如何全面抓取网站资源?应对网络信息爆炸时代的挑战!
优采云 发布时间: 2023-03-17 22:18在网络信息爆炸的时代,获取网站数据是信息工作者必备的技能之一。那么,如何从网站中抓取所有资源呢?本文将从以下8个方面进行详细讨论。
第一步:确定目标网站和规则
首先需要确定目标网站和规则,即需要获取哪些数据以及如何获取。可以通过浏览器开发者工具(F12)查看目标网站的源代码,找到所需数据的标签、类名等。
第二步:选择合适的工具
选择合适的抓取工具非常重要。常见的工具有Python爬虫框架Scrapy、Node.js框架Puppeteer等。这些工具都有各自的优缺点,需要根据实际情况进行选择。
第三步:编写抓取代码
根据所选工具编写代码,实现对目标网站数据的抓取。这里以Scrapy为例:
python
import scrapy
class MySpider(scrapy.Spider):
name ='myspider'
start_urls =['http://example.com']
def parse(self, response):
#解析页面内容并提取所需数据
pass
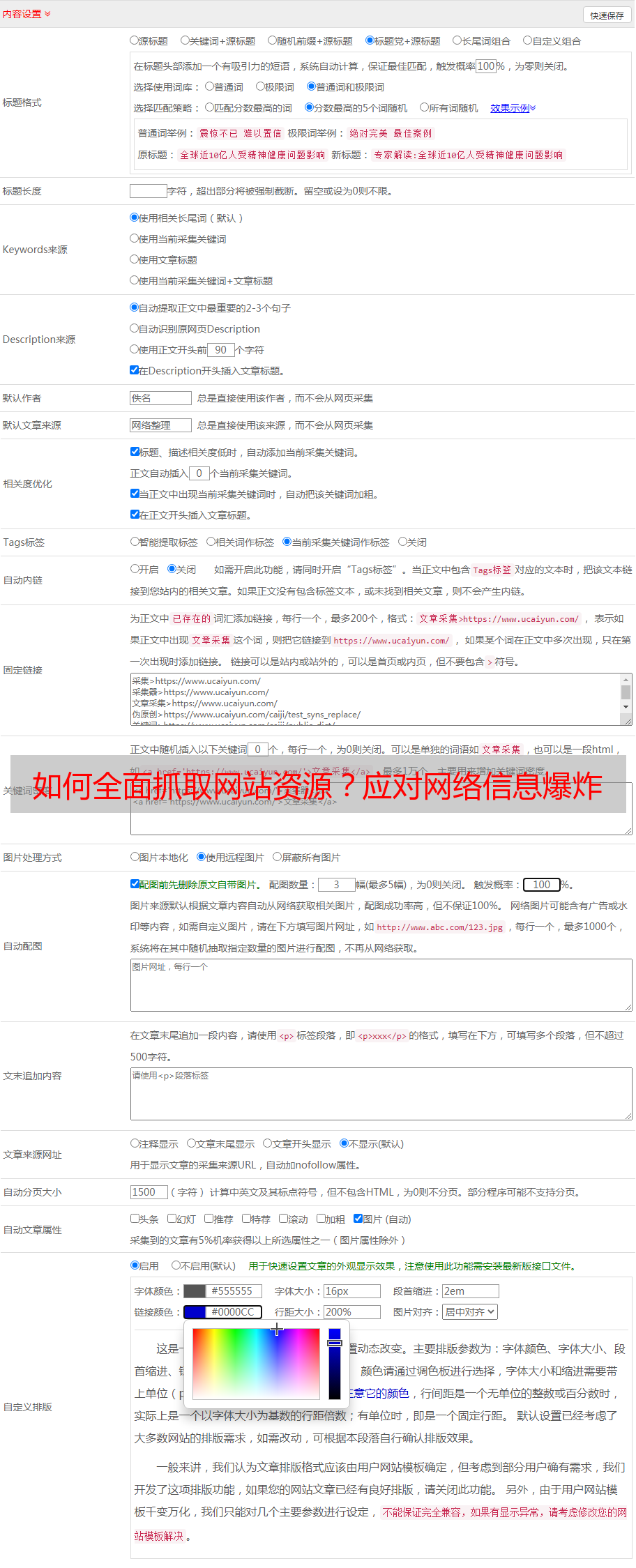
第四步:设置请求头和代理IP
为了避免被目标网站识别出来并封禁IP地址,需要设置合适的请求头和使用代理IP。
python
class MySpider(scrapy.Spider):
name ='myspider'
start_urls =['http://example.com']
custom_settings ={
'USER_AGENT':'Mozilla/5.0(Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'DOWNLOADER_4eccf537ac75b395a680631a66357e6c':{
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
'scrapy_fake_useragent.middleware.RandomUserAgentMiddleware': 400,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': None,
'scrapy_proxies.RandomProxy': 100,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 110,
},
'PROXY_LIST':'/path/to/proxy/list.txt',
'PROXY_MODE':0,
}
def parse(self, response):
#解析页面内容并提取所需数据
pass
第五步:处理反爬机制
为了防止被反爬机制识别出来并封禁IP地址,需要处理反爬机制。常见的反爬机制有验证码、IP封禁、限速等。
第六步:存储数据
将抓取到的数据存储到数据库或文件中。常见的存储方式有MySQL、MongoDB、CSV等。
第七步:定时任务
如果需要定时抓取数据,则可以使用Python库APScheduler实现定时任务。
python
from apscheduler.schedulers.background import BackgroundScheduler
scheduler = BackgroundScheduler()
scheduler.add_job(func=my_spider.run, trigger='interval', hours=1)
scheduler.start()
第八步:SEO优化
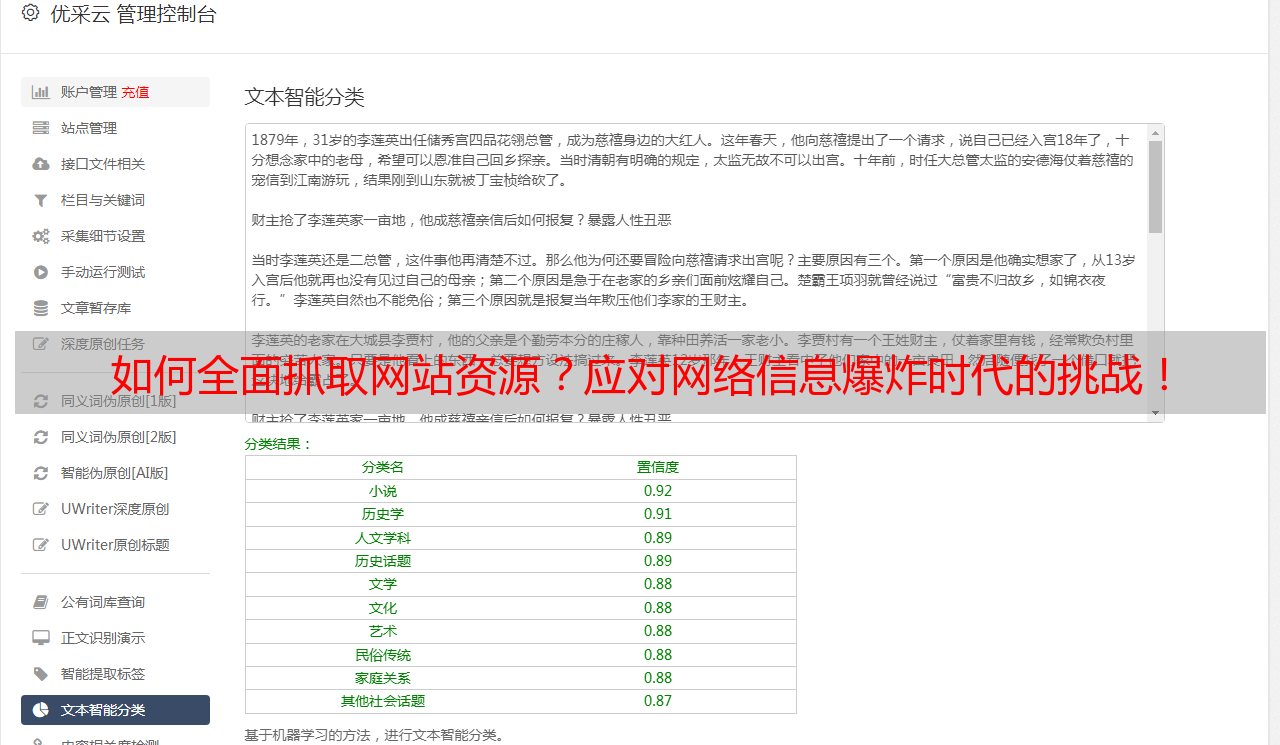
为了使抓取到的数据更好地被搜索引擎收录和展示,需要进行SEO优化。常见的SEO优化方式包括关键词优化、标题优化、内链外链等。
以上就是获取网站所有资源的详细步骤。希望本文对您有所帮助。更多关于SEO优化和网络爬虫方面的知识,请关注优采云(www.ucaiyun.com)。

