自动抓取网页数据,解放大数据时代!
优采云 发布时间: 2023-03-26 14:17在大数据时代,数据是最重要的资源之一。而获取数据的方式也越来越多样化。其中,浏览器自动抓取是一种非常有效的方式之一。下面,就让我们来详细了解一下浏览器自动抓取指定网页数据。
1.什么是浏览器自动抓取?
浏览器自动抓取是指利用程序模拟人工操作浏览器,从而实现对网页数据的获取。它可以模拟各种操作,比如点击、输入等等,从而实现对目标网站的信息采集。
2.浏览器自动抓取的优势
相比于其他方式,浏览器自动抓取有以下几个优点:
1)不需要API:使用API需要申请、审核等繁琐流程,而浏览器自动抓取可以直接通过程序访问网站进行采集。
2)适应性强:不同的采集需求可以通过编写不同的脚本来实现。
3)效率高:使用多线程技术可以提高采集效率。
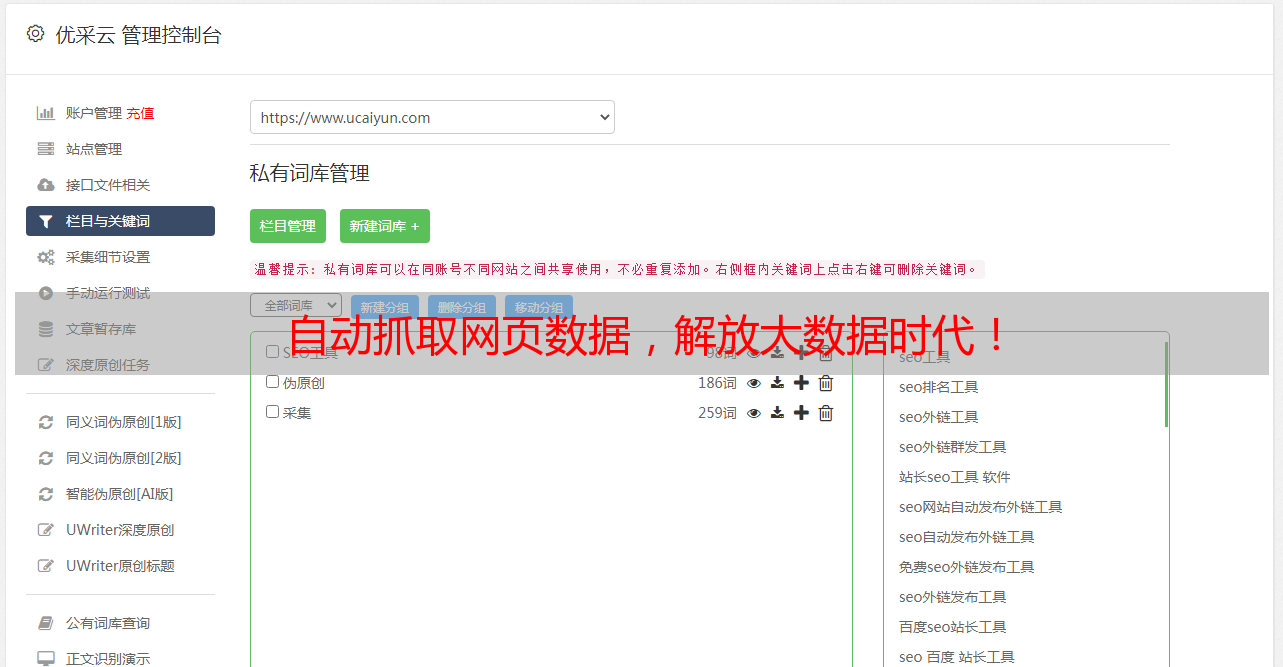
4)稳定性高:因为采用了模拟人工操作的方式,所以稳定性较高。
3.如何进行浏览器自动抓取?
浏览器自动抓取可以使用Python、Java、Node.js等多种编程语言实现。这里以Python为例进行介绍。
首先,需要安装selenium和beautifulsoup4两个库。
pip install selenium
pip install beautifulsoup4
然后,需要下载对应浏览器的驱动,比如Chrome驱动。下载地址:https://sites.google.com/a/chromium.org/chromedriver/downloads。
接下来,就可以写代码进行自动抓取了。以下是一个简单的示例:
python
from selenium import webdriver
from bs4 import BeautifulSoup
#创建一个Chrome浏览器对象
browser = webdriver.Chrome()
#打开目标网站
browser.get("https://www.example.com")
#获取网页源代码并解析
soup = BeautifulSoup(browser.page_source,"html.parser")
#获取目标元素并处理数据
...
#关闭浏览器窗口
browser.quit()
通过以上代码,我们可以打开目标网站,并获取其中的数据进行处理。
4.浏览器自动抓取的应用场景
浏览器自动抓取可以应用于各种场景,比如:
1)数据采集:爬取各种网站的数据。
2)SEO优化:通过对竞争对手网站进行分析,找到关键词和链接等信息。
3)价格监控:监控竞争对手的价格变化等信息。
4)内容聚合:将多个网站的内容聚合到一个平台上。
5)自动化测试:模拟用户操作,进行测试。
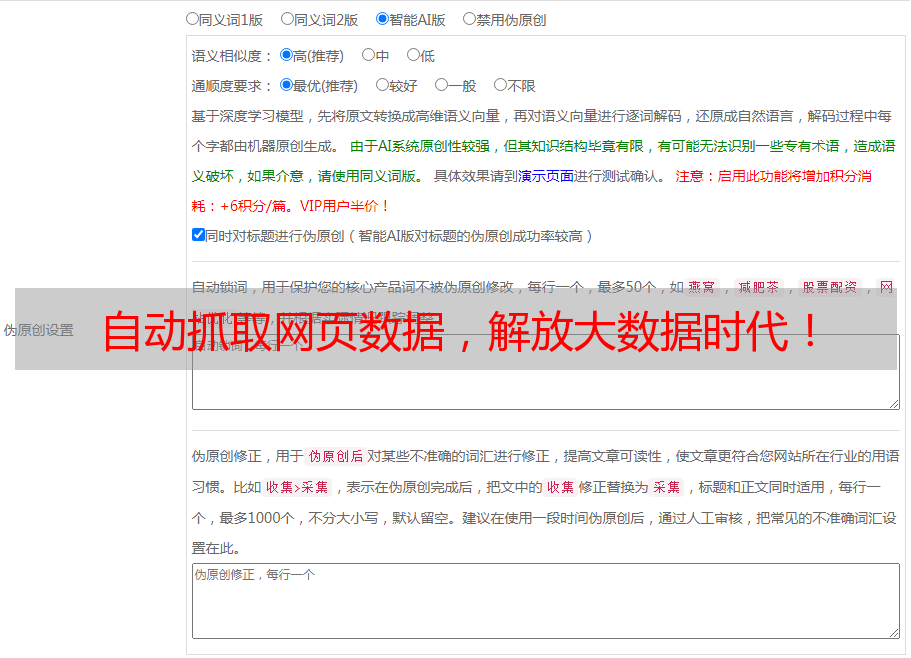
5.注意事项
在进行浏览器自动抓取时,需要注意以下几点:
1)遵守网站的规定:不要采集有关隐私、版权等方面的信息。
2)反爬虫机制:有些网站会设置反爬虫机制,需要注意处理。
3)频率控制:不要频繁访问同一个网站,以免被封IP。
4)数据存储:需要将采集到的数据进行存储和备份。
6.总结
浏览器自动抓取是一种非常有效的获取数据的方式。通过编写程序模拟人工操作浏览器,可以实现对目标网站的信息采集。在使用过程中,需要注意遵守相关规定,并做好反爬虫机制、频率控制、数据存储等方面的处理。优采云提供了一系列数据采集解决方案,包括浏览器自动抓取、API接口等多种方式,可根据需求选择。同时,优采云还提供SEO优化服务,帮助企业提升网站流量和排名。更多详情,请访问www.ucaiyun.com。

