直接下载网页,网络爬虫技术助力抓取实现
优采云 发布时间: 2023-03-24 10:25一、概述
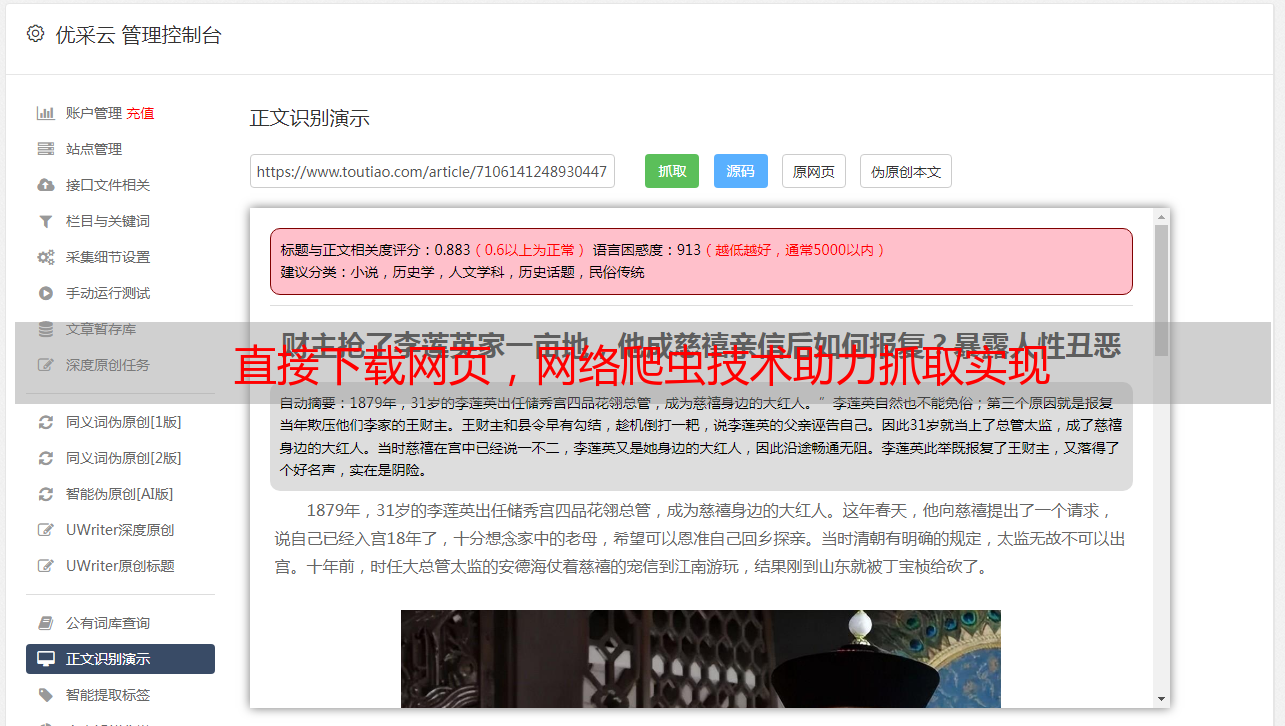
在网络爬虫技术的支持下,直接抓取网页的下载已经成为了获取信息的主要方式之一。它可以实现自动化、批量化地下载网页,并提取其中的信息。不过,使用这种方式也需要注意一些问题,比如版权问题、隐私问题等。
二、版权问题
直接抓取网页可能会侵犯版权。如果我们下载了别人的原创内容,并在未经授权的情况下进行传播或商业利用,就会涉及版权问题。因此,在使用爬虫工具时,我们需要遵守相关法律法规和道德规范。
三、隐私问题
直接抓取网页也可能会涉及到隐私问题。如果我们下载了个人信息或敏感数据,并进行传播或商业利用,就会侵犯他人隐私。因此,在使用爬虫工具时,我们需要严格遵守相关法律法规和道德规范。
四、反爬虫机制
为了防止爬虫工具的滥用,许多网站都设置了反爬虫机制。比如,可以通过验证码、限制IP、限制访问频率等方式来防止爬虫工具的使用。因此,在使用爬虫工具时,我们需要注意这些反爬虫机制,并采取相应的应对措施。
五、数据清洗
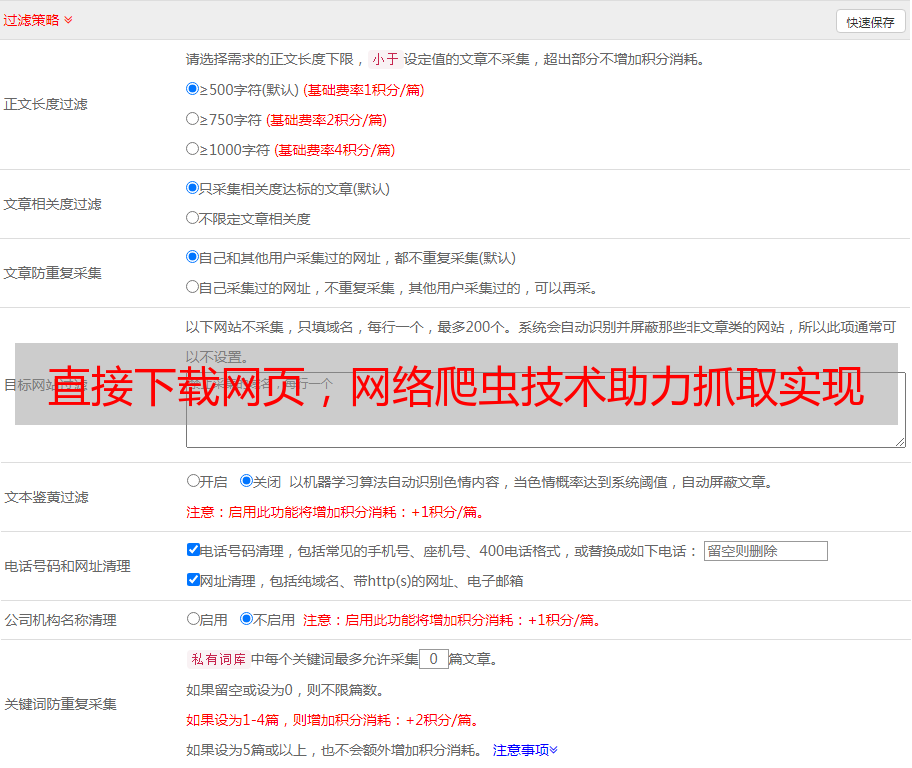
直接抓取网页得到的数据往往是杂乱无章的,需要进行数据清洗和处理。比如,需要去除HTML标签、提取关键词、过滤无用信息等。同时,还需要注意数据的准确性和有效性。
六、性能优化
直接抓取网页可能会对网站造成一定的负担,影响用户体验和SEO效果。因此,在使用爬虫工具时,我们需要采取一些性能优化措施,比如设置访问间隔、选择合适的下载方式等。
七、风险管理
直接抓取网页也存在着一定的风险。比如,我们可能会下载到恶意代码或病毒程序,导致计算机系统受到攻击。因此,在使用爬虫工具时,我们需要采取一些风险管理措施,比如安装杀毒软件、备份数据等。
八、结语
直接抓取网页的下载是一种高效便捷的方式,但同时也存在着一些问题和风险。我们需要遵守相关法律法规和道德规范,同时采取相应的措施来保障自己和他人的利益。优采云提供了优质的SEO优化服务,欢迎访问www.ucaiyun.com了解更多信息。

