成为我们需要解决的问题。本文将从多个方面进行分析讨论,帮助读者轻松获取关键信息。
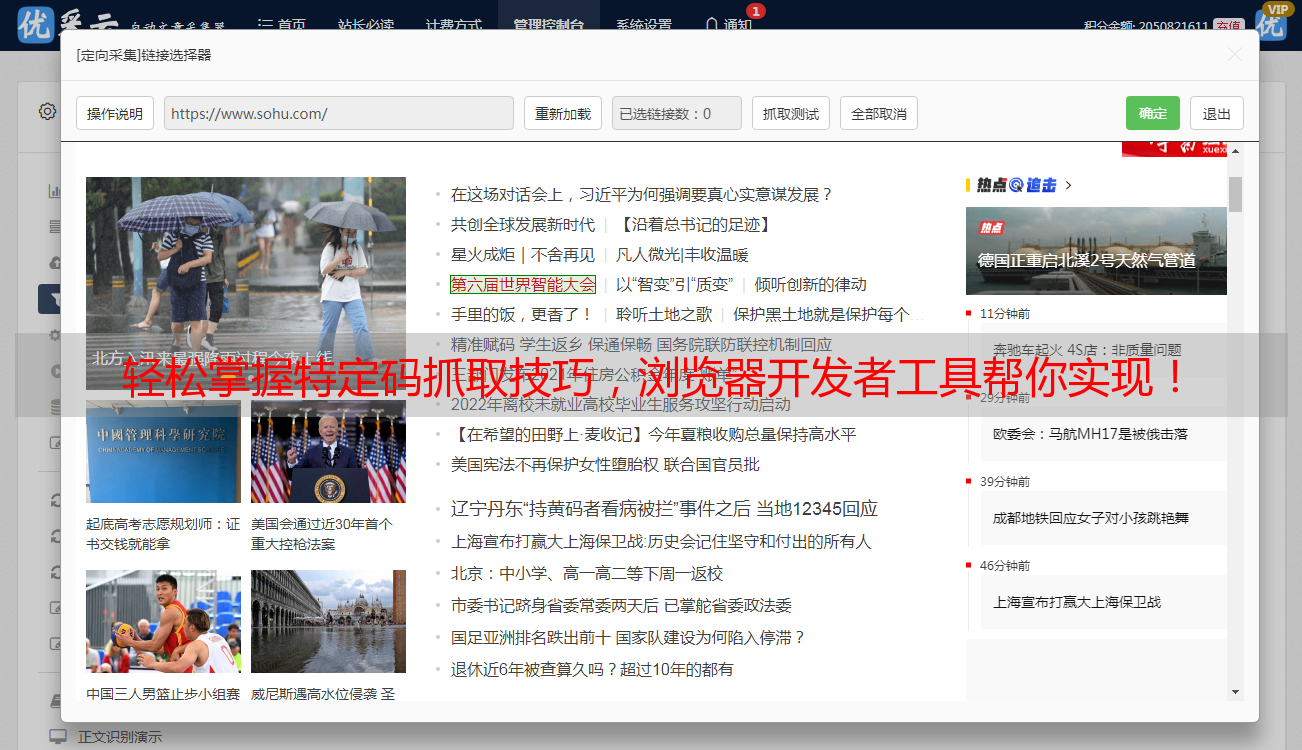
一、使用浏览器开发者工具抓取特定码
浏览器开发者工具是一款非常实用的工具,在网页开发和调试过程中经常使用。通过打开浏览器开发者工具,我们可以很容易地查看页面源代码,并找到我们需要的特定码。具体操作如下:
1.打开需要抓取特定码的网页;
2.在浏览器上右键点击页面中需要提取的内容,选择“检查”;
3.在弹出的开发者工具中,可以看到对应的HTML代码;
4.找到需要提取的标签或属性,复制对应代码即可。
二、使用Python爬虫抓取特定码
除了使用浏览器开发者工具外,我们也可以使用Python爬虫来抓取网站上的特定码。Python爬虫可以自动化地模拟用户的行为,获取网页上所需的数据。下面是一个简单的Python爬虫示例:
python
import requests
from bs4 import BeautifulSoup
url ='https://www.example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text,'html.parser')
target = soup.find('div',{'class':'target-class'})
print(target)
以上代码中,我们使用requests库发送HTTP请求,获取网页的HTML代码。然后使用BeautifulSoup库解析HTML代码,找到需要的特定码并输出。需要注意的是,在实际应用中需要加入异常处理等逻辑。
三、使用XPath抓取特定码
XPath是一种用于在XML文档中进行导航和选择的语言。在网页抓取中,我们可以使用XPath来选择需要的特定码。下面是一个XPath示例:
python
from lxml import etree
import requests
url ='https://www.example.com'
response = requests.get(url)
html = etree.HTML(response.text)
target = html.xpath('//div[@class="target-class"]')
print(target)
以上代码中,我们使用lxml库解析HTML代码,并使用XPath选择需要的特定码。需要注意的是,在实际应用中需要加入异常处理等逻辑。
四、使用正则表达式抓取特定码
正则表达式是一种强大的文本匹配工具,在网页抓取中也可以使用正则表达式来提取特定码。下面是一个正则表达式示例:
python
import re
import requests
url ='https://www.example.com'
response = requests.get(url)
pattern = re.compile('<div class="target-class">(.+?)</div>')
target = pattern.findall(response.text)
print(target)
以上代码中,我们使用re库编译正则表达式,并使用findall方法找到需要的特定码。需要注意的是,在实际应用中需要加入异常处理等逻辑。
五、使用第三方工具抓取特定码
除了以上几种方法外,还有许多第三方工具可以帮助我们抓取网站上的特定码。例如,Chrome插件SelectorGadget可以帮助我们快速选择需要的标签或属性。另外,一些数据分析平台也提供了网页抓取功能,例如优采云(www.ucaiyun.com),可以帮助用户轻松抓取网站上的数据。
六、注意事项
在进行网页抓取时,需要注意以下几点:
1.遵守Robots协议,不要对禁止抓取的页面进行操作;
2.不要频繁地请求同一个页面,以免对服务器造成过大负担;
3.注意隐私和版权问题,不要抓取敏感信息或侵犯他人版权;
4.在使用第三方工具时,需要注意安全性和可靠性。
七、总结
本文从多个方面介绍了如何抓取网站上的特定码。无论是使用浏览器开发者工具、Python爬虫、XPath还是正则表达式,都可以帮助我们轻松获取关键信息。在实际应用中,需要根据不同的情况选择合适的方法,并注意相关的注意事项。另外,第三方工具也可以帮助我们快速抓取网站上的数据,例如优采云(www.ucaiyun.com),可以帮助用户进行SEO优化和数据分析。

