轻松获取新闻内容,Web Scraper教程来了!
优采云 发布时间: 2023-03-17 18:16Web Scraper 是一种用于从网站中收集信息的工具,它可以自动化执行这项任务,从而使您的信息获取过程更加高效。在本文中,我们将介绍 Web Scraper 的基本原理和使用方法,并讨论它在新闻采集方面的应用。
1.什么是 Web Scraper?
Web Scraper 是一种自动化工具,它可以帮助用户从网站上收集数据。通过指定一些规则和条件,Web Scraper 可以自动访问网站,并提取出用户需要的数据。这些规则和条件通常包括选择器、正则表达式等。
2.如何使用 Web Scraper?
使用 Web Scraper 需要编写一些代码,但是不需要编写太多复杂的代码。下面是一个简单的 Web Scraper 代码示例:
from bs4 import BeautifulSoup
import requests
url ='https://www.example.com'
response = requests.get(url)
soup = BeautifulSoup(response.content,'html.parser')
title = soup.find('h1').text
content = soup.find('div',{'class':'content'}).text
print(title)
print(content)
在这个示例中,我们使用了 Python 的 BeautifulSoup 库来解析网页内容,并使用了 requests 库来获取网页内容。我们首先指定了要抓取的网页 URL,在得到响应后,我们使用 BeautifulSoup 来解析 HTML 内容。然后我们使用 find 方法来查找标题和内容。最后,将标题和内容打印出来。
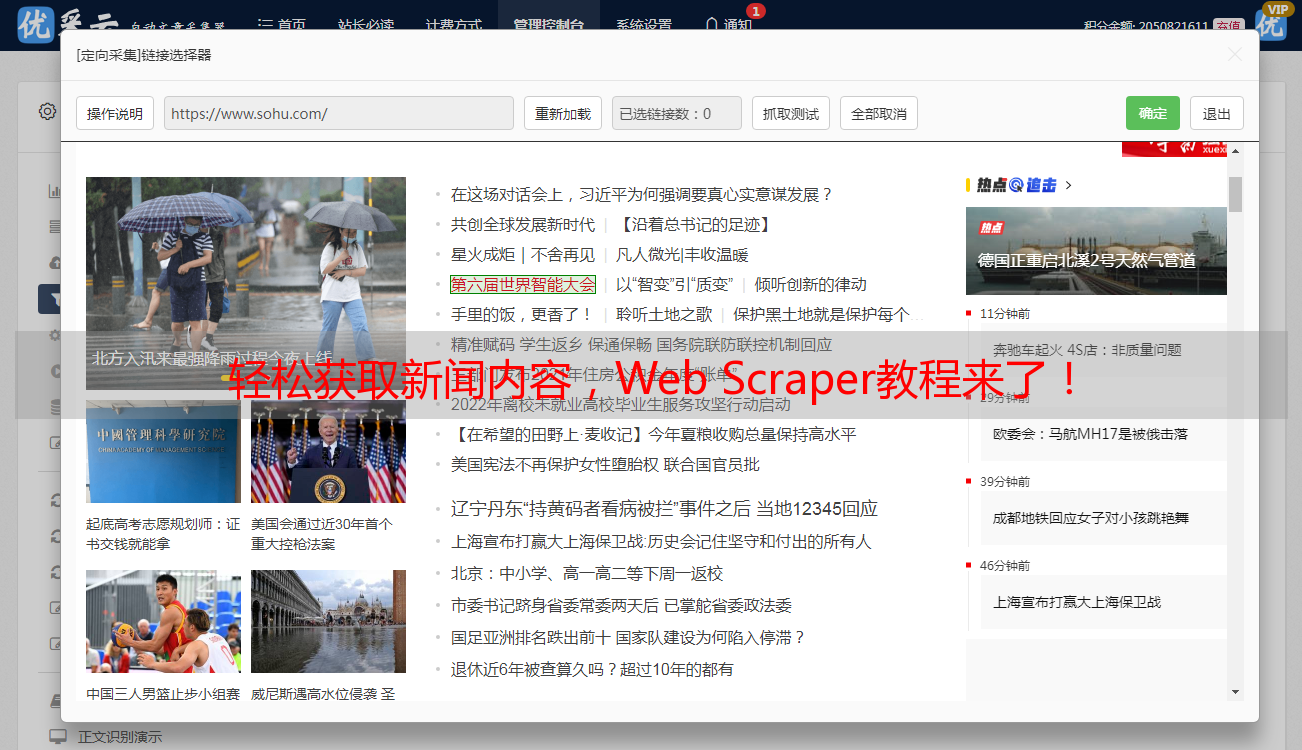
3.如何采集新闻内容?
使用 Web Scraper 采集新闻内容需要先确定要采集的新闻来源网站,并分析该网站页面结构和数据格式。然后根据分析结果编写相应的代码。
例如,如果要从某个新闻门户网站上采集新闻内容,可以通过分析网站页面结构和数据格式来确定要采集的数据类型(如标题、正文、发布日期等)。然后可以使用类似上述代码示例中的方式来提取这些数据。
4. Web Scraper 的优缺点是什么?
Web Scraper 的优点是可以自动化执行数据采集任务,并且速度较快。同时,Web Scraper 可以在不需要人工干预的情况下执行操作,并且可以处理大量数据。
但是,Web Scraper 也存在一些缺点。首先,如果没有正确设置规则和条件,则可能会导致数据提取错误或者漏掉一些数据。其次,在某些情况下,由于页面结构或者反爬虫机制等问题,Web Scraper 可能无法正常提取数据。
5.怎样避免被反爬虫机制封禁?
为了避免被反爬虫机制封禁,可以考虑以下几个方面:
-设置合理的 User-Agent 和 Referer;
-控制访问频率;
-使用代理 IP;
-模拟人工操作。
6.怎样进行 SEO 优化?
为了进行 SEO 优化,可以考虑以下几个方面:
-确定关键词;
-提高页面质量;
-增加外部链接;
-提高页面加载速度;
-发布高质量内容。
7.优采云对 Web Scraping 的支持
优采云是一个功能强大的云端爬虫平台,在 Web Scraping 方面提供了全方位的支持。优采云提供了丰富的模板库和 API 接口,可帮助用户快速开发出符合需求的定制化爬虫。同时,优采云还提供了多种存储方式和数据处理功能,使用户能够轻松地管理和分析所采集到的数据。
8.总结
本文介绍了 Web Scraper 的基本原理和使用方法,并探讨了它在新闻采集方面的应用。除此之外,还介绍了如何避免被反爬虫机制封禁、如何进行 SEO 优化以及优采云对 Web Scraping 的支持等相关知识点。希望本文对您有所帮助!

