解决Java URL抓取数据未更新的问题
优采云 发布时间: 2023-03-22 22:24在现今信息时代,我们对于最新的信息、数据、资讯等需求越来越强烈,而网络抓取技术作为一种重要的方式,被广泛应用于各个领域。然而,在使用Java URL抓取页面数据时,却会遇到“数据没有更新”的情况,这该怎么办呢?本文将从多个方面逐步分析讨论解决方案。
1.了解URL缓存机制
网络上的资源不可能一直是动态变化的,为了减少网络带宽的消耗和提高用户体验,浏览器和服务器都会采用缓存机制。即在一定时间内不重新请求资源,直接使用本地缓存中的资源。因此,在使用Java URL获取页面数据时,如果URL被缓存在本地或服务器端,则可能导致数据没有更新。
2.修改URL
如果需要获取最新的页面数据,可以考虑修改URL地址。比如在URL后面添加一个时间戳参数或随机数参数,强制刷新页面,避免缓存的影响。示例代码如下:
import java.net.*;
import java.io.*;
import java.util.Date;
public class URLDemo {
public static void main(String[] args) throws Exception {
URL url = new URL("https://www.example.com/page.html?time="+ new Date().getTime());
HttpURLConnection conn =(HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
BufferedReader reader = new BufferedReader(new InputStreamReader(conn.getInputStream()));
String line;
while ((line = reader.readLine())!= null){
System.out.println(line);
}
reader.close();
}
}
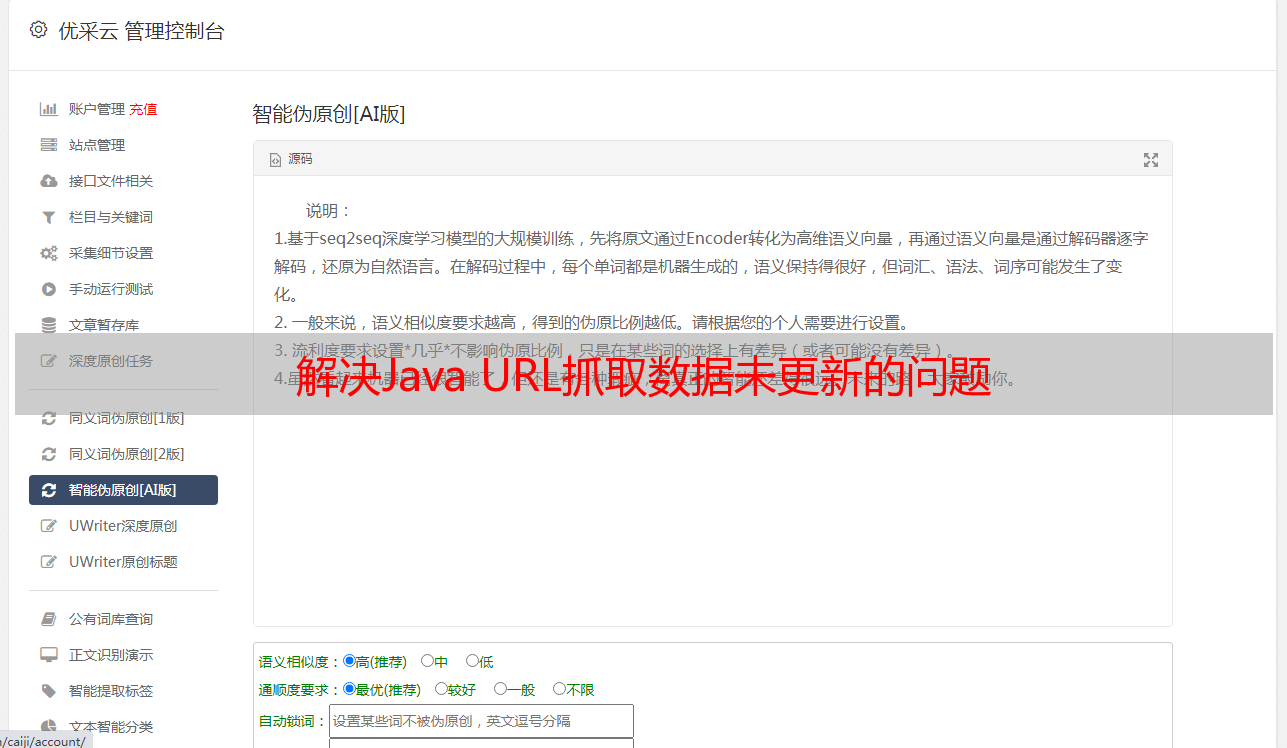
3.使用URLConnection设置缓存控制
URLConnection类提供了设置缓存控制的方法。可以通过设置setUseCaches(false)和setRequestProperty("Cache-Control","no-cache")来禁用缓存。示例代码如下:
import java.net.*;
import java.io.*;
public class URLDemo {
public static void main(String[] args) throws Exception {
URL url = new URL("https://www.example.com/page.html");
HttpURLConnection conn =(HttpURLConnection) url.openConnection();
conn.setUseCaches(false);
conn.setRequestProperty("Cache-Control","no-cache");
conn.setRequestMethod("GET");
BufferedReader reader = new BufferedReader(new InputStreamReader(conn.getInputStream()));
String line;
while ((line = reader.readLine())!= null){
System.out.println(line);
}
reader.close();
}
}
4.使用Jsoup抓取页面数据
除了Java URL之外,还可以使用Jsoup库来抓取页面数据。Jsoup是一款基于Java语言开发的HTML解析器和处理器库,可以方便地从网页中提取出所需数据。示例代码如下:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class JsoupDemo {
public static void main(String[] args) throws Exception {
Document doc = Jsoup.connect("https://www.example.com/page.html").get();
System.out.println(doc.html());
}
}
5.使用Selenium模拟浏览器操作
Selenium是一个自动化测试工具,也可以用来模拟浏览器操作,并获取网页中的数据。相比于Java URL和Jsoup库而言,Selenium更加灵活、强大。示例代码如下:
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
public class SeleniumDemo {
public static void main(String[] args) throws Exception {
System.setProperty("webdriver.chrome.driver","/path/to/chromedriver");
WebDriver driver = new ChromeDriver();
driver.get("https://www.example.com/page.html");
System.out.println(driver.getPageSource());
}
}
6.检查网络连接状态
当然,在网络连接不稳定或者出现故障时,也有可能导致Java URL抓取的页面数据没有更新。此时需要检查网络连接状态,并进行相应的处理。
7.检查网站是否发生更改
有些网站会在更新内容后修改URL地址或者更改HTML结构等信息。因此,在Java URL抓取页面数据时可能需要检查网站是否发生更改,并根据实际情况进行相应调整。
8.联系网站管理员
如果以上方法都无法解决问题,那么就需要联系网站管理员寻求帮助了。毕竟有些网站可能采用了特殊的技术手段来限制爬虫程序的行为。
9.总结
综上所述,在使用Java URL抓取页面数据时遇到“数据没有更新”的情况,并不是绝对无法解决。可以从多个方面入手进行调整和优化,并选择合适的工具进行操作。
10.优采云SEO优化平台
如果你想进一步深入学习SEO优化、提升网站流量和排名等知识,请访问优采云SEO优化平台(www.ucaiyun.com)。优采云为您提供全方位、一站式SEO解决方案!

