爬虫引擎驱动的数据采集系统解决方案,高效稳定采集数据
优采云 发布时间: 2023-03-17 02:11今天,我们将为大家介绍一种高效的数据采集系统解决方案——爬虫引擎。无论是大型企业还是小型创业公司,都需要获取各种各样的数据来进行分析和应用。而如何快速、高效地获取这些数据,成为了企业面临的一个重要问题。本文将从以下10个方面进行详细分析讨论。
1.爬虫引擎的基本原理
2.爬虫引擎的分类及应用场景
3.爬虫引擎的工作流程
4.爬虫引擎与反爬机制的斗争
5.数据清洗与预处理
6.数据存储与管理
7.数据分析与挖掘
8.爬虫引擎在电商领域中的应用
9.爬虫引擎在金融领域中的应用
10.爬虫引擎在搜索引擎优化(SEO)中的应用
爬虫引擎是一种基于网络爬虫技术实现的数据采集系统。它通过模拟人工浏览器行为,自动化地访问网页、提取数据,并将数据进行清洗、处理、存储和分析,最终生成有价值的信息产品。根据不同的应用场景和需求,可以选择不同类型的爬虫引擎,例如通用爬虫、聚焦爬虫、深度爬虫等。
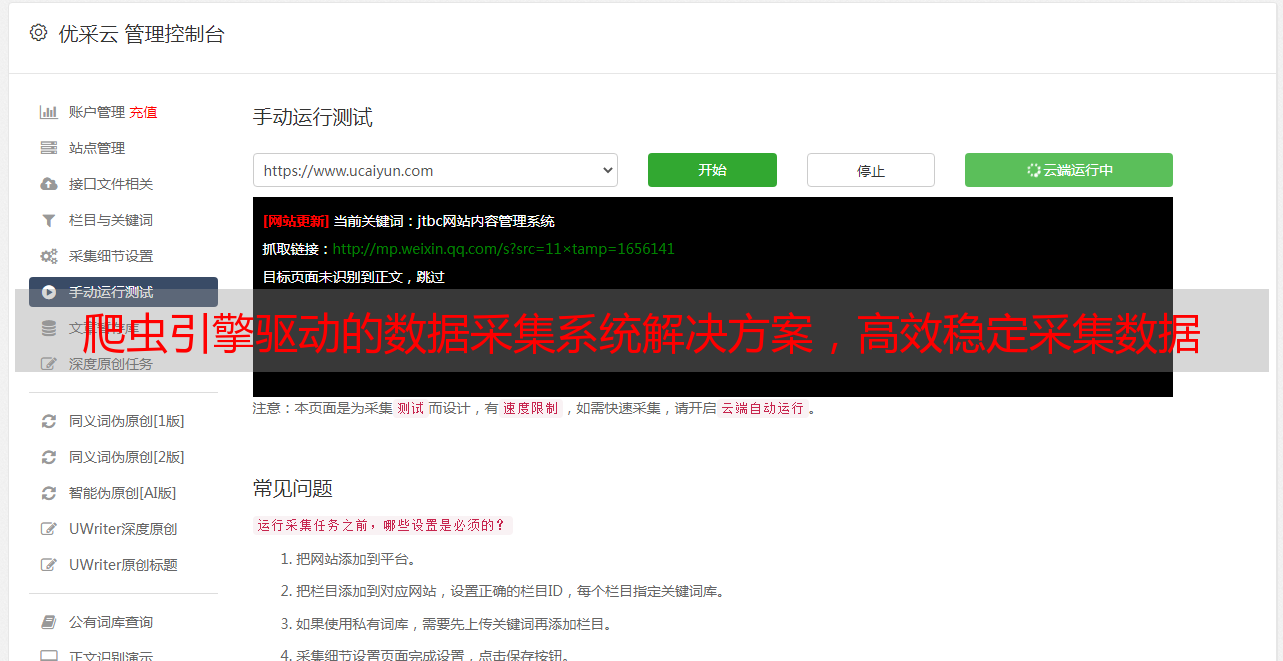
具体而言,爬虫引擎主要包括以下几个步骤:首先确定目标网站,然后根据目标网站的结构和特点编写相应的爬虫程序;程序运行时,模拟人工浏览器行为,发送请求、解析HTML代码并提取目标信息;接着对采集到的数据进行清洗、去重、筛选等处理;最后将处理后的数据存储到数据库或文件中,并进行进一步分析和挖掘。
然而,在实际操作中,往往会遇到各种反爬机制。例如IP限制、验证码识别、页面渲染等问题。针对这些问题,可以采用代理IP池、OCR识别技术、浏览器自动化等手段来规避或突破反爬机制。
除了解决反爬机制问题外,在进行数据采集时还需要注意数据清洗和预处理。这一步骤非常关键,因为原始数据往往存在噪声和异常值等问题,需要进行去重、过滤和格式化等操作。同时,在预处理阶段也可以结合自然语言处理(NLP)技术对文本信息进行分词、情感分析等操作。
当然,在完成数据采集和预处理后,还需要对数据进行存储和管理。这里可以选择传统关系型数据库或NoSQL数据库来存储不同类型的数据,并使用相应的管理工具来保证数据安全性和完整性。
除了以上几个方面外,在电商领域中,可以利用爬虫引擎来获取竞品价格信息、用户评价等关键信息来优化产品定价策略;在金融领域中,则可以利用爬虫引擎来获取股票行情信息、舆情监测等关键信息来辅助投资决策。同时,在搜索引擎优化(SEO)方面也可以利用爬虫技术来获取关键词排名信息以及竞争者网站结构等信息来优化网站SEO策略。
总之,随着大数据时代的到来,企业需要更加高效地获取海量有价值的信息来支持业务发展。而爬虫引擎作为一种高效可靠的数据采集系统解决方案,在未来也将得到更广泛地应用。

