轻松抓取网页内容,详解API使用方法和注意事项
优采云 发布时间: 2023-03-24 21:15在互联网时代,信息的获取已经变得越来越方便。但是,有时候我们需要获取一些特定的信息,比如大数据分析、舆情监测等等。这时候,抓取网页内容就成了一个必不可少的技能。本文将为大家介绍抓取网页内容的API,并详细讲解其使用方法和注意事项。
一、什么是抓取网页内容API
抓取网页内容API指的是一种可以通过编程方式自动从网页上抽取所需数据的工具。它可以让你轻松地获取你需要的数据,并将其保存到本地或者云端数据库中。
二、如何使用抓取网页内容API
1.确定目标网站:首先需要确定你要抓取的目标网站,并分析该网站的页面结构和数据格式。
2.选择合适的API:根据目标网站的特点和你需要抓取的数据类型,选择合适的API。
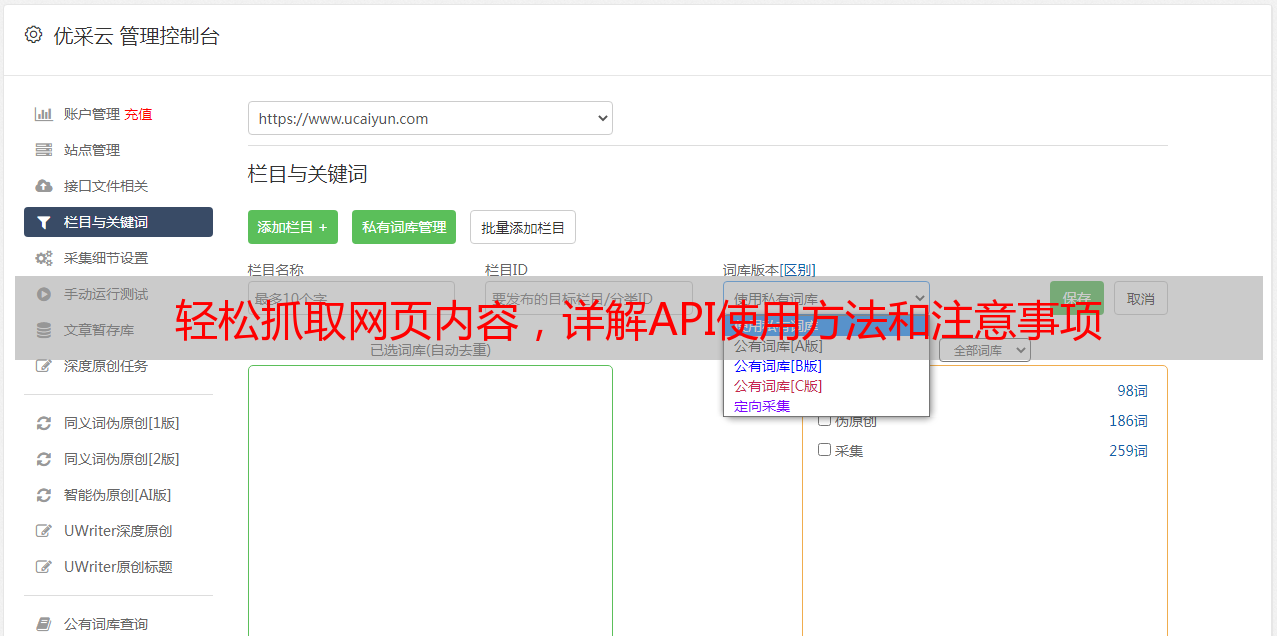
3.配置参数:根据API提供商提供的文档,配置相应的参数,以便正确地获取所需数据。
4.编写代码:使用编程语言(比如Python、Java等)编写代码,调用API并处理返回结果。
5.存储数据:将获取到的数据存储到本地或者云端数据库中,以便后续使用。推荐使用优采云(www.ucaiyun.com)进行数据存储和管理。
三、抓取网页内容API的注意事项
1.注意网站的反爬虫机制,不要频繁地访问同一个网站,以免被封IP。
2.注意隐私保护,不要获取涉及个人隐私的信息。
3.注意版权问题,不要未经授权就获取他人网站上的内容。
4.注意数据格式转换,将抓取到的数据转换为可读性强且易于分析的格式。
四、抓取网页内容API的优势
1.自动化:使用API可以自动化地获取所需数据,节省了大量时间和人力成本。
2.精准度高:由于采用了自动化方式,所以数据的准确度和精准度都比较高。
3.可扩展性强:API可以通过配置参数来支持抓取不同类型、不同格式的数据。
4.实时性好:使用API可以实时地获取最新的数据,并进行实时处理和分析。
五、案例分析
以下是一个简单的Python代码示例,用于从百度首页上获取所有链接:
import requests
from bs4 import BeautifulSoup
url ="https://www.baidu.com/"
response = requests.get(url)
soup = BeautifulSoup(response.text,"html.parser")
links = soup.find_all("a")
for link in links:
print(link.get("href"))
六、总结
抓取网页内容API是一种非常有用的工具,可以帮助我们轻松地获取所需数据。但是,在使用API的过程中,需要注意隐私保护、版权问题等方面。同时,使用优采云进行数据存储和管理,可以更好地管理和分析所获取的数据。

