爬虫抓取与页面检查:不同的数据收集方法
优采云 发布时间: 2023-03-26 21:15在进行网页爬取时,我们往往需要对页面进行检查,以获取所需的数据。但是,在实际操作中,我们会发现,有些页面在浏览器中打开后看到的内容和通过爬虫获取到的内容并不一样。这是为什么呢?本文将从多个方面进行分析。
一、动态加载
有些网站采用了动态加载技术,也就是说,在页面加载完成后,还会通过 JavaScript 等技术动态地向页面中添加内容。而在爬虫获取页面时,只会获取到最初的静态内容,无法获取后续动态添加的内容。
二、反爬机制
为了防止被爬虫抓取数据,一些网站采用了反爬机制。比如,设置了 IP 访问频率限制、验证码等手段来限制爬虫的访问。如果没有解决这些反爬机制,就无法正常地获取页面内容。
三、Cookie 和 Session
有些网站需要登录才能够访问某些页面或者进行某些操作。这时候就需要使用 Cookie 和 Session 来维持登录状态。如果在爬虫中没有正确地设置 Cookie 和 Session,则无法获取登录后的页面内容。
四、数据加密
为了保护用户隐私和数据安全,一些网站采用了数据加密技术,将传输的数据进行加密处理。如果没有正确地解密获取到的数据,就无法得到正确的页面内容。
五、网站架构
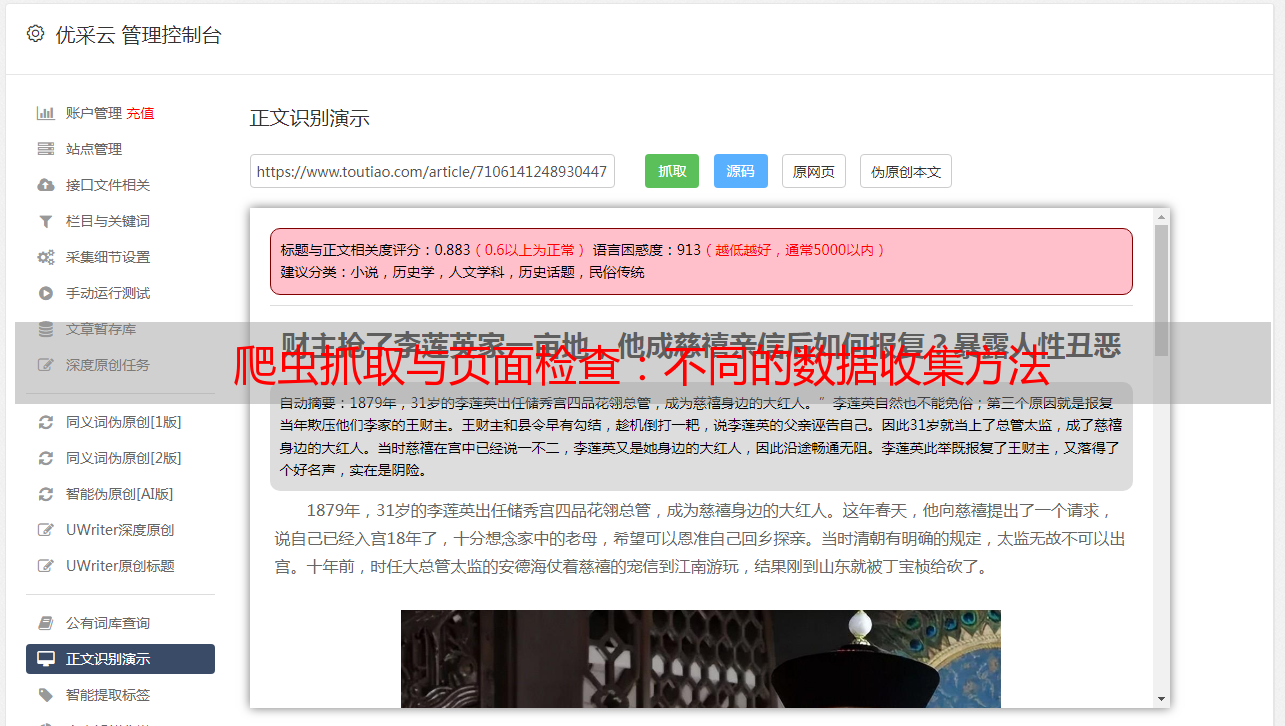
有些网站采用了分布式架构或者 CDN 等技术,使得不同地区或者不同用户访问到的网页内容可能不一样。这时候,在爬虫中需要选择正确的访问节点才能够获取到需要的页面内容。
六、浏览器差异
由于不同浏览器对 HTML 和 CSS 的解析方式有所差异,因此在某些情况下,通过爬虫获取到的页面内容与在浏览器中看到的内容也可能不一样。
七、网络延迟
在进行页面爬取时,还需要考虑网络延迟等问题。如果网络延迟过大,可能会导致请求超时或者获取到错误的页面内容。
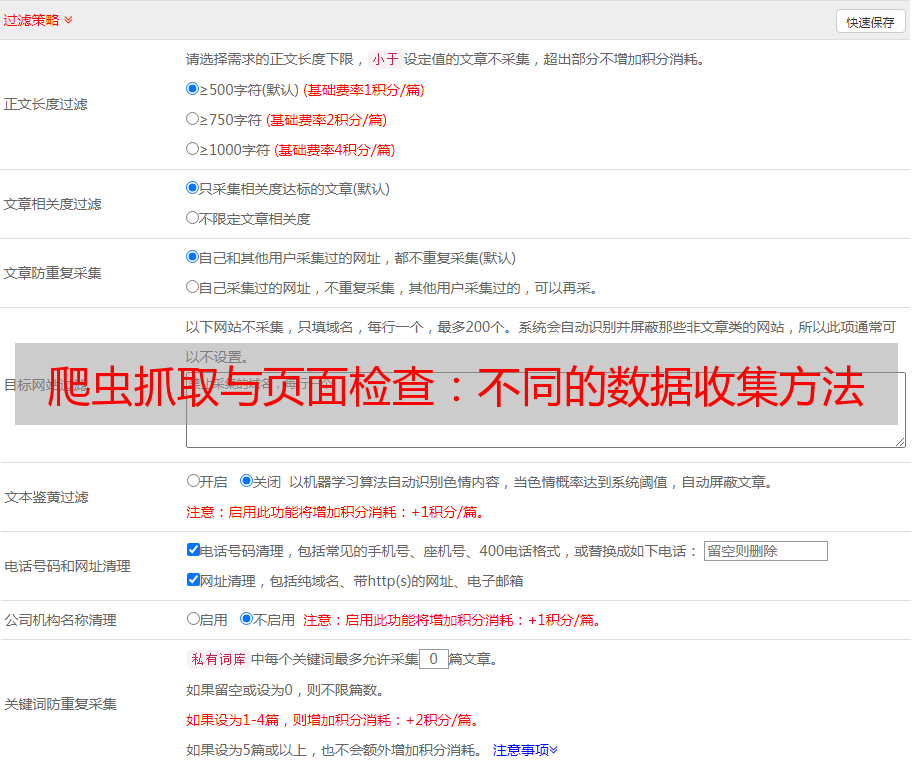
八、SEO优化
在进行网页设计和制作时,需要考虑 SEO 优化。为了提高搜索引擎优化效果,一些网站可能会采用隐藏关键字、嵌入大量链接等手段。这些手段可能会影响通过爬虫获取到的页面内容。
九、优采云
针对上述问题,可以使用优采云提供的服务来解决。优采云提供了强大的爬虫技术和反爬机制,可以帮助用户轻松地获取所需的页面内容。同时,优采云还提供了 SEO 优化等服务,帮助用户提高网站在搜索引擎中的排名。
十、总结
通过对爬虫页面检查和获取的不一样这一主题进行分析,我们可以发现,在进行页面爬取时,需要考虑多方面的因素。只有在充分了解这些因素的情况下,才能够顺利地获取到需要的页面内容。同时,借助优采云等服务,可以更加高效地进行页面爬取和 SEO 优化等工作。

