掌握网站源码,搭建爬虫,实现伪原创,分享不是问题!
优采云 发布时间: 2023-03-25 03:10众所周知,网站源码是网站的核心,也是网站优化的重要手段之一。而如何在保证网站源码完整性的情况下进行伪原创,是很多站长和SEO从业者关注的焦点。本文将以“网站源码爬虫伪原创”为主题,深入分析这一话题,并提供实用方法。
一、了解网站源码
网站源码是指网页文件的代码,可以通过浏览器右键“查看页面源代码”或者F12开发者工具查看。通常包括HTML、CSS、JavaScript等内容。学会阅读、理解和修改网站源码,对于进行SEO优化和伪原创都至关重要。
二、掌握爬虫技术
爬虫技术是指模拟人类浏览器行为,通过程序抓取互联网上的数据。爬虫可以获取到网站源码中的各种内容,并进行筛选和处理。
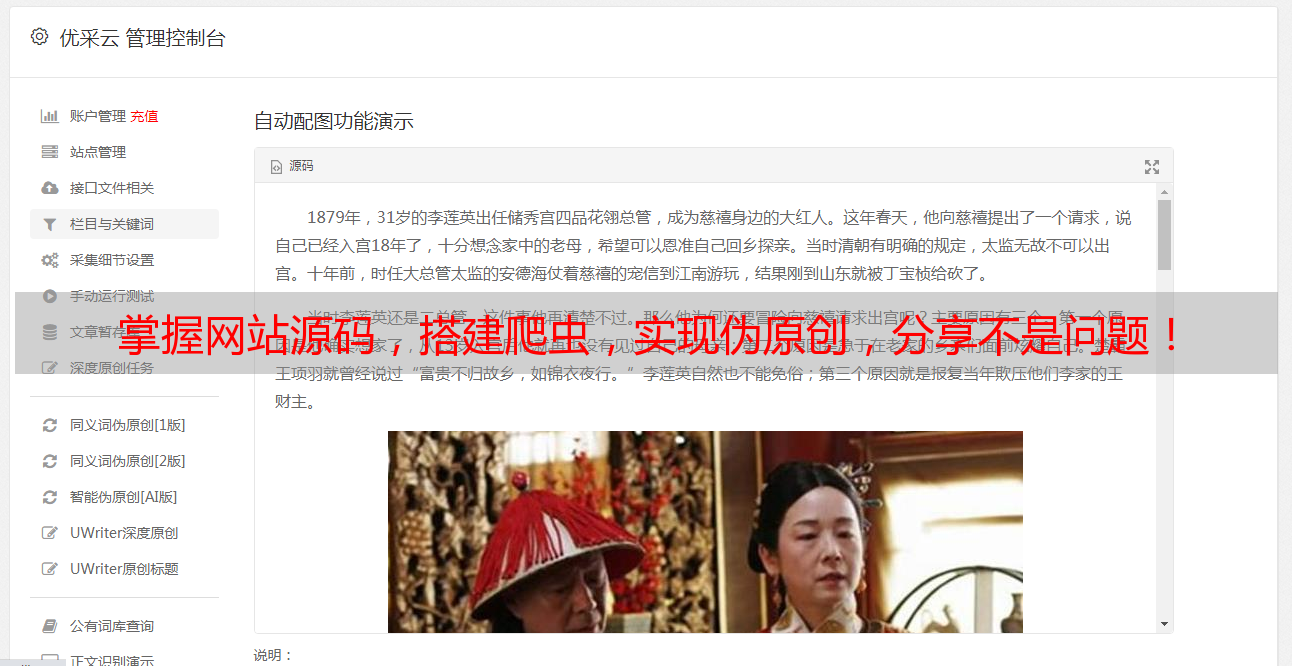
三、使用正则表达式
正则表达式可以用来匹配和替换文本中的特定内容。对于进行伪原创,我们可以通过正则表达式将关键词进行替换或者随机插入,从而达到改变文章内容的目的。
四、应用自然语言处理技术
自然语言处理技术可以对文本进行分析和处理,包括分词、词性标注、关键词提取等。通过这些技术,我们可以对文章进行伪原创,保证文章的可读性和语法正确性。
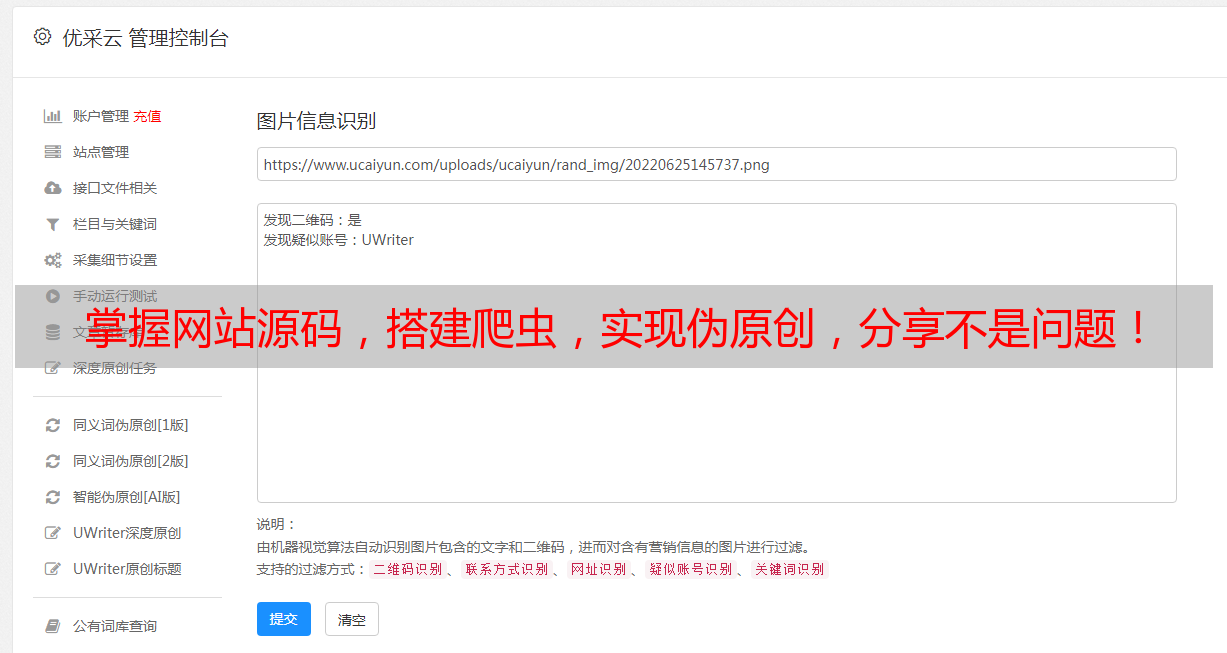
五、使用工具辅助
现在市面上有很多伪原创工具,包括手动修改、在线工具和软件等。这些工具可以大大提高效率,同时也需要注意不要过度依赖,保证文章质量。
六、注意SEO优化
在进行伪原创的同时,也需要注意SEO优化。合理地使用标题、关键词和描述等元素,并保证网站结构良好和页面速度快速。
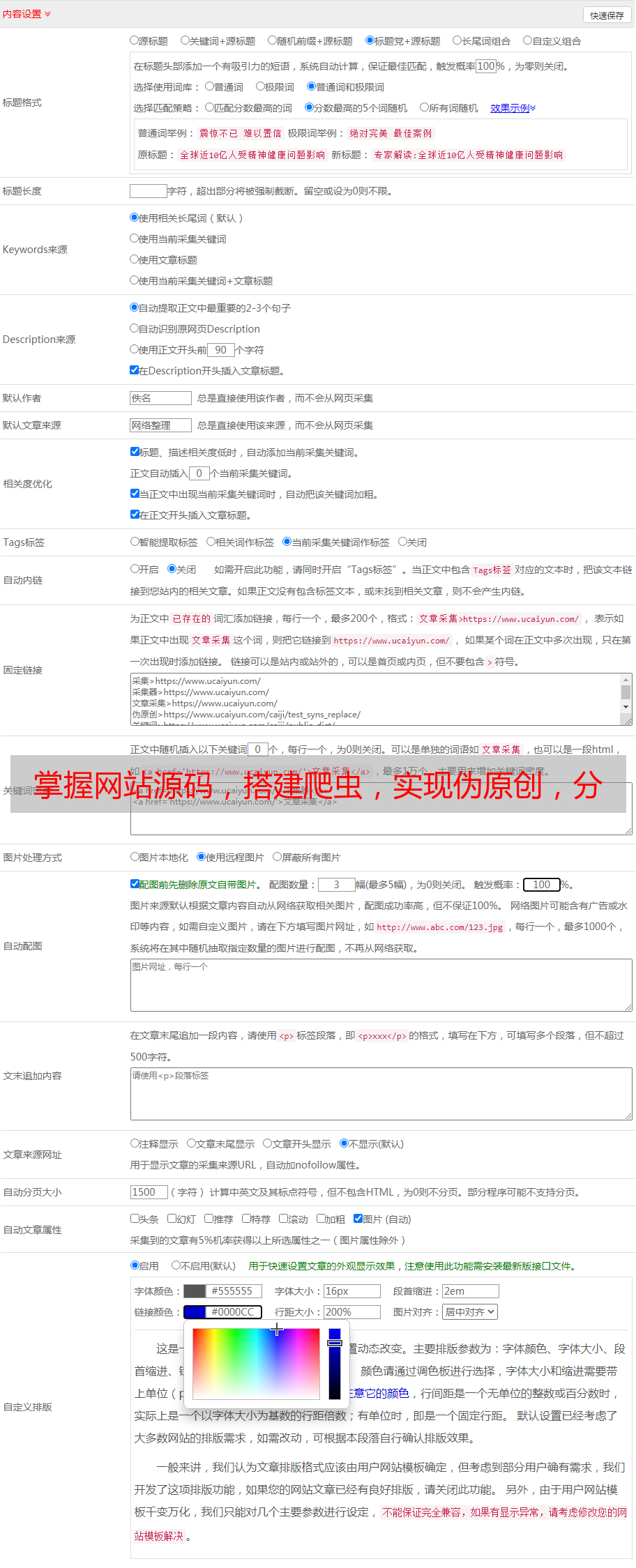
七、案例分析
以下是一个实际案例,通过爬虫获取网站源码并进行伪原创:
python
import requests
from bs4 import BeautifulSoup
url ='https://www.example.com'
headers ={'User-Agent':'Mozilla/5.0(Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text,'html.parser')
content = soup.find('div', class_='article-content').get_text()
#进行伪原创操作
八、总结
通过对网站源码、爬虫技术、正则表达式、自然语言处理技术和工具的分析,我们可以实现伪原创并保证文章质量。同时也需要注意SEO优化和合规问题,不断提升自己的技能和水平。
优采云是一家专业的SEO优化服务提供商,致力于为企业提供高效、可靠的SEO优化方案。如果您需要进行网站优化或者伪原创,可以联系我们了解更多信息。网址:www.ucaiyun.com

