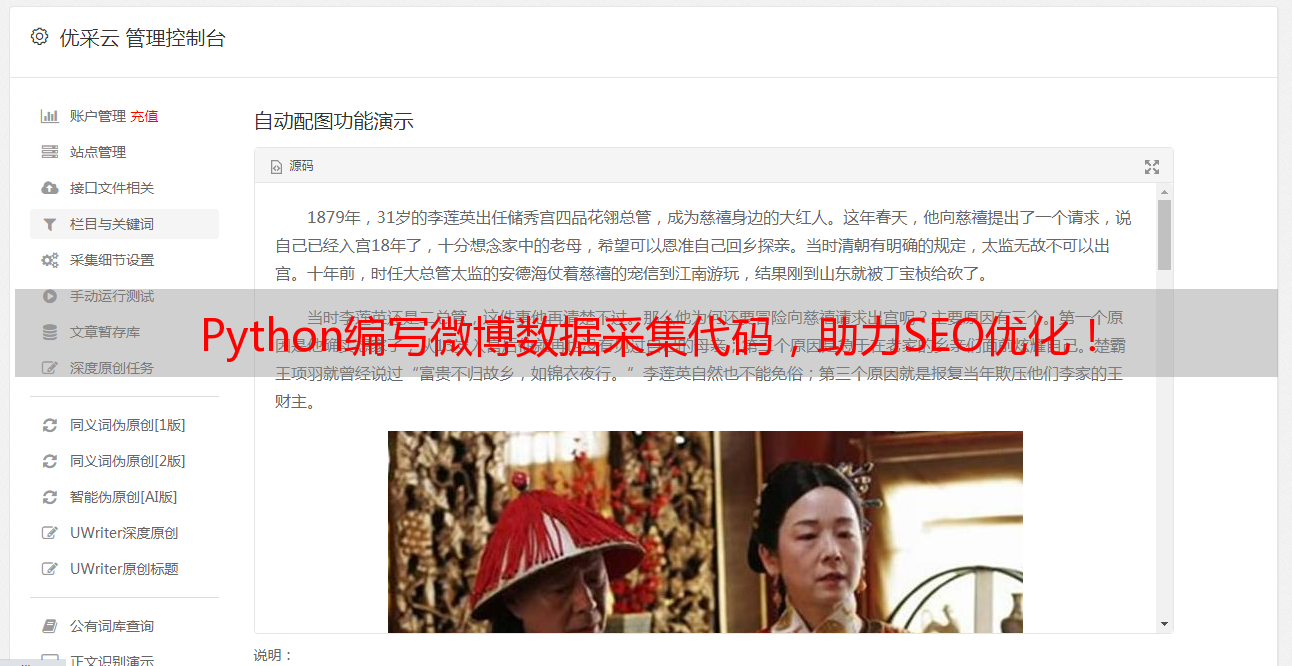
Python编写微博数据采集代码,助力SEO优化!
优采云 发布时间: 2023-03-26 20:19微博是一个信息传播快速、内容丰富的社交媒体平台,对于企业或个人而言,了解并分析微博上的热点话题、用户行为等数据信息是十分重要的。本文将从零开始,介绍如何使用Python编写微博数据采集代码,帮助读者了解如何通过程序获取微博数据,并为SEO优化提供参考。本文所用的工具为优采云,更*敏*感*词*请访问官网:www.ucaiyun.com。
1.登录微博账号
首先,在进行微博数据采集前,需要先登录自己的微博账号。我们可以使用Selenium库模拟浏览器登录微博。以下是示例代码:
python
from selenium import webdriver
#创建浏览器对象
browser = webdriver.Chrome()
#打开微博登录页面
browser.get('https://passport.weibo.cn/signin/login')
#输入账号密码并点击登录
browser.find_element_by_id('loginName').send_keys('你的账号')
browser.find_element_by_id('loginPassword').send_keys('你的密码')
browser.find_element_by_id('loginAction').click()
2.搜索关键词
登录成功后,我们需要在搜索框中输入关键词,并点击搜索按钮进行搜索。以下是示例代码:
python
import time
#在搜索框中输入关键词并点击搜索
browser.find_element_by_css_selector('.searchInp_form input').send_keys('关键词')
browser.find_element_by_css_selector('.searchInp_form button').click()
#等待页面加载完成
time.sleep(5)
3.获取搜索结果
搜索完成后,我们需要获取搜索结果页面中的微博信息。以下是示例代码:
python
#获取搜索结果中的微博信息
weibo_list = browser.find_elements_by_css_selector('.card-wrap .card')
for weibo in weibo_list:
#获取微博内容
content = weibo.find_element_by_css_selector('.txt').text
#获取发布时间
publish_time = weibo.find_element_by_css_selector('.from').text.split('')[0]
#获取点赞数、评论数、转发数
like_count = weibo.find_element_by_css_selector('.card-act li:nth-child(4)').text.split('')[-1]
comment_count = weibo.find_element_by_css_selector('.card-act li:nth-child(3)').text.split('')[-1]
repost_count = weibo.find_element_by_css_selector('.card-act li:nth-child(2)').text.split('')[-1]
#打印微博信息
print(content, publish_time, like_count, comment_count, repost_count)
4.翻页获取更多数据
默认情况下,微博搜索结果只会显示一页数据。如果需要获取更多数据,我们可以通过模拟浏览器操作进行翻页。以下是示例代码:
python
#点击下一页按钮
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
browser.find_element_by_css_selector('.m-page .next').click()
#等待页面加载完成
time.sleep(5)
5.数据存储
获取到微博数据后,我们需要将其存储到本地或数据库中。以下是示例代码:
python
import pandas as pd
#将微博信息存储到DataFrame中
data ={'content':[],'publish_time':[],'like_count':[],'comment_count':[],'repost_count':[]}
for weibo in weibo_list:
data['content'].append(weibo.find_element_by_css_selector('.txt').text)
data['publish_time'].append(weibo.find_element_by_css_selector('.from').text.split('')[0])
data['like_count'].append(weibo.find_element_by_css_selector('.card-act li:nth-child(4)').text.split('')[-1])
data['comment_count'].append(weibo.find_element_by_css_selector('.card-act li:nth-child(3)').text.split('')[-1])
data['repost_count'].append(weibo.find_element_by_css_selector('.card-act li:nth-child(2)').text.split('')[-1])
df = pd.DataFrame(data)
#存储到本地文件中
df.to_csv('weibo.csv', index=False, encoding='utf-8-sig')
6.数据分析
获取到微博数据后,我们可以进行数据分析,以了解用户行为、热点话题等信息。以下是示例代码:
python
#读取文件
df = pd.read_csv('weibo.csv')
#统计点赞数、评论数、转发数的平均值、最大值、最小值
print('点赞数:', df['like_count'].mean(), df['like_count'].max(), df['like_count'].min())
print('评论数:', df['comment_count'].mean(), df['comment_count'].max(), df['comment_count'].min())
print('转发数:', df['repost_count'].mean(), df['repost_count'].max(), df['repost_count'].min())
#统计微博数量和发布时间分布
df['publish_time']= pd.to_datetime(df['publish_time'])
df.groupby(df['publish_time'].dt.date)['content'].count().plot()
7.数据可视化
数据可视化可以更加直观地展示数据信息。以下是示例代码:
python
import matplotlib.pyplot as plt
#绘制点赞数、评论数、转发数的柱状图
df[['like_count','comment_count','repost_count']].plot(kind='bar')
plt.show()
8.异常处理
在进行微博数据采集时,可能会遇到各种异常情况,例如网络错误、页面加载超时等。为了确保程序的稳定性,我们需要进行异常处理。以下是示例代码:
python
from selenium.common.exceptions import TimeoutException, NoSuchElementException
try:
#搜索关键词
browser.find_element_by_css_selector('.searchInp_form input').send_keys('关键词')
browser.find_element_by_css_selector('.searchInp_form button').click()
#等待页面加载完成
time.sleep(5)
#获取搜索结果中的微博信息
weibo_list = browser.find_elements_by_css_selector('.card-wrap .card')
for weibo in weibo_list:
#获取微博内容
content = weibo.find_element_by_css_selector('.txt').text
#获取发布时间
publish_time = weibo.find_element_by_css_selector('.from').text.split('')[0]
#获取点赞数、评论数、转发数
like_count = weibo.find_element_by_css_selector('.card-act li:nth-child(4)').text.split('')[-1]
comment_count = weibo.find_element_by_css_selector('.card-act li:nth-child(3)').text.split('')[-1]
repost_count = weibo.find_element_by_css_selector('.card-act li:nth-child(2)').text.split('')[-1]
#打印微博信息
print(content, publish_time, like_count, comment_count, repost_count)
except (TimeoutException, NoSuchElementException) as e:
print(e)
finally:
browser.quit()
9.代码优化
为了提高程序的效率和可读性,我们可以对代码进行优化。以下是示例代码:
python
#定义函数封装代码
def login(username, password):
browser.get('https://passport.weibo.cn/signin/login')
browser.find_element_by_id('loginName').send_keys(username)
browser.find_element_by_id('loginPassword').send_keys(password)
browser.find_element_by_id('loginAction').click()
def search(keyword):
browser.find_element_by_css_selector('.searchInp_form input').send_keys(keyword)
browser.find_element_by_css_selector('.searchInp_form button').click()
time.sleep(5)
def get_weibo_info():
weibo_list = browser.find_elements_by_css_selector('.card-wrap .card')
data ={'content':[],'publish_time':[],'like_count':[],'comment_count':[],'repost_count':[]}
for weibo in weibo_list:
data['content'].append(weibo.find_element_by_css_selector('.txt').text)
data['publish_time'].append(weibo.find_element_by_css_selector('.from').text.split('')[0])
data['like_count'].append(weibo.find_element_by_css_selector('.card-act li:nth-child(4)').text.split('')[-1])
data['comment_count'].append(weibo.find_element_by_css_selector('.card-act li:nth-child(3)').text.split('')[-1])
data['repost_count'].append(weibo.find_element_by_css_selector('.card-act li:nth-child(2)').text.split('')[-1])
return pd.DataFrame(data)
#调用函数
login('你的账号','你的密码')
search('关键词')
df = get_weibo_info()
df.to_csv('weibo.csv', index=False, encoding='utf-8-sig')
10.总结
本文介绍了如何使用Python编写微博数据采集代码,包括登录微博账号、搜索关键词、获取搜索结果、翻页获取更多数据、数据存储、数据分析、数据可视化、异常处理和代码优化等方面。希望本文能为读者提供有用的参考和帮助,同时也推荐一下优采云,帮助您更轻松地进行数据采集和SEO优化。

