每日头条新闻自动抓取,让你轻松获取最新资讯!
优采云 发布时间: 2023-03-24 22:15在信息化的今天,每个人都需要时刻关注最新的资讯,而头条新闻则是最能代表时事的媒体。但是每天手动去查看不同的新闻网站,对于我们来说无疑是一件非常浪费时间的事情。那么有没有一种方法可以让我们自动获取到每日头条新闻呢?当然有,在这里我向大家介绍一种自动化的方式——利用Python编写程序每日定时抓取头条新闻。
1.什么是自动抓取?
自动抓取(Web Scraping)指的是通过编写代码,模拟用户行为,从网页中提取所需信息的技术。通过自动抓取可以快速、准确地获取网站上的数据,并将其转化为结构化数据格式。
2. Python爬虫
Python是一门非常流行的编程语言,它有着丰富的第三方库和工具,其中就包括了用于网络爬虫的库。比如Requests、BeautifulSoup、Scrapy等。在这里,我们使用Requests和BeautifulSoup两个库来实现爬虫。
3.代码实现
下面是一个简单的Python代码示例,它可以从今日头条网站上获取今日头条新闻的标题和链接:
python
import requests
from bs4 import BeautifulSoup
url ='https://www.toutiao.com/ch/news_tech/'
res = requests.get(url)
soup = BeautifulSoup(res.text,'html.parser')
news_list = soup.find_all('a', attrs={'class':'link title'})
for news in news_list:
title = news.get_text()
link = news.get('href')
print(title, link)
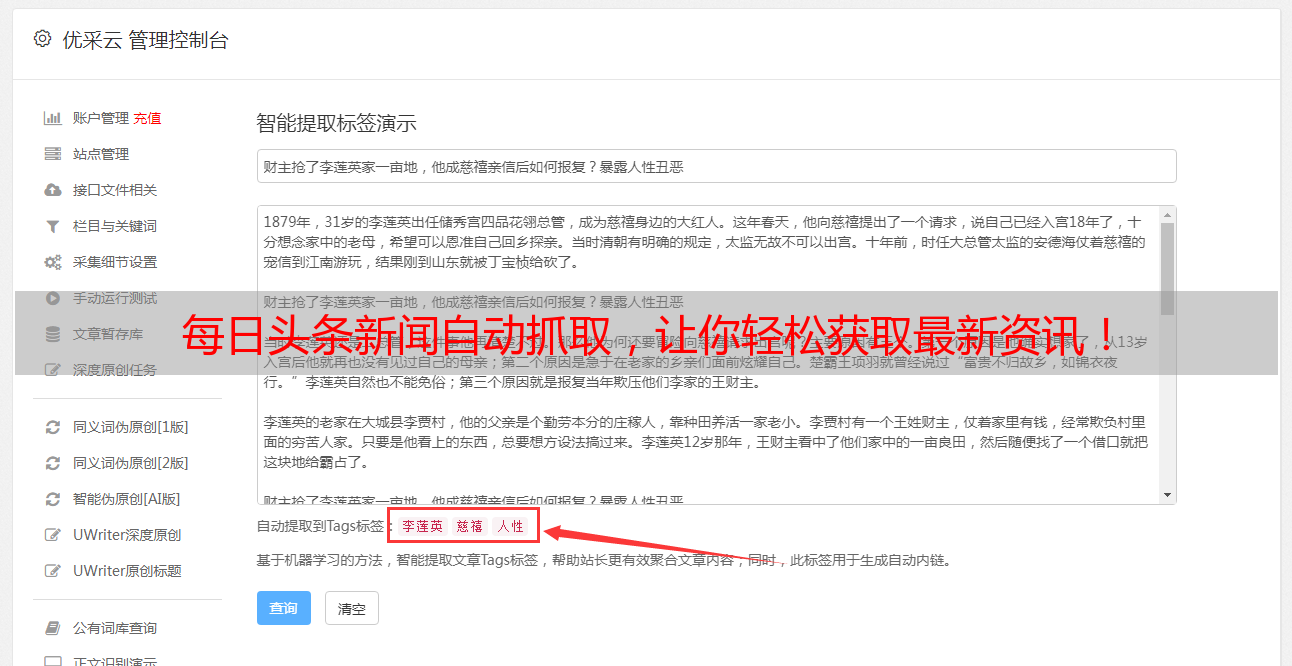
在这个示例中,我们首先使用requests库发送一个GET请求,获取到今日头条科技新闻的页面。然后使用BeautifulSoup库解析页面内容,获取到所有新闻标题和链接的标签,并将其打印出来。
4.定时任务
通过上面的代码,我们已经可以获取到今日头条科技新闻的标题和链接了。但是每天手动运行一次这个程序还是非常麻烦的。所以我们需要将它变成一个定时任务,让它每天自动运行。
在Python中,可以使用APScheduler这个库来实现定时任务。下面是一个简单的示例:
python
from apscheduler.schedulers.blocking import BlockingScheduler
def job():
#在这里写上爬虫代码
scheduler = BlockingScheduler()
scheduler.add_job(job,'interval', days=1)
scheduler.start()
在这个示例中,我们定义了一个job函数,用于执行爬虫代码;然后使用BlockingScheduler创建了一个定时任务调度器,并将job函数添加到调度器中;最后设置了定时任务的时间间隔为1天,并启动了调度器。
5.优化爬虫
在编写爬虫代码的过程中,我们需要注意以下几点:
-遵守Robots协议,不要过度访问网站。
-设置合适的请求头,模拟用户行为。
-处理异常情况,比如网络连接超时、页面解析失败等。
-使用代理IP,防止被网站屏蔽IP。
6. SEO优化
如果你是一个自媒体人,想要将自己的文章推广出去,那么SEO优化是必不可少的。下面是一些SEO优化的建议:
-标题:要有吸引力、简洁明了,并包含关键词。
-描述:要简短、精准,并包含关键词。
-关键词:要选择合适的关键词,并在文章中多次出现。
-内容:要充实详尽、生动具体,并包含图片和视频。
7.优采云
如果你想要更好地进行自媒体运营和SEO优化,可以考虑使用优采云这个工具。它可以帮助你快速写出高质量的文章,并进行关键词优化、排版美化等操作。同时还提供了多种营销工具和数据分析功能,帮助你更好地推广自己的内容。如果你想要了解更多信息,可以访问官网:www.ucaiyun.com。
8.总结
通过Python编写程序每日定时抓取每日头条新闻,可以让我们快速获取最新的资讯,并且不需要花费太多时间和精力。同时,我们还可以通过SEO优化和优采云等工具,将自己的文章推广出去,吸引更多的读者。希望这篇文章对大家有所帮助,谢谢阅读!

