网络爬虫领域全面解析:服务器采集技术详解
优采云 发布时间: 2023-03-20 03:18服务器采集技术一直是网络爬虫领域中的热门话题,其在数据挖掘、信息搜集等方面发挥着重要作用。本文将从原理、实现、应用等多个方面全面解析服务器采集技术,帮助读者更好地理解和运用这一技术。
一、什么是服务器采集
服务器采集是指通过模拟浏览器行为,在服务器端获取网页信息的技术。与传统的客户端采集不同,服务器采集可以避免反爬虫策略对爬虫的限制,同时也可以减少网络传输数据量,提高采集效率。在数据挖掘、信息搜集等领域有广泛应用。
二、服务器采集的原理
1.模拟浏览器行为
在服务器端模拟浏览器行为,包括发送请求、接收响应、解析网页等操作。通过模拟浏览器行为,可以避免反爬虫策略对爬虫的限制。
2. User-Agent伪装
User-Agent是HTTP请求头中的一个字段,用于标识客户端类型和版本号。通过伪装User-Agent,可以让服务器认为爬虫是一个普通的浏览器用户。
3. IP代理
使用IP代理可以隐藏爬虫的真实IP地址,防止被封禁。常见的IP代理有付费代理和免费代理两种。
4. Cookie管理
Cookie是HTTP请求头中的一个字段,用于标识用户身份和状态。通过管理Cookie,可以维护用户登录状态和保持会话。
5.验证码识别
一些网站为了防止恶意爬虫攻击,会设置验证码。通过验证码识别技术,可以自动化地完成验证码识别,并绕过这一障碍。
三、服务器采集的实现
1. Python语言
Python语言具有简洁易学、开源免费等优点,在网络爬虫领域得到广泛应用。常见的Python库有Requests、BeautifulSoup、Selenium等。
2. Java语言
Java语言具有跨平台性和强大的多线程支持,在企业级应用中得到广泛应用。常见的Java框架有HttpClient、Jsoup、WebDriver等。
3. PHP语言
PHP语言具有简单易学、开源免费等优点,在Web开发领域得到广泛应用。常见的PHP库有cURL、GuzzleHttp等。
四、服务器采集的注意事项
1.遵守Robots协议
Robots协议是指网站所有者声明哪些页面可以被搜索引擎抓取,哪些页面不能被抓取。在进行服务器采集时需要遵守Robots协议。
2.合法合规使用
在进行服务器采集时需要遵守相关法律法规和道德规范,并且不得侵犯他人权益。
3.防止被封禁
在进行服务器采集时需要注意不要频繁地请求同一个页面或同一个IP地址,以防被网站封禁。
五、服务器采集的应用场景
1.数据挖掘与分析
通过对网页内容进行分析和处理,获取其中蕴含的数据信息,并将其转化为结构化数据进行分析和挖掘。
2.网络安全监控
通过对网络流量进行监控和分析,及时发现并防范网络安全威胁。
3.营销推广优化
通过获取竞争对手信息或用户需求信息,在营销推广活动中寻求突破口,并对营销策略进行优化调整。
六、优采云平台介绍
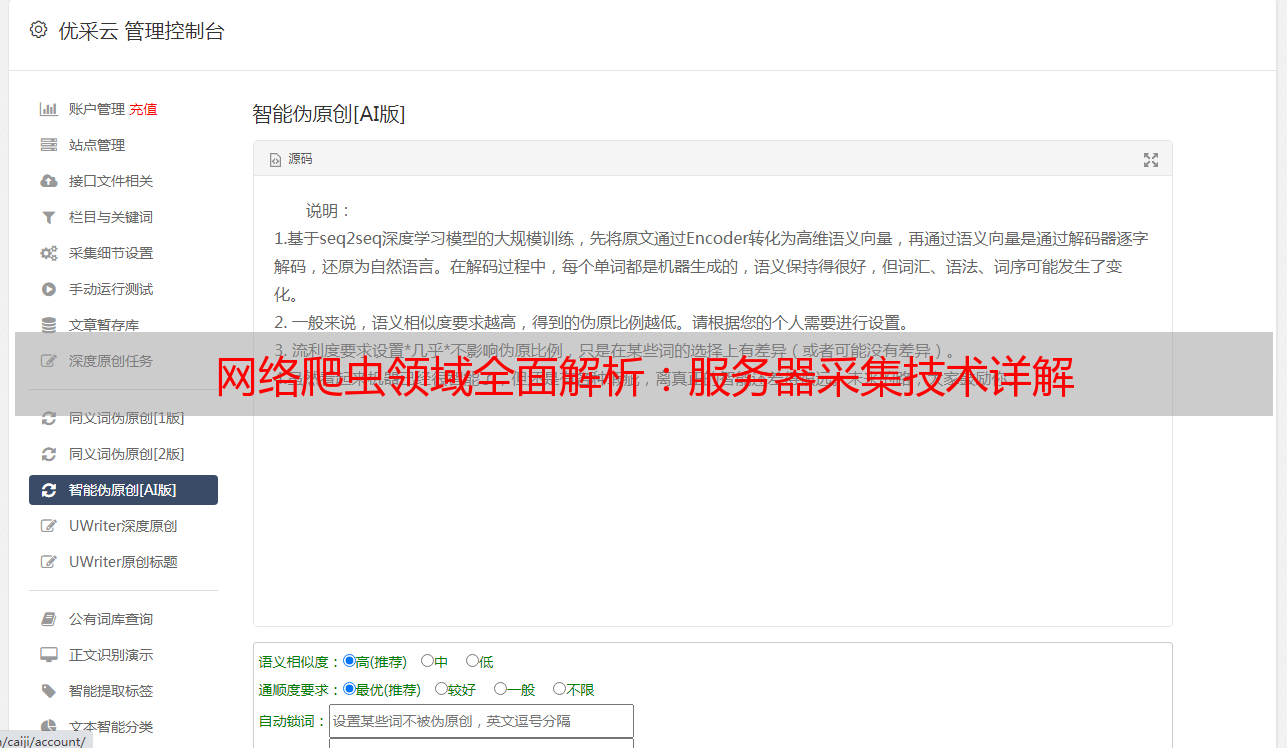
优采云是一款专业的网络数据采集与处理平台。基于先进的AI技术和多年经验积累,提供高效稳定的数据抓取服务,并支持海量数据存储和处理。同时还提供SEO优化服务,帮助企业快速提升网站排名和流量。
七、优采云平台如何使用服务器采集技术实现数据抓取?
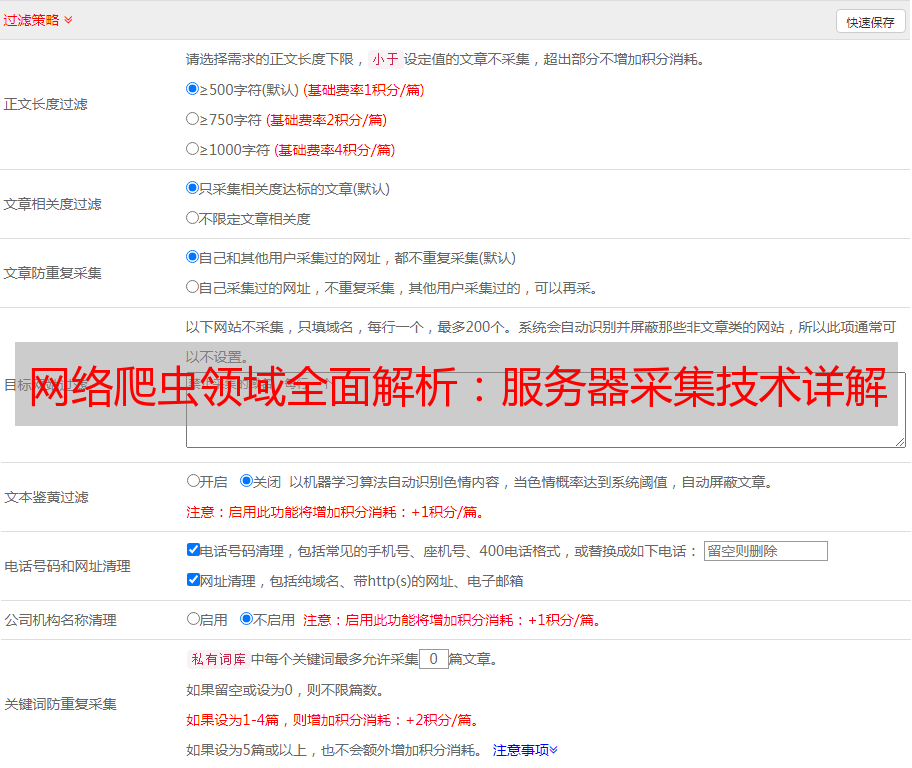
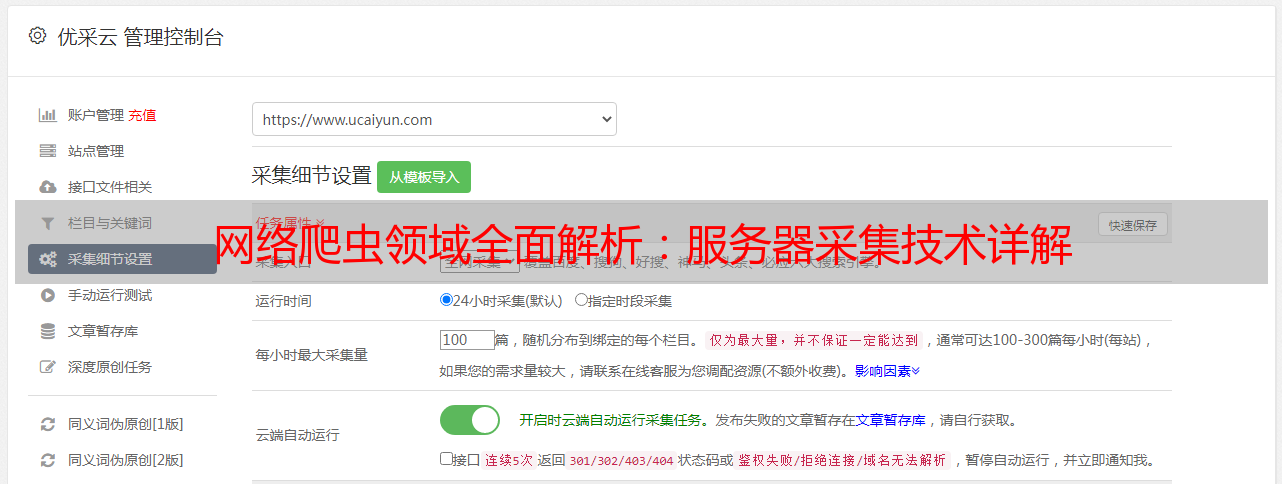
使用优采云平台可以轻松实现基于服务器采集技术的数据抓取服务。只需按照以下步骤即可完成:
1.登录优采云平台;
2.配置任务参数;
3.启动任务执行;
4.获取抓取结果。
八、优采云平台如何保证数据安全性?
优采云平台对数据安全性具有高度保障措施:
1.数据加密:对敏感数据进行加密处理;
2.权限管理:设立不同权限角色,并对不同角色进行限制;
3.安全日志:记录管理员操作日志,并定期检查安全问题;
4.审计追踪:记录系统所有操作日志,并保存备份。
九、结论与展望
本文从原理到实践详细介绍了服务器采集技术及其应用场景,在此基础上介绍了优采云平台如何使用该技术实现数据抓取,并说明了该平台如何保证数据安全性。未来随着AI技术和大数据分析能力不断提升,服务器采集技术将会得到更广泛深入地应用。www.ucaiyun.

