探索搜索引擎爬虫的神秘:10种浏览网页的方式解析
优采云 发布时间: 2023-03-18 22:20搜索引擎是我们日常生活中必不可少的工具,而搜索引擎爬虫则是实现搜索引擎功能的重要组成部分。那么,搜索引擎爬虫是如何工作的呢?本文将从10个方面逐步分析讨论搜索引擎爬虫的奥秘。
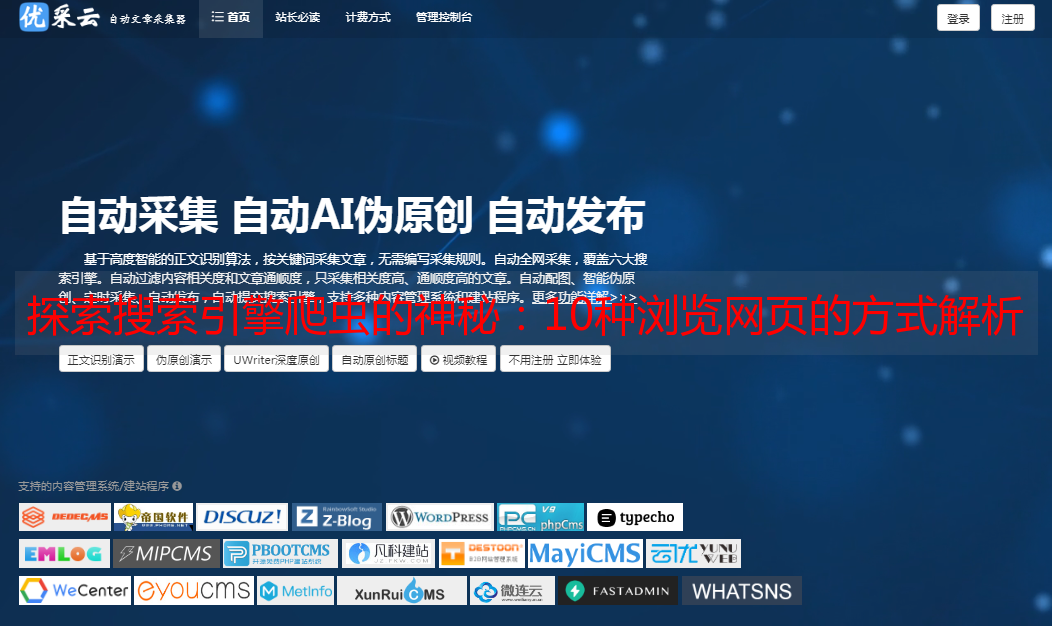
1.爬虫的定义和原理
搜索引擎爬虫,也称网络蜘蛛、网络机器人等,是一种自动化程序,可以按照一定规则自动地浏览互联网上的网页并抓取其中的信息。其原理是通过HTTP协议向目标网站发送请求,并解析返回的HTML文件,从中获取所需内容。
2.爬虫的分类
根据不同的应用场景和目标网站类型,可以将搜索引擎爬虫分为通用爬虫和垂直爬虫两类。通用爬虫主要用于抓取互联网上大量的网页信息,如Google、百度等;而垂直爬虫则针对特定领域或行业进行深度挖掘,如汽车之家、新浪体育等。
3.爬虫的工作流程
搜索引擎爬虫一般按照“发现-抓取-处理”三个步骤进行工作。首先通过*敏*感*词*URL发现新网页,再根据预设规则对网页进行抓取,并进行页面内容提取、链接识别等处理操作。
4.爬虫的限制与反制
为了保护网站安全和保密性,很多网站会设置robots.txt文件来指定哪些页面可以被搜索引擎爬虫抓取。此外还有一些反爬策略,如IP封禁、验证码识别等。
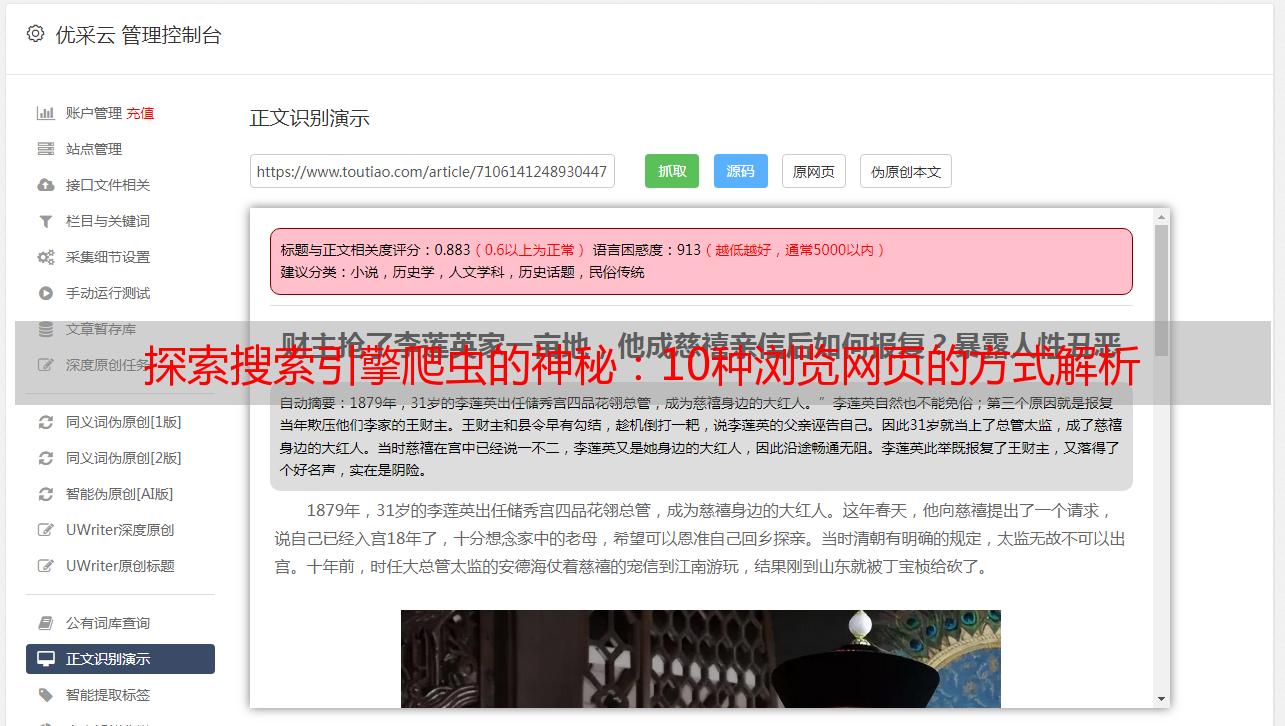
5.爬虫的性能优化
为了提高搜索引擎的效率和准确性,需要对搜索引擎爬虫进行性能优化。常见方法包括多线程并发抓取、增量式抓取、去重处理等。
6.爬虫与SEO优化
搜索引擎优化(SEO)是指通过优化网站结构和内容来提高网站在搜索引擎中排名。而在SEO过程中,搜索引擎爬虫则扮演着至关重要的角色。合理地设计网站结构和内容可以更好地满足搜索引擎爬虫的需求,从而提高网站排名。
7.爬虫与反作弊机制
为了防止恶意行为和欺诈行为影响搜索结果,在搜索引擎中还设置了反作弊机制。这些机制包括基于链接分析算法的PageRank算法、基于用户行为模式分析的TrustRank算法等。
8.爬虫与大数据分析
随着互联网信息量不断增大,传统数据处理方式已经无法满足需求。而利用搜索引擎爬虫采集数据并进行大数据分析,则成为了一种新型方法。通过对海量数据进行挖掘和分析可以更好地发现用户需求和市场趋势。
9.爬虫与人工智能技术
人工智能技术已经开始应用于搜索引擎领域,并与搜索引擎爬虫相结合产生出了新型产品。例如,基于深度学习技术训练出来的图像识别模型可以帮助爬虫更好地识别图片内容。
10.未来发展趋势
随着人工智能技术不断发展以及互联网信息量不断增加,未来搜索引擎爬虫将会面临更多挑战和机遇。例如,在语音识别技术广泛应用后,可能会出现基于语音交互方式进行信息检索和抽取的新型爬虫产品。
总之,在当今信息时代中,搜索引擎已经成为了人们获取信息最便捷快速的途径之一。而在这背后,则有着众多默默耕耘在网络深处、日夜不停地进行数据采集与处理工作的“蜘蛛们”。正是由于这些“蜘蛛”的辛勤付出,才让我们在浩瀚无垠的互联网海洋中迅速找到所需信息。

